Semantic-Space Exploration and Exploitation in RLVR for LLM Reasoning
Pith reviewed 2026-05-18 11:57 UTC · model grok-4.3
The pith
Effective Rank in hidden states shows exploration and exploitation can be improved simultaneously in RLVR for LLM reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
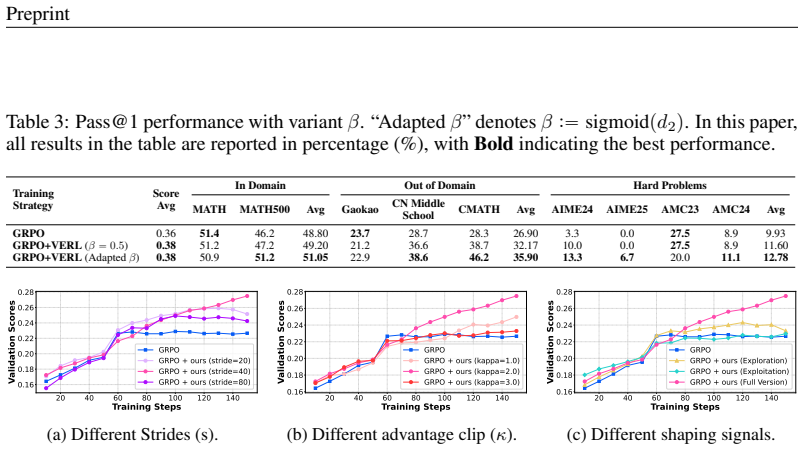
Effective Rank (ER) computed on the hidden states of response trajectories quantifies representational exploration, while its temporal derivatives Effective Rank Velocity (ERV) and Effective Rank Acceleration (ERA) characterize exploitative refinement. ER and ERV exhibit near-zero correlation in semantic space, indicating that the two capacities can be improved at the same time. VERL incorporates an auxiliary signal derived from ER and ERV into the RLVR advantage and uses the more stable ERA as a meta-control variable to adaptively balance the incentives, producing consistent improvements including a 21.4% gain on Gaokao 2024.
What carries the argument
Effective Rank (ER) of hidden states in response trajectories together with its velocity (ERV) and acceleration (ERA), used to shape the RLVR advantage and adaptively balance exploration and exploitation.
If this is right
- Token-level entropy and are poor proxies for the exploration-exploitation dynamics that matter in multi-step reasoning.
- Representational exploration and its rate of change can be targeted independently in the hidden-state space.
- VERL can be plugged into existing RLVR pipelines without introducing new trade-offs.
- Larger gains appear on tasks that require sustained multi-step progress rather than single-hop answers.
Where Pith is reading between the lines
- The same hidden-state rank measures could be tested as diagnostic tools for evaluating reasoning quality even outside reinforcement learning.
- If the near-zero correlation holds more broadly, similar rank-based signals might help other sequential generation tasks where progress is hard to observe directly.
- The approach invites experiments that vary trajectory length or model depth to see whether the independence between ER and ERV remains stable.
Load-bearing premise
Effective Rank computed on hidden states of response trajectories meaningfully quantifies representational exploration relevant to multi-step reasoning progress rather than generic diversity.
What would settle it
A finding that ER and ERV remain strongly correlated when computed across many trajectories and models, or that VERL produces no improvement on new challenging reasoning benchmarks, would undermine the independence claim and the value of the proposed shaping method.
Figures




















read the original abstract
Reinforcement Learning with Verifiable Rewards (RLVR) for LLM reasoning is often framed as balancing exploration and exploitation in action space, typically operationalized with token-level proxies (e.g., output entropy or confidence). We argue that this apparent trade-off is largely a measurement artifact: token-level statistics reflect next-token uncertainty rather than how reasoning progresses over multi-token semantic structures. We therefore study exploration and exploitation in the hidden-state space of response trajectories. We use Effective Rank (ER) to quantify representational exploration and introduce its temporal derivatives, Effective Rank Velocity (ERV) and Effective Rank Acceleration (ERA), to characterize exploitative refinement dynamics. Empirically and theoretically, ER and ERV exhibit near-zero correlation in semantic space, suggesting the two capacities can be improved simultaneously. Motivated by this, we propose Velocity-Exploiting Rank Learning (VERL), which shapes the RLVR advantage with an auxiliary signal derived from ER/ERV and uses the more stable ERA as a meta-control variable to adaptively balance the incentives. Across multiple base models, RLVR algorithms, and reasoning benchmarks, VERL yields consistent improvements, including large gains on challenging tasks (e.g., 21.4\% in Gaokao 2024). The code is available at https://github.com/hf618/VERL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that the apparent exploration-exploitation trade-off in RLVR for LLM reasoning is a measurement artifact arising from token-level proxies. Shifting analysis to hidden-state space, it quantifies representational exploration via Effective Rank (ER) on response trajectories and introduces Effective Rank Velocity (ERV) and Acceleration (ERA) to capture exploitative refinement. It reports near-zero correlation between ER and ERV (both empirically and theoretically), proposes Velocity-Exploiting Rank Learning (VERL) that augments the RL advantage with an ER/ERV-derived auxiliary signal and uses ERA as a meta-controller, and demonstrates consistent gains across base models, RLVR algorithms, and benchmarks including a 21.4% improvement on Gaokao 2024. Code is released.
