FediLoRA: Practical Federated Fine-Tuning of Foundation Models Under Missing-Modality Constraints
Pith reviewed 2026-05-21 21:53 UTC · model grok-4.3
The pith
FediLoRA enables federated fine-tuning of foundation models by handling missing modalities through averaging and editing of LoRA weights.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FediLoRA is a lightweight federated LoRA aggregation framework that effectively mitigates the impact of missing modalities in heterogeneous environments. It is motivated by the observation that simple averaging and structured editing can jointly benefit both global and personalized models, achieving strong performance across multiple general-domain and medical-domain benchmark datasets.
What carries the argument
A federated aggregation process for LoRA weights that combines simple averaging with structured editing to compensate for missing modalities and rank differences.
If this is right
- Strong performance is achieved on both general and medical benchmark datasets.
- The method supports practical deployment in real-world scenarios such as healthcare.
- Both the global model and personalized models see benefits from the approach.
- Challenges of imbalanced LoRA ranks and missing modalities are addressed simultaneously.
Where Pith is reading between the lines
- Similar averaging and editing strategies could be tested in other federated settings with incomplete sensor data or partial features.
- Future work might explore how the editing step scales with more extreme cases of modality absence.
- The framework could lower barriers for smaller institutions to participate in collaborative model training without full data availability.
Load-bearing premise
The assumption that averaging LoRA weights and then editing them in a structured way will reliably improve both shared and local models regardless of how the missing modalities are distributed or how much the ranks differ.
What would settle it
A test on a new collection of datasets with controlled but varied missing modality patterns where the proposed method shows no improvement over standard federated averaging would falsify the central performance claim.
Figures





read the original abstract
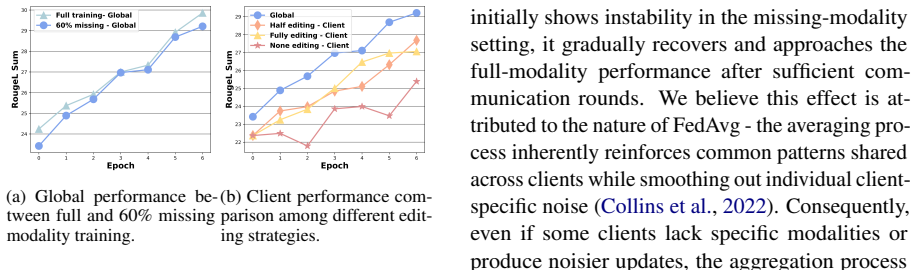
Federated Learning with LoRA fine-tuning offers an efficient and privacy-aware solution for institutions to collaboratively leverage their large datasets to train VLLMs. However, participating institutions often possess heterogeneous computational resources, resulting in imbalanced LoRA ranks, which pose a major challenge for effective collaboration. In addition, real-world applications in domains such as healthcare and transportation frequently suffer from missing modalities due to user mistakes or device failures, which significantly degrade global model performance in federated settings. To the best of our knowledge, no prior work has addressed these two challenges simultaneously in federated VLLMs. To tackle these issues, we propose FediLoRA, a lightweight federated LoRA aggregation framework that effectively mitigates the impact of missing modalities in heterogeneous environment. FediLoRA is explicitly motivated by the observation that simple averaging and structured editing can jointly benefit both global and personalized models. Our approach achieves strong performance across multiple general-domain and medical-domain benchmark datasets. Additional experiments on healthcare data further demonstrate that FediLoRA is well-suited for practical, real-world deployment scenarios. Our code is released at https://github.com/gotobcn8/FediLoRA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FediLoRA, a lightweight federated LoRA aggregation framework for fine-tuning vision-language foundation models. It targets two practical challenges: imbalanced LoRA ranks arising from heterogeneous client compute resources, and missing modalities caused by device failures or user errors. The method is motivated by the observation that simple averaging combined with structured editing of LoRA weights jointly improves both global and personalized models; the authors report strong empirical performance on general-domain and medical-domain benchmarks plus additional healthcare experiments, and release code.
Significance. If the central claims hold under broader conditions, the work is significant for enabling privacy-preserving collaborative training of large multimodal models in real-world heterogeneous settings such as healthcare. The explicit handling of both rank imbalance and missing modalities in a single lightweight framework, together with the open-source release, would provide a practical baseline for subsequent research. The approach does not introduce new theoretical machinery but demonstrates a pragmatic combination of existing ideas.
major comments (1)
- [4] The load-bearing claim that structured editing remains effective for arbitrary missing-modality patterns and unrestricted rank imbalances (abstract and motivation) is only partially supported if the experiments evaluate only a narrow set of fixed or benchmark-specific patterns. Section 4 (or the experimental evaluation) should include results that sample over a combinatorial space of missing-modality configurations and varying client ranks to confirm generalization; without such coverage the reported gains may not transfer to the heterogeneous VLLM scenarios emphasized in the introduction.
minor comments (2)
- [Related Work] The abstract states that 'no prior work has addressed these two challenges simultaneously'; the related-work section should provide a concise, explicit contrast with the closest federated LoRA and missing-modality papers to substantiate the novelty claim.
- Notation for the structured editing operation and the precise aggregation rule should be introduced with a short algorithm box or pseudocode for clarity.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback on our manuscript. We address the major comment below with clarifications on the scope of our experiments and a commitment to expand the evaluation for stronger generalization evidence.
read point-by-point responses
-
Referee: The load-bearing claim that structured editing remains effective for arbitrary missing-modality patterns and unrestricted rank imbalances (abstract and motivation) is only partially supported if the experiments evaluate only a narrow set of fixed or benchmark-specific patterns. Section 4 (or the experimental evaluation) should include results that sample over a combinatorial space of missing-modality configurations and varying client ranks to confirm generalization; without such coverage the reported gains may not transfer to the heterogeneous VLLM scenarios emphasized in the introduction.
Authors: We appreciate the referee's point on the need for broader coverage to support claims of effectiveness under heterogeneous conditions. Our current experiments in Section 4 evaluate FediLoRA across multiple benchmarks (general-domain datasets such as Flickr30K and COCO, plus medical-domain ones including MIMIC-CXR and CheXpert) with varying missing-modality rates (0-80% of clients affected) and heterogeneous LoRA ranks (e.g., client-specific ranks from 4 to 64). Missing patterns include both random per-client absences and modality-specific failures, with results averaged over multiple random seeds to capture variability. While we did not enumerate the full combinatorial space (which would be computationally prohibitive for large client counts), the tested settings reflect practical real-world heterogeneity in healthcare and other domains. To directly address the concern, we will revise Section 4 to include additional results systematically sampling a wider range of combinatorial missing-modality configurations (e.g., varying which subsets of modalities are absent across client groups) and more extreme rank imbalances. revision: yes
Circularity Check
No significant circularity; method is a new aggregation framework
full rationale
The paper proposes FediLoRA as a lightweight federated LoRA aggregation framework to handle imbalanced ranks and missing modalities in VLLMs. It is explicitly motivated by the observation that simple averaging and structured editing jointly benefit global and personalized models, but this serves as empirical motivation for the design rather than a mathematical derivation. No equations, fitted parameters, self-citation load-bearing premises, or uniqueness theorems are described in the abstract or claims that would reduce any prediction or result to the inputs by construction. Performance is evaluated on benchmark datasets, rendering the approach self-contained without circular reductions from result to input.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Armen Aghajanyan, Sonal Gupta, and Luke Zettlemoyer. 2021. Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning . In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (ACL/IJCNLP 2021), pages 7319--7328
work page 2021
-
[4]
Jiamu Bai, Daoyuan Chen, Bingchen Qian, Liuyi Yao, and Yaliang Li. 2024. Federated fine-tuning of large language models under heterogeneous tasks and client resources. In Proceedings of the Annual Conference on Neural Information Processing Systems 2024 (NeurIPS 2024)
work page 2024
- [5]
-
[6]
Yuji Byun and Jaeho Lee. 2025. Towards federated low-rank adaptation of language models with rank heterogeneity. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics - Volume 2: Short Papers (NAACL 2025), pages 356--362
work page 2025
-
[7]
Junsong Chen, Jincheng Yu, Chongjian Ge, Lewei Yao, Enze Xie, Yue Wu, Zhongdao Wang, James Kwok, Ping Luo, Huchuan Lu, and Zhenguo Li. 2023 a . https://arxiv.org/abs/2310.00426 Pixart- : Fast training of diffusion transformer for photorealistic text-to-image synthesis . Preprint, arXiv:2310.00426
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Qin Chen, Jianghao Yin, Lang Yu, Jie Zhou, and Liang He. 2025. https://doi.org/10.1016/J.ESWA.2025.126766 Multi-MELO: Unified multimodal model editing with dynamic LoRA . Expert Syst. Appl., 273:126766
-
[9]
Sijia Chen and Baochun Li. 2022. Towards optimal multi-modal federated learning on non-iid data with hierarchical gradient blending. In IEEE INFOCOM 2022 - IEEE Conference on Computer Communications, London, United Kingdom, May 2-5, 2022 , pages 1469--1478. IEEE
work page 2022
-
[10]
Yixiong Chen, Alan Yuille, and Zongwei Zhou. 2023 b . Which layer is learning faster? a systematic exploration of layer-wise convergence rate for deep neural networks. In The Eleventh International Conference on Learning Representations
work page 2023
-
[11]
Yae Jee Cho, Luyang Liu, Zheng Xu, Aldi Fahrezi, and Gauri Joshi. 2024. Heterogeneous LoRA for Federated Fine-tuning of On-Device Foundation Models . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP 2024), pages 12903--12913
work page 2024
-
[12]
Liam Collins, Hamed Hassani, Aryan Mokhtari, and Sanjay Shakkottai. 2022. Fedavg with fine tuning: Local updates lead to representation learning. Advances in Neural Information Processing Systems, 35:10572--10586
work page 2022
-
[13]
Tiantian Feng, Digbalay Bose, Tuo Zhang, Rajat Hebbar, Anil Ramakrishna, Rahul Gupta, Mi Zhang, Salman Avestimehr, and Shrikanth Narayanan. 2023. Fedmultimodal: A benchmark for multimodal federated learning. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD 2023, Long Beach, CA, USA, August 6-10, 2023 , pages 403...
work page 2023
- [14]
-
[15]
Pengxin Guo, Shuang Zeng, Yanran Wang, Huijie Fan, Feifei Wang, and Liangqiong Qu. 2025. Selective Aggregation for Low-Rank Adaptation in Federated Learning . In Proceedings of the 13th International Conference on Learning Representations (ICLR 2025)
work page 2025
-
[16]
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. 2019. Parameter-efficient transfer learning for nlp. In ICML. PMLR
work page 2019
-
[17]
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen - Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022 a . Lora: Low-rank adaptation of large language models. In Proceedings of the 10th International Conference on Learning Representations (ICLR 2022)
work page 2022
-
[18]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, and 1 others. 2022 b . Lora: Low-rank adaptation of large language models. ICLR, 1(2):3
work page 2022
-
[19]
Weirui Kuang, Bingchen Qian, Zitao Li, Daoyuan Chen, Dawei Gao, Xuchen Pan, Yuexiang Xie, Yaliang Li, Bolin Ding, and Jingren Zhou. 2024. https://doi.org/10.1145/3637528.3671573 FederatedScope-LLM: A Comprehensive Package for Fine-tuning Large Language Models in Federated Learning . In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery a...
-
[20]
Chunyuan Li, Heerad Farkhoor, Rosanne Liu, and Jason Yosinski. 2018. Measuring the Intrinsic Dimension of Objective Landscapes . In Proceedings of the 6th International Conference on Learning Representations (ICLR 2018)
work page 2018
-
[21]
Xiang Lisa Li and Percy Liang. 2021. Prefix-tuning: Optimizing continuous prompts for generation. In ACL. Association for Computational Linguistics
work page 2021
-
[22]
Chin-Yew Lin. 2004. https://aclanthology.org/W04-1013/ Rouge: A package for automatic evaluation of summaries . In Text Summarization Branches Out, pages 74--81, Barcelona, Spain. Association for Computational Linguistics
work page 2004
-
[23]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual instruction tuning
work page 2023
- [24]
-
[25]
Xiao - Yang Liu, Rongyi Zhu, Daochen Zha, Jiechao Gao, Shan Zhong, Matt White, and Meikang Qiu. 2025. https://doi.org/10.1145/3682068 Differentially Private Low-Rank Adaptation of Large Language Model Using Federated Learning . ACM Trans. Manag. Inf. Syst. , 16(2):1--24
-
[26]
LMMs-Lab. 2024. Recaps-118k. https://huggingface.co/datasets/lmms-lab/LLaVA-ReCap-118K
work page 2024
-
[27]
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Ag \" u era y Arcas. 2017 a . Communication-efficient learning of deep networks from decentralized data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS 2017), volume 54 of Proceedings of Machine Learning Research, pages 1273--1282. PMLR
work page 2017
-
[28]
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Ag \" u era y Arcas. 2017 b . Communication-Efficient Learning of Deep Networks from Decentralized Data . In Proc. of the 20th International Conference on Artificial Intelligence and Statistics, AISTATS
work page 2017
-
[29]
Sandeep Mishra. 2024. Next-pereference. https://huggingface.co/datasets/battleMaster/llava-next-Preference-dataset-20k
work page 2024
-
[30]
Jie Mu, Wei Wang, Wenqi Liu, Tiantian Yan, and Guanglu Wang. 2024. https://doi.org/10.1145/3709147 Multimodal Large Language Model with LoRA Fine-Tuning for Multimodal Sentiment Analysis . ACM Trans. Intell. Syst. Technol. Just Accepted
-
[31]
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. https://doi.org/10.3115/1073083.1073135 Bleu: A method for automatic evaluation of machine translation . In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, pages 311--318, Philadelphia, Pennsylvania, USA. Association for Computational Linguistics
-
[32]
Fung, Hailong Yang, and Depei Qian
Jiaxing Qi, Zhongzhi Luan, Shaohan Huang, Carol J. Fung, Hailong Yang, and Depei Qian. 2024. https://doi.org/10.48550/ARXIV.2406.07925 FDLoRA: Personalized Federated Learning of Large Language Model via Dual LoRA Tuning . CoRR, abs/2406.07925
