From Task to Tutorial: An Automated GUI Framework for Excel Tutorial Document and Video Creation
Pith reviewed 2026-05-18 13:36 UTC · model grok-4.3
The pith
Framework automatically generates Excel tutorials and videos from natural language task descriptions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that instantiating a task from its description, deploying an Execution Agent to plan and execute it while collecting artifacts, and then converting those into documents and videos produces tutorials with 8.5% higher task execution success than baselines, readability and effectiveness approaching or surpassing expert materials, and time costs reduced to one twentieth of manual authoring.
What carries the argument
Execution Agent: plans and executes the Excel task from natural language while gathering artifacts needed to build the tutorial document and video.
If this is right
- The system scales to create tutorials for 1,559 collected real-world scenarios.
- Task execution success rates rise by 8.5% over current leading methods.
- Produced tutorials achieve readability and teaching value equal to or better than those made by experts.
- Creation time drops to one twentieth of the effort required for expert authoring.
- Manual labor is removed from the process of keeping tutorials current with software updates.
Where Pith is reading between the lines
- The artifact collection technique could help develop better AI systems for interacting with graphical user interfaces in other applications.
- Extending the framework to other office tools might create a unified system for productivity software tutorials.
- Real-time generation of tutorials based on user queries could replace static help resources in future software.
Load-bearing premise
The Execution Agent must be able to plan and execute a wide variety of complex Excel tasks based on natural language descriptions and gather complete high-quality artifacts for building tutorials.
What would settle it
A test run on many complex tasks where the agent either fails to complete them successfully or the collected artifacts lead to tutorials that users cannot follow to solve the original task.
Figures





read the original abstract
Excel is one of the most widely used productivity tools across domains, offering rich functionality but also overwhelming users with its complexity. This creates a persistent demand for tutorials to support effective usage. However, while building and maintaining the Microsoft tutorial corpus, we observed that existing tutorials are manually created by experts, need frequent updates with each software release, and involve substantial human labor. Moreover, prior work has not achieved fully automated tutorial generation. In this paper, we present the first framework for automatically generating Excel tutorials directly from natural language task descriptions. Our framework first instantiates the task. Then a central component of this framework, Execution Agent, plans and executes the solution in Excel, and collects the intermediate artifacts required for tutorial construction. These artifacts are then transformed into both structured Excel documents and video demonstrations. To build a comprehensive tutorial corpus, we collected 1,559 task descriptions from real-world scenarios. In addition, we designed a systematic evaluation framework that integrates assessments from both large language models (LLMs) and human reviewers. Experimental results show that our framework improves task execution success rates by 8.5% over state-of-the-art baselines. Moreover, the generated tutorials demonstrate superior readability and instructional effectiveness, often approaching or surpassing expert-authored materials. Importantly, the automated pipeline eliminates manual labor and reduces time costs to 1/20 of expert authoring, making scalable and high-quality tutorial generation practical for the first time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents the first fully automated framework for generating Excel tutorial documents and videos directly from natural language task descriptions. A central Execution Agent plans and executes tasks within the Excel GUI, collects intermediate artifacts (action traces, screenshots, cell states), and feeds them into pipelines that produce structured documents and video demonstrations. The authors assembled a corpus of 1,559 real-world tasks, compared their system against state-of-the-art baselines, and evaluated output quality via both LLM judges and human reviewers, reporting an 8.5% gain in task-execution success rate, tutorial quality that approaches or exceeds expert-authored materials, and a reduction in authoring time to 1/20 of manual effort.
Significance. If the central pipeline claims hold under more granular scrutiny, the work would be a meaningful contribution to automated software documentation and user-support tooling. The collection of 1,559 tasks drawn from real scenarios and the dual LLM-plus-human evaluation protocol are concrete strengths that could support reproducibility and follow-on research. The reported time reduction and quality parity with experts, if robust, would address a practical pain point in maintaining tutorial corpora for rapidly evolving productivity software.
major comments (2)
- [§4 and abstract] §4 (Evaluation) and the abstract: the headline 8.5% success-rate improvement and the downstream claims of tutorial quality and 1/20 time reduction are reported only as aggregate figures. No per-category breakdowns (e.g., by number of steps, formula complexity, or GUI vs. formula tasks) or artifact-completeness rates (percentage of tasks yielding full action traces plus screenshots) are supplied. Because the Execution Agent is the load-bearing component for the entire pipeline, the absence of these metrics leaves open the possibility that gains are concentrated on simpler tasks and do not generalize.