Significance. If the central claims hold, the work provides a semantic-space alternative to token-level proxies for balancing exploration and exploitation in LLM reasoning, with the near-zero correlation result suggesting the two capacities need not trade off. Releasing code is a positive for reproducibility. The significance hinges on whether ER on hidden states specifically tracks reasoning-relevant representational exploration rather than generic activation diversity.
major comments (3)
- [Abstract and §3 (ER/ERV definitions)] The load-bearing premise that Effective Rank computed on hidden states of response trajectories quantifies representational exploration relevant to multi-step reasoning progress (rather than generic diversity) is insufficiently validated. ER is a standard effective-dimensionality measure via singular values; without ablations correlating ER/ERV with reasoning-path metrics or solution-structure diversity (e.g., in the experimental or analysis sections), the near-zero correlation claim and VERL motivation remain at risk of capturing superficial variance.
- [VERL method description (likely §4)] VERL shapes the advantage with an auxiliary signal derived from ER/ERV using weighting coefficients and normalization choices. The manuscript should demonstrate that reported gains are robust to these choices or that the method is effectively parameter-free; otherwise the simultaneous-improvement claim risks circularity through post-hoc fitting of the auxiliary term.
- [Experimental results and tables] The 21.4% gain on Gaokao 2024 and other benchmark improvements are presented as evidence of VERL efficacy, but the results section lacks details on number of random seeds, statistical significance tests, exact baseline implementations, and data splits. These omissions prevent assessment of whether the gains are reliable or could arise from post-hoc benchmark selection.
minor comments (2)
- [§3] Explicit equations for the temporal derivatives ERV and ERA (and how they are computed from the hidden-state trajectory matrix) would clarify the method; currently the description relies on prose.
- [Figures] Figure captions and axis labels for any ER/ERV correlation plots should explicitly state the layer(s) and trajectory construction used, to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment point by point below, providing clarifications from the manuscript and indicating where we will strengthen the presentation through revision.
read point-by-point responses
-
Referee: [Abstract and §3 (ER/ERV definitions)] The load-bearing premise that Effective Rank computed on hidden states of response trajectories quantifies representational exploration relevant to multi-step reasoning progress (rather than generic diversity) is insufficiently validated. ER is a standard effective-dimensionality measure via singular values; without ablations correlating ER/ERV with reasoning-path metrics or solution-structure diversity (e.g., in the experimental or analysis sections), the near-zero correlation claim and VERL motivation remain at risk of capturing superficial variance.
Authors: We agree that explicit correlations with reasoning-path metrics would provide stronger support for interpreting ER as tracking reasoning-relevant exploration. The manuscript already presents both empirical near-zero correlation between ER and ERV across multiple models and a theoretical argument in §3 showing that ER and its temporal derivatives capture orthogonal components of hidden-state dynamics (effective dimensionality versus rate of change). However, to directly address the concern of superficial variance, we will add new analysis in the revised version correlating ER/ERV with reasoning-specific measures such as the diversity of solution structures (via parse-tree edit distance) and the number of distinct reasoning steps in trajectories. These ablations will be placed in the analysis section. revision: yes
-
Referee: [VERL method description (likely §4)] VERL shapes the advantage with an auxiliary signal derived from ER/ERV using weighting coefficients and normalization choices. The manuscript should demonstrate that reported gains are robust to these choices or that the method is effectively parameter-free; otherwise the simultaneous-improvement claim risks circularity through post-hoc fitting of the auxiliary term.
Authors: The weighting and normalization choices in VERL are derived from the observed ranges of ER and ERV to ensure the auxiliary term remains on a comparable scale to the primary advantage; they are held fixed across all experiments rather than tuned per benchmark. To demonstrate robustness and remove any appearance of post-hoc fitting, we will add a sensitivity study in the revised appendix showing that performance gains persist across a range of coefficient values around the chosen settings. This will confirm that the simultaneous improvement arises from the core design of augmenting with the ER/ERV signal. revision: yes
-
Referee: [Experimental results and tables] The 21.4% gain on Gaokao 2024 and other benchmark improvements are presented as evidence of VERL efficacy, but the results section lacks details on number of random seeds, statistical significance tests, exact baseline implementations, and data splits. These omissions prevent assessment of whether the gains are reliable or could arise from post-hoc benchmark selection.
Authors: We agree that additional experimental details are necessary for full reproducibility and reliability assessment. In the revised manuscript we will expand the results section and appendix to report: the number of random seeds used for each experiment, statistical significance tests (including p-values from paired comparisons), exact baseline implementations with references to original code or papers, and precise descriptions of data splits and evaluation protocols for all benchmarks including Gaokao 2024. These additions will allow readers to evaluate whether the reported gains, such as the 21.4% improvement, are robust. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines Effective Rank (ER) on hidden states of response trajectories as a measure of representational exploration and introduces ERV/ERA as temporal derivatives. It reports an empirical and theoretical near-zero correlation between ER and ERV, then proposes VERL to incorporate an auxiliary signal from these quantities into the RLVR advantage. No quoted step reduces a claimed prediction or result to its own inputs by construction; the correlation is presented as an observed finding rather than a definitional identity, and benchmark gains are shown as external validation. The auxiliary signal is newly introduced rather than a re-expression of the base RL objective, keeping the chain self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- weighting coefficients for ER/ERV auxