Can synthetic data reproduce real-world findings in epidemiology? A replication study using adversarial random forests
Pith reviewed 2026-05-18 22:18 UTC · model grok-4.3
The pith
Synthetic data from adversarial random forests reproduces findings from real epidemiological studies
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Adversarial random forests generate synthetic versions of epidemiological datasets that allow replication of descriptive and inferential statistical analyses from original publications, with results aligning consistently across the tested studies even when sample sizes are small relative to dimensionality.
What carries the argument
Adversarial random forests, which use an adversarial training process with random forests to create synthetic tabular data that maintains statistical properties of the original data.
If this is right
- Analyses can be performed on synthetic data without compromising participant privacy in large cohort studies.
- Findings from published research can be verified or extended using accessible synthetic datasets.
- Data synthesis becomes more practical for non-experts due to the method's computational efficiency.
- Quality improves with reduced data dimensionality, pointing to benefits of variable selection before synthesis.
Where Pith is reading between the lines
- If the alignment holds for more complex causal models, synthetic data could support a wider range of research questions beyond simple associations.
- Public release of synthetic cohort data might accelerate collaborative research while meeting ethical standards.
- Comparisons suggest this method could be adapted for other tabular data domains with similar privacy needs.
Load-bearing premise
Alignment of results on the selected analyses from these six publications is enough to indicate that synthetic data can reproduce key findings in epidemiological research more generally.
What would settle it
Finding a new study or analysis type where the conclusions drawn from synthetic data differ substantially from those based on the original data would challenge the reliability claim.
Figures


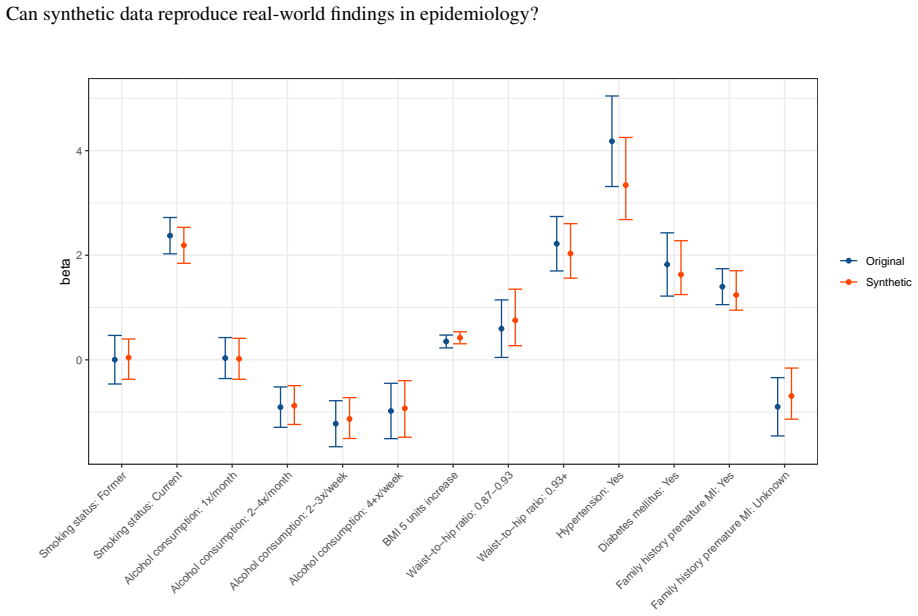



read the original abstract
Synthetic data holds substantial potential to address practical challenges in epidemiology due to restricted data access and privacy concerns. However, many current methods suffer from limited quality, high computational demands, and complexity for non-experts. Furthermore, common evaluation strategies for synthetic data often fail to directly reflect statistical utility and measure privacy risks sufficiently. Against this background, a critical underexplored question is whether synthetic data can reliably reproduce key findings from epidemiological research while preserving privacy. We propose adversarial random forests (ARF) as an efficient and convenient method for synthesizing tabular epidemiological data. To evaluate its performance, we replicated statistical analyses from six epidemiological publications covering blood pressure, anthropometry, myocardial infarction, accelerometry, loneliness, and diabetes, from the German National Cohort (NAKO Gesundheitsstudie), the Bremen STEMI Registry U45 Study, and the Guelph Family Health Study. We further assessed how dataset dimensionality and variable complexity affect the quality of synthetic data, and contextualized ARF's performance by comparison with commonly used tabular data synthesizers in terms of utility, privacy, generalisation, and runtime. Across all replicated studies, results on ARF-generated synthetic data consistently aligned with original findings. Even for datasets with relatively low sample size-to-dimensionality ratios, replication outcomes closely matched the original results across descriptive and inferential analyses. Reduced dimensionality and variable complexity further enhanced synthesis quality. ARF demonstrated favourable performance regarding utility, privacy preservation, and generalisation relative to other synthesizers and superior computational efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that adversarial random forests (ARF) provide an efficient method for generating synthetic tabular epidemiological data that preserves privacy while reproducing key findings from real-world studies. The authors replicate descriptive and inferential analyses from six publications using data from the German National Cohort (NAKO), Bremen STEMI Registry U45 Study, and Guelph Family Health Study. They report consistent alignment between original and ARF-synthetic results across these studies, even in low sample-size-to-dimensionality regimes, with reduced dimensionality improving quality, and ARF outperforming other synthesizers on utility, privacy, generalization, and runtime.
Significance. If the central claim holds, the work would be significant for epidemiology and synthetic data research by offering empirical evidence that a computationally efficient, accessible method can support real research questions under privacy constraints. The replication design using actual published analyses is a strength over purely metric-based evaluations, and the multi-cohort, multi-study scope plus baseline comparisons add practical value.
major comments (2)
- [Abstract and Results] Abstract and Results: The claims that results 'consistently aligned with original findings' and 'closely matched' lack any quantitative support such as effect-size differences, equivalence tests, or agreement statistics between original and synthetic outputs. Without these, the degree of fidelity cannot be assessed rigorously, especially for inferential statistics where small shifts may change conclusions.
- [Evaluation and Discussion] Evaluation and Discussion: The manuscript tests only the specific descriptive and inferential analyses pre-selected from the six publications. This does not establish that the synthetic data preserves the joint distributions, conditional dependencies, or tail behavior needed for untested epidemiological questions; additional held-out analyses or dependency checks would be required to support the broader generalization claim.
minor comments (3)
- [Methods] Methods: Include implementation details for ARF (hyperparameters, training procedure) and how post-hoc analysis choices from the original papers were made to support reproducibility and reduce selection concerns.
- [Results] Figures: Add error bars, confidence intervals, or quantitative difference metrics to plots comparing original versus synthetic results to make alignment visually and quantitatively clearer.
- [Introduction] Introduction: Provide a short description or key reference for adversarial random forests to aid readers unfamiliar with the technique.
Simulated Author's Rebuttal
We thank the referee for the constructive comments that highlight opportunities to strengthen the quantitative rigor and scope of our claims. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract and Results] Abstract and Results: The claims that results 'consistently aligned with original findings' and 'closely matched' lack any quantitative support such as effect-size differences, equivalence tests, or agreement statistics between original and synthetic outputs. Without these, the degree of fidelity cannot be assessed rigorously, especially for inferential statistics where small shifts may change conclusions.
Authors: We agree that the manuscript would benefit from explicit quantitative comparisons. In the revised version we will add tables reporting relative differences (in percent) for all key descriptive statistics and effect estimates, absolute differences in p-values, and, where appropriate, equivalence testing bounds for the inferential results. These additions will allow readers to judge the practical magnitude of any discrepancies. revision: yes
-
Referee: [Evaluation and Discussion] Evaluation and Discussion: The manuscript tests only the specific descriptive and inferential analyses pre-selected from the six publications. This does not establish that the synthetic data preserves the joint distributions, conditional dependencies, or tail behavior needed for untested epidemiological questions; additional held-out analyses or dependency checks would be required to support the broader generalization claim.
Authors: The central objective of the study is to evaluate whether synthetic data can reproduce the specific published findings that motivated the original analyses, not to certify the data for arbitrary downstream questions. Because the six replication targets were chosen precisely because they represent the primary scientific conclusions drawn from each cohort, successful reproduction directly addresses the paper’s research question. We will nevertheless revise the Discussion to (i) explicitly delimit the scope of our claims to reproduction of reported findings and (ii) acknowledge that broader utility for novel analyses would require additional validation. If space allows, we will also report pairwise correlation matrices or mutual-information summaries as a supplementary check on dependency preservation. revision: partial
Circularity Check
No circularity: empirical replication against external benchmarks
full rationale
This is an empirical replication study that applies ARF to generate synthetic versions of real epidemiological datasets and directly compares descriptive and inferential results on the synthetic data against the published findings from six independent external studies. No equations, fitted parameters, or derivations are present that reduce to the paper's own inputs by construction. The evaluation relies on external original results as the benchmark, satisfying the criterion for self-contained evidence against external benchmarks. Any citations to the ARF method itself are not load-bearing for the replication claim and do not create a self-referential loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Synthetic data that matches selected descriptive and inferential statistics will support reliable epidemiological conclusions in general.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose the use of adversarial random forests (ARF) as an efficient and convenient method for synthesizing tabular epidemiological data... replicated statistical analyses from six epidemiological publications
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ARF utilises random forests (RFs) as its foundation. It iteratively learns data dependencies... variable-wise univariate density estimation within the partitioning units
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
HIPAA privacy rule and public health; guidance from CDC and the U.S
Centers for Disease Control and Prevention (U.S.). HIPAA privacy rule and public health; guidance from CDC and the U.S. Department of Health and Human Services, 2003. https://stacks.cdc.gov/view/cdc/12138 (30 July 2025, date last accessed)
work page 2003
-
[2]
Regulation (EU) 2016/679 of the European Parliament and of the Council, 2016
European Parliament and Council of the European Union. Regulation (EU) 2016/679 of the European Parliament and of the Council, 2016. https://eur-lex.europa.eu/eli/reg/2016/679/oj (30 July 2025, date last accessed)
work page 2016
-
[3]
David Foster. Generative deep learning. O’Reilly Media, Sebastopol, 2022
work page 2022
-
[4]
OpenAI. ChatGPT. https://openai.com/chatgpt (30 July 2025, date last accessed)
work page 2025
-
[5]
OpenAI. DALL·E. https://openai.com/dall-e (30 July 2025, date last accessed)
work page 2025
-
[6]
Synthetic data in biomedicine via generative artificial intelligence
Boris van Breugel, Tennison Liu, Dino Oglic, and Mihaela van der Schaar. Synthetic data in biomedicine via generative artificial intelligence. Nat Rev Bioeng, 2:991–1004, 2024
work page 2024
-
[7]
Synthetic data—what, why and how? Royal Society,
James Jordon, Lukasz Szpruch, Florimond Houssiau, Mirko Bottarelli, Giovanni Cherubin, Carsten Maple, Samuel N Cohen, and Adrian Weller. Synthetic data—what, why and how? Royal Society,
-
[8]
https://royalsociety.org/-/media/policy/projects/privacy-enhancing-technologies/ Synthetic_Data_Survey-24.pdf (30 July 2025, date last accessed)
work page 2025
-
[9]
Jiwoong J Jeong, Amara Tariq, Tobiloba Adejumo, Hari Trivedi, Judy W Gichoya, and Imon Banerjee. Sys- tematic review of generative adversarial networks (GANs) for medical image classification and segmentation. J Digit Imaging, 35(2):137–152, 2022
work page 2022
-
[10]
Diffusion models in medical imaging: a comprehensive survey
Amirhossein Kazerouni, Ehsan Khodapanah Aghdam, Moein Heidari, Reza Azad, Mohsen Fayyaz, Ilker Haci- haliloglu, and Dorit Merhof. Diffusion models in medical imaging: a comprehensive survey. Med Image Anal, 88:e102846, 2023
work page 2023
-
[11]
Navigating tabular data synthesis research understanding user needs and tool capabilities
Maria F Davila R, Sven Groen, Fabian Panse, and Wolfram Wingerath. Navigating tabular data synthesis research understanding user needs and tool capabilities. SIGMOD Rec, 53(4):18–35, 2025
work page 2025
-
[12]
An evaluation of synthetic data generators implemented in the python library synthcity
Emma F ¨ossing and J¨org Drechsler. An evaluation of synthetic data generators implemented in the python library synthcity. In Priv Stat Databases, volume 14915 of LNCS, pages 178–193, 2024
work page 2024
-
[13]
A note on the evaluation of generative models
L Theis, A van den Oord, and M Bethge. A note on the evaluation of generative models. ICLR, 2016
work page 2016
-
[14]
Tabular data generation: can we fool XGBoost? NeurIPS 2022 First Table Representation Workshop, 2022
EL Hacen Zein and Tanguy Urvoy. Tabular data generation: can we fool XGBoost? NeurIPS 2022 First Table Representation Workshop, 2022
work page 2022
-
[15]
Lisa K ¨uhnel, Julian Schneider, Ines Perrar, Tim Adams, Sobhan Moazemi, Fabian Prasser, Ute N¨othlings, Holger Fr¨ohlich, and Juliane Fluck. Synthetic data generation for a longitudinal cohort study—evaluation, method extension and reproduction of published data analysis results. Sci Rep, 14(1):e14412, 2024. 12 Can synthetic data reproduce real-world fin...
work page 2024
-
[16]
An evaluation of the replicability of analyses using synthetic health data
Khaled El Emam, Lucy Mosquera, Xi Fang, and Alaa El-Hussuna. An evaluation of the replicability of analyses using synthetic health data. Sci Rep, 14(1):e6978, 2024
work page 2024
-
[17]
Adversarial random forests for density estimation and generative modeling
David S Watson, Kristin Blesch, Jan Kapar, and Marvin N Wright. Adversarial random forests for density estimation and generative modeling. In AISTATS, volume 206 of PMLR, pages 5357–5375, 2023
work page 2023
-
[18]
Marvin N. Wright, David S. Watson, Kristin Blesch, and Jan Kapar. arf: adversarial random forests. CRAN,
-
[19]
https://CRAN.R-project.org/package=arf (30 July 2025, date last accessed)
work page 2025
-
[20]
Synthcity: a benchmark framework for diverse use cases of tabular synthetic data
Zhaozhi Qian, Rob Davis, and Mihaela van der Schaar. Synthcity: a benchmark framework for diverse use cases of tabular synthetic data. Adv Neural Inf Process Syst, 36:3173–3188, 2023
work page 2023
-
[21]
Tamara Schikowski, Claudia Wigmann, Kateryna B Fuks, Sabine Schipf, Margit Heier, Hannelore Neuhauser, Giselle Sarganas, Wolfgang Ahrens, Heiko Becher, Klaus Berger, et al. Blutdruckmessung in der NAKO— methodische Unterschiede, Blutdruckverteilung und Bekanntheit der Hypertonie im Vergleich zu anderen bev¨olkerungsbezogenen Studien in Deutschland [Blood ...
work page 2020
-
[22]
Beate Fischer, Anja M Sedlmeier, Saskia Hartwig, Christopher L Schlett, Wolfgang Ahrens, Fabian Bamberg, Hansj¨org Baurecht, Heiko Becher, Klaus Berger, Hans Binder, et al. Anthropometrische Messungen in der NAKO Gesundheitsstudie—mehr als nur Gr ¨oße und Gewicht [Anthropometric measures in the German Na- tional Cohort—more than weight and height]. Bundes...
work page 2020
-
[23]
Harm Wienbergen, Daniel Boakye, Kathrin G ¨unther, Johannes Schmucker, Luis Alberto Mata Mar ´ın, Hatim Kerniss, Rajini Nagrani, Luise Struß, Stephan R ¨uhle, Tina Retzlaff, et al. Lifestyle and metabolic risk factors in patients with early-onset myocardial infarction: a case-control study. Eur J Prev Cardiol, 29(16):2076–2087, 2022
work page 2076
-
[24]
ActiGraph cutpoints impact physical activity and sedentary behavior outcomes in young children
Becky Breau, Hannah J Coyle-Asbil, Jess Haines, David WL Ma, and Lori Ann Vallis. ActiGraph cutpoints impact physical activity and sedentary behavior outcomes in young children. J Meas Phys Behav , 5(2):85–96, 2022
work page 2022
-
[25]
Klaus Berger, Steffi Riedel-Heller, Alexander Pabst, Marcella Rietschel, Dirk Richter, and NAKO-Konsortium. Einsamkeit w ¨ahrend der ersten Welle der SARS-CoV-2-Pandemie—Ergebnisse der NAKO-Gesundheitsstudie [Loneliness during the first wave of the SARS-CoV-2 pandemic—results of the German National Cohort (NAKO)]. Bundesgesundheitsblatt, Gesundheitsforsch...
work page 2021
-
[26]
Justine Tanoey, Christina Baechle, Hermann Brenner, Andreas Deckert, Julia Fricke, Kathrin G ¨unther, Andr ´e Karch, Thomas Keil, Alexander Kluttig, Michael Leitzmann, et al. Birth order, caesarean section, or daycare attendance in relation to child-and adult-onset type 1 diabetes: results from the German National Cohort. Int J Environ Res Public Health, ...
work page 2022
-
[27]
Framework and baseline examination of the German National Cohort (NAKO)
Annette Peters and German National Cohort (NAKO) Consortium. Framework and baseline examination of the German National Cohort (NAKO). Eur J Epidemiol, 37(10):1107–1124, 2022
work page 2022
-
[28]
Guelph Family Health Study: pilot study of a home- based obesity prevention intervention
Jess Haines, Sabrina Douglas, Julia A Mirotta, Carley O’Kane, Rebecca Breau, Kathryn Walton, Owen Krystia, Elie Chamoun, Angela Annis, Gerarda A Darlington, et al. Guelph Family Health Study: pilot study of a home- based obesity prevention intervention. Can J Public Health, 109(4):549–560, 2018
work page 2018
-
[29]
Deep neural networks and tabular data: a survey
Vadim Borisov, Tobias Leemann, Kathrin Seßler, Johannes Haug, Martin Pawelczyk, and Gjergji Kasneci. Deep neural networks and tabular data: a survey. IEEE Trans Neural Netw Learn Syst, 35(6):7499–7519, 2022
work page 2022
-
[30]
Generating synthetic data is complicated: know your data and know your generator
Jonathan Latner, Marcel Neunhoeffer, and J ¨org Drechsler. Generating synthetic data is complicated: know your data and know your generator. In Priv Stat Databases, volume 14915 of LNCS, pages 115–128. Springer, 2024
work page 2024
-
[31]
J. Ross Quinlan. Induction of decision trees. Mach Learn, 1:81–106, 1986
work page 1986
-
[32]
L ´eo Grinsztajn, Edouard Oyallon, and Ga¨el Varoquaux. Why do tree-based models still outperform deep learning on typical tabular data? Adv Neural Inf Process Syst, 35:507–520, 2022
work page 2022
-
[33]
J ¨org Drechsler and Jerome P Reiter. An empirical evaluation of easily implemented, nonparametric methods for generating synthetic datasets. Comput Stat Data Anal, 55(12):3232–3243, 2011
work page 2011
- [34]
-
[35]
Herbert Robbins. Mixture of distributions. Ann Math Stat, 19(3):360–369, 1948
work page 1948
-
[36]
An introduction to the bootstrap
Bradley Efron and Robert J Tibshirani. An introduction to the bootstrap. Chapman and Hall/CRC, New York, 1994. 13 Can synthetic data reproduce real-world findings in epidemiology?
work page 1994
-
[37]
The PHQ-9: validity of a brief depression severity measure
Kurt Kroenke, Robert L Spitzer, and Janet BW Williams. The PHQ-9: validity of a brief depression severity measure. J Gen Intern Med, 16(9):606–613, 2001
work page 2001
-
[38]
A brief measure for assessing generalized anxiety disorder: the GAD-7
Robert L Spitzer, Kurt Kroenke, Janet BW Williams, and Bernd L¨owe. A brief measure for assessing generalized anxiety disorder: the GAD-7. Arch Intern Med, 166(10):1092–1097, 2006
work page 2006
-
[39]
Fairness without imputation: a decision tree approach for fair prediction with missing values
Haewon Jeong, Hao Wang, and Flavio P Calmon. Fairness without imputation: a decision tree approach for fair prediction with missing values. Proc AAAI Conf Artif Intell, 36(9):9558–9566, 2022
work page 2022
-
[40]
Missing value imputation with adversarial random forests—MissARF
Pegah Golchian, Jan Kapar, David S Watson, and Marvin N Wright. Missing value imputation with adversarial random forests—MissARF. arXiv. doi:10.48550/arXiv.2507.15681, 21 July 2025, preprint: not peer reviewed
-
[41]
Susanne Dandl, Kristin Blesch, Timo Freiesleben, Gunnar K ¨onig, Jan Kapar, Bernd Bischl, and Marvin N Wright. Countarfactuals—generating plausible model-agnostic counterfactual explanations with adversarial ran- dom forests. In Explainable Artificial Intelligence. xAI 2024 , volume 2155 of CCIS, pages 85–107. Springer, 2024
work page 2024
-
[42]
ML-Doctor: holistic risk assessment of inference attacks against machine learning models
Yugeng Liu, Rui Wen, Xinlei He, Ahmed Salem, Zhikun Zhang, Michael Backes, Emiliano De Cristofaro, Mario Fritz, and Yang Zhang. ML-Doctor: holistic risk assessment of inference attacks against machine learning models. In Proc USENIX Secur Symp, pages 4525–4542, 2022. 14 Can synthetic data reproduce real-world findings in epidemiology? A Replication result...
work page 2022
-
[43]
Median and percentile-based 95% confidence intervals of synthetic data results are printed in orange. PHQ-9, nine-item Patient Health Questionnaire; GAD-7, Generalized Anxiety Disorder seven-item scale; SD, standard deviation 37 Can synthetic data reproduce real-world findings in epidemiology? E.3 Full and task-specific dataset replication of multivariabl...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.