-
[33]
Ying Shen, Zhiyang Xu, Qifan Wang, Yu Cheng, Wenpeng Yin, and Lifu Huang. 2024. https://doi.org/10.18653/V1/2024.ACL-LONG.38 Multimodal Instruction Tuning with Conditional Mixture of LoRA . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL 2024), pages 637--648. Association for Computational Linguistics
- [34]
-
[35]
Youbang Sun, Zitao Li, Yaliang Li, and Bolin Ding. 2024 b . Improving LoRA in Privacy-preserving Federated Learning . In Proceedings of the 12th International Conference on Learning Representations (ICLR 2024)
work page 2024
-
[36]
Van-Tuan Tran, Khiem Le, and Quoc-Viet Pham. 2025. Revisiting Sparse Mixture of Experts for Resource-Adaptive Federated Fine-Tuning Foundation Models . In Proceedings of the 13th International Conference on Learning Representations (ICLR 2025)
work page 2025
-
[37]
Ziyao Wang, Zheyu Shen, Yexiao He, Guoheng Sun, Hongyi Wang, Lingjuan Lyu, and Ang Li. 2024 a . FLoRA: Federated Fine-Tuning Large Language Models with Heterogeneous Low-Rank Adaptations . In Proceedings of the Annual Conference on Neural Information Processing Systems 2024 (NeurIPS 2024)
work page 2024
- [38]
- [39]
-
[40]
Baochen Xiong, Xiaoshan Yang, Yaguang Song, Yaowei Wang, and Changsheng Xu. 2023. Client-adaptive cross-model reconstruction network for modality-incomplete multimodal federated learning. In Proceedings of the 31st ACM International Conference on Multimedia (MM), MM 2023, Ottawa, ON, Canada, 29 October 2023- 3 November 2023 , pages 1241--1249. ACM
work page 2023
-
[41]
Yiyuan Yang, Guodong Long, Tao Shen, Jing Jiang, and Michael Blumenstein. 2024. Dual-Personalizing Adapter for Federated Foundation Models . In Proceedings of the Annual Conference on Neural Information Processing Systems 2024 (NeurIPS 2024)
work page 2024
-
[42]
Liping Yi, Han Yu, Gang Wang, and Xiaoguang Liu. 2023. https://doi.org/10.48550/ARXIV.2310.13283 pFedLoRA: Model-Heterogeneous Personalized Federated Learning with LoRA Tuning . CoRR, abs/2310.13283
-
[43]
Qiying Yu, Yang Liu, Yimu Wang, Ke Xu, and Jingjing Liu. 2023. Multimodal federated learning via contrastive representation ensemble. In Proceedings of the 11th International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023 . OpenReview.net
work page 2023
-
[44]
Haolin Yuan, William Paul, John Aucott, Philippe Burlina, and Yinzhi Cao. 2024. Pfededit: Personalized federated learning via automated model editing. In European Conference on Computer Vision, pages 91--107. Springer
work page 2024
-
[45]
Sukwon Yun, Jiayi Xin, Inyoung Choi, Jie Peng, Ying Ding, Qi Long, and Tianlong Chen. 2025. Generate, then retrieve: Addressing missing modalities in multimodal learning via generative ai and moe. In Workshop on Large Language Models and Generative AI for Health at AAAI 2025
work page 2025
-
[46]
Huimin Zeng, Zhenrui Yue, and Dong Wang. 2024. Open-vocabulary federated learning with multimodal prototyping. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), NAACL 2024, Mexico City, Mexico, June 16-21, 2024 , pages 5644--5656. Assoc...
work page 2024
-
[47]
Dauphin, and David Lopez - Paz
Hongyi Zhang, Moustapha Ciss \' e , Yann N. Dauphin, and David Lopez - Paz. 2018. mixup: Beyond empirical risk minimization. In 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings . OpenReview.net
work page 2018
-
[48]
Jianyi Zhang, Saeed Vahidian, Martin Kuo, Chunyuan Li, Ruiyi Zhang, Tong Yu, Guoyin Wang, and Yiran Chen. 2024. https://doi.org/10.1109/ICASSP48485.2024.10447454 Towards Building The Federatedgpt: Federated Instruction Tuning . In Proceedings of the 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2024) , pages 6915--6...
-
[49]
Linlin Zong, Qiujie Xie, Jiahui Zhou, Peiran Wu, Xianchao Zhang, and Bo Xu. 2021. Fedcmr: Federated cross-modal retrieval. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, Canada, July 11-15, 2021 , pages 1672--1676. ACM
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.