- [§3.2] §3.2 (Execution Agent): the manuscript asserts that the agent “plans and executes the solution in Excel, and collects the intermediate artifacts required for tutorial construction,” yet provides no quantitative failure-mode analysis or completeness statistics. If partial-artifact rates rise with multi-step or formula-heavy tasks, both the success-rate comparison and the claim of fully automated, labor-free tutorial generation become conditional on task distribution rather than a general capability.
minor comments (2)
- [§3.3] The description of the artifact-transformation stage could include a short pseudocode or data-flow diagram to clarify how raw traces are turned into document sections and video timelines.
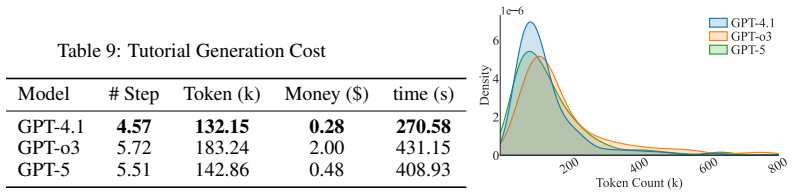
- [Table 1] Table 1 (task corpus statistics) would benefit from an additional column showing the distribution of task complexity (e.g., average number of actions per task) to help readers interpret the aggregate results.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We address each of the major comments point by point below and will incorporate additional analyses in the revised version to provide greater transparency on the Execution Agent's performance across task types.
read point-by-point responses
-
Referee: [§4 and abstract] §4 (Evaluation) and the abstract: the headline 8.5% success-rate improvement and the downstream claims of tutorial quality and 1/20 time reduction are reported only as aggregate figures. No per-category breakdowns (e.g., by number of steps, formula complexity, or GUI vs. formula tasks) or artifact-completeness rates (percentage of tasks yielding full action traces plus screenshots) are supplied. Because the Execution Agent is the load-bearing component for the entire pipeline, the absence of these metrics leaves open the possibility that gains are concentrated on simpler tasks and do not generalize.
Authors: We agree that aggregate reporting alone leaves room for the interpretation raised. The 1,559-task corpus was deliberately drawn from real-world scenarios spanning varying complexity, yet we recognize that explicit breakdowns would strengthen the generalization claim. In the revision we will add tables and figures in §4 that stratify success rates, tutorial quality scores, and artifact-completeness rates by number of steps, formula intensity, and GUI-versus-formula task type. These new analyses will be computed from the same execution logs already collected, allowing readers to verify that gains are not confined to simpler tasks. revision: yes
-
Referee: [§3.2] §3.2 (Execution Agent): the manuscript asserts that the agent “plans and executes the solution in Excel, and collects the intermediate artifacts required for tutorial construction,” yet provides no quantitative failure-mode analysis or completeness statistics. If partial-artifact rates rise with multi-step or formula-heavy tasks, both the success-rate comparison and the claim of fully automated, labor-free tutorial generation become conditional on task distribution rather than a general capability.
Authors: We accept that the current description of the Execution Agent would benefit from quantitative failure-mode and completeness statistics. We will insert a dedicated paragraph and accompanying table in §3.2 that reports (i) overall and per-category artifact-completeness rates (full traces plus screenshots), (ii) the distribution of failure modes (e.g., planning errors, execution timeouts, GUI-state mismatches), and (iii) how these rates vary with task length and formula complexity. These statistics are derivable from the execution traces already generated for the 1,559 tasks and will clarify the conditions under which the pipeline operates fully automatically. revision: yes
Circularity Check
No circularity: empirical pipeline evaluated against external baselines
full rationale
The paper describes an end-to-end automated framework that instantiates tasks, runs an Execution Agent to produce artifacts, and converts them into documents and videos. All reported gains (8.5% success-rate lift, readability scores, 1/20 time reduction) are obtained by direct comparison to external state-of-the-art baselines and by human/LLM review of the generated artifacts on a fixed corpus of 1,559 tasks. No equations, fitted parameters, or first-principles derivations are presented whose outputs are definitionally identical to their inputs. No load-bearing self-citations or uniqueness theorems are invoked. The evaluation chain therefore remains independent of any internal redefinition or self-referential fitting.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM-based Execution Agents can plan and carry out complex, multi-step Excel operations from natural language descriptions without frequent failure or human correction.
invented entities (1)
-
Execution Agent
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our framework first instantiates the task. Then a central component of this framework, Execution Agent, plans and executes the solution in Excel, and collects the intermediate artifacts required for tutorial construction.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Experimental results show that our framework improves task execution success rates by 8.5% over state-of-the-art baselines.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Agent s: An open agentic framework that uses computers like a human.arXiv preprint arXiv:2410.08164,
Saaket Agashe, Jiuzhou Han, Shuyu Gan, Jiachen Yang, Ang Li, and Xin Eric Wang. Agent s: An open agentic framework that uses computers like a human.arXiv preprint arXiv:2410.08164,
-
[2]
A transformer-based approach for source code summarization.arXiv preprint arXiv:2005.00653,
Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, and Kai-Wei Chang. A transformer-based approach for source code summarization.arXiv preprint arXiv:2005.00653,
-
[3]
Unified pre-training for program understanding and generation.arXiv preprint arXiv:2103.06333,
Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, and Kai-Wei Chang. Unified pre-training for program understanding and generation.arXiv preprint arXiv:2103.06333,
- [4]
-
[5]
URL https://www.anthropic.com/news/3-5-models-and-computer-use . Accessed: 2024- 10-26. Robert K Atkinson, Sharon J Derry, Alexander Renkl, and Donald Wortham. Learning from examples: Instructional principles from the worked examples research.Review of educational research, 70 (2):181–214,
work page 2024
-
[6]
arXiv preprint arXiv:2409.08264 (2024)
Rogerio Bonatti, Dan Zhao, Francesco Bonacci, Dillon Dupont, Sara Abdali, Yinheng Li, Yadong Lu, Justin Wagle, Kazuhito Koishida, Arthur Bucker, et al. Windows agent arena: Evaluating multi-modal os agents at scale.arXiv preprint arXiv:2409.08264,
-
[7]
Yibin Chen, Yifu Yuan, Zeyu Zhang, Yan Zheng, Jinyi Liu, Fei Ni, Jianye Hao, Hangyu Mao, and Fuzheng Zhang. Sheetagent: towards a generalist agent for spreadsheet reasoning and manipulation via large language models. InProceedings of the ACM on Web Conference 2025, pages 158–177,
work page 2025
-
[8]
Meshflow: interactive visualization of mesh construction sequences
Jonathan D Denning, William B Kerr, and Fabio Pellacini. Meshflow: interactive visualization of mesh construction sequences. InACM SIGGRAPH 2011 papers, pages 1–8
work page 2011
-
[9]
Generating photo manipulation tutorials by demonstration
Floraine Grabler, Maneesh Agrawala, Wilmot Li, Mira Dontcheva, and Takeo Igarashi. Generating photo manipulation tutorials by demonstration. InACM SIGGRAPH 2009 papers, pages 1–9
work page 2009
-
[10]
InfiGUI-R1: Advancing Multimodal GUI Agents from Reactive Actors to Deliberative Reasoners
Yuhang Liu, Pengxiang Li, Congkai Xie, Xavier Hu, Xiaotian Han, Shengyu Zhang, Hongxia Yang, and Fei Wu. Infigui-r1: Advancing multimodal gui agents from reactive actors to deliberative reasoners.arXiv preprint arXiv:2504.14239,
work page internal anchor Pith review arXiv
-
[11]
Omniparser for pure vision based gui agent.arXiv preprint arXiv:2408.00203,
Yadong Lu, Jianwei Yang, Yelong Shen, and Ahmed Awadallah. Omniparser for pure vision based gui agent.arXiv preprint arXiv:2408.00203,
-
[12]
Qinyu Luo, Yining Ye, Shihao Liang, Zhong Zhang, Yujia Qin, Yaxi Lu, Yesai Wu, Xin Cong, Yankai Lin, Yingli Zhang, et al. Repoagent: An llm-powered open-source framework for repository-level code documentation generation.arXiv preprint arXiv:2402.16667,
-
[13]
Computer-using agent: Introducing a universal interface for ai to interact with the digital world
OpenAI. Computer-using agent: Introducing a universal interface for ai to interact with the digital world. 2025a. URLhttps://openai.com/index/computer-using-agent. OpenAI. Openai api reference. https://platform.openai.com/docs/api-reference/chat, 2025b. Accessed: 2025-09-08. OpenAI. Computer-using agent: Introducing a universal interface for ai to interac...
work page 2025
-
[14]
Gpt-4.1.https://openai.com/index/gpt-4-1/, 2025d
OpenAI. Gpt-4.1.https://openai.com/index/gpt-4-1/, 2025d. Accessed: 2025-09-08. OpenAI. Introducing gpt-5. https://openai.com/index/introducing-gpt-5/, 2025e. Ac- cessed: 2025-09-08. OpenAI. Introducing o3 and o4 mini. https://openai.com/index/ introducing-o3-and-o4-mini/, 2025f. Accessed: 2025-09-08. Justin Payan, Swaroop Mishra, Mukul Singh, Carina Negr...
-
[15]
Cotext: Multi-task learning with code-text transformer.arXiv preprint arXiv:2105.08645,
Long Phan, Hieu Tran, Daniel Le, Hieu Nguyen, James Anibal, Alec Peltekian, and Yanfang Ye. Cotext: Multi-task learning with code-text transformer.arXiv preprint arXiv:2105.08645,
-
[16]
A Comprehensive Survey of Agents for Computer Use: Foundations, Challenges, and Future Directions
Pascal J Sager, Benjamin Meyer, Peng Yan, Rebekka von Wartburg-Kottler, Layan Etaiwi, Aref Enayati, Gabriel Nobel, Ahmed Abdulkadir, Benjamin F Grewe, and Thilo Stadelmann. Ai agents for computer use: A review of instructionbased computer control, gui automation, and operator assistants.arXiv preprint arXiv:2501.16150,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications
Pranab Sahoo, Ayush Kumar Singh, Sriparna Saha, Vinija Jain, Samrat Mondal, and Aman Chadha. A systematic survey of prompt engineering in large language models: Techniques and applications. arXiv preprint arXiv:2402.07927,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Principled instructions are all you need for questioning llms.arXiv preprint arXiv:2306.01577,
Simeng Sun, Aston Zhang, Junxian He, Zhiyuan Jin, Tong Zhao, Bang Chen, Wenyi Liu, Yelong Shen, Shuai Wang, Haoyu Wang, et al. Principled instructions are all you need for questioning llms.arXiv preprint arXiv:2306.01577,
-
[19]
How-to pages: Informal systems of expertise sharing
Cristen Torrey, David W McDonald, Bill N Schilit, and Sara Bly. How-to pages: Informal systems of expertise sharing. InECSCW 2007: Proceedings of the 10th European Conference on Computer- Supported Cooperative Work, Limerick, Ireland, 24-28 September 2007, pages 391–410. Springer,
work page 2007
-
[20]
Automatic generation of two-level hierarchical tutorials from instructional makeup videos
20 Anh Truong, Peggy Chi, David Salesin, Irfan Essa, and Maneesh Agrawala. Automatic generation of two-level hierarchical tutorials from instructional makeup videos. InProceedings of the 2021 CHI Conference on Human Factors in Computing Systems, pages 1–16,
work page 2021
-
[21]
On pause: How online instructional videos are used to achieve practical tasks
Sylvaine Tuncer, Barry Brown, and Oskar Lindwall. On pause: How online instructional videos are used to achieve practical tasks. InProceedings of the 2020 CHI Conference on Human Factors in Computing Systems, pages 1–12,
work page 2020
-
[22]
Large action models: From inception to implementation.arXiv preprint arXiv:2412.10047,
Lu Wang, Fangkai Yang, Chaoyun Zhang, Junting Lu, Jiaxu Qian, Shilin He, Pu Zhao, Bo Qiao, Ray Huang, Si Qin, et al. Large action models: From inception to implementation.arXiv preprint arXiv:2412.10047,
-
[23]
Leveraging community-generated videos and command logs to classify and recommend software workflows
Xu Wang, Benjamin Lafreniere, and Tovi Grossman. Leveraging community-generated videos and command logs to classify and recommend software workflows. InProceedings of the 2018 CHI Conference on Human Factors in Computing Systems, pages 1–13,
work page 2018
-
[24]
Gui-actor: Coordinate-free visual grounding for gui agents.arXiv preprint arXiv:2506.03143,
Qianhui Wu, Kanzhi Cheng, Rui Yang, Chaoyun Zhang, Jianwei Yang, Huiqiang Jiang, Jian Mu, Baolin Peng, Bo Qiao, Reuben Tan, et al. Gui-actor: Coordinate-free visual grounding for gui agents.arXiv preprint arXiv:2506.03143,
-
[25]
Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V
Jianwei Yang, Hao Zhang, Feng Li, Xueyan Zou, Chunyuan Li, and Jianfeng Gao. Set-of-mark prompting unleashes extraordinary visual grounding in gpt-4v.arXiv preprint arXiv:2310.11441,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Chaoyun Zhang, Shilin He, Liqun Li, Si Qin, Yu Kang, Qingwei Lin, Saravan Rajmohan, and Dongmei Zhang. Api agents vs. gui agents: Divergence and convergence. InICML 2025 Workshop on Computer Use Agents. Chaoyun Zhang, Shilin He, Jiaxu Qian, Bowen Li, Liqun Li, Si Qin, Yu Kang, Minghua Ma, Guyue Liu, Qingwei Lin, et al. Large language model-brained gui age...
-
[27]
Jiani Zheng, Lu Wang, Fangkai Yang, Chaoyun Zhang, Lingrui Mei, Wenjie Yin, Qingwei Lin, Dongmei Zhang, Saravan Rajmohan, and Qi Zhang. Vem: Environment-free exploration for training gui agent with value environment model.arXiv preprint arXiv:2502.18906,
-
[28]
Ruiyan Zhu, Xi Cheng, Ke Liu, Brian Zhu, Daniel Jin, Neeraj Parihar, Zhoutian Xu, and Oliver Gao. Sheetmind: An end-to-end llm-powered multi-agent framework for spreadsheet automation.arXiv preprint arXiv:2506.12339,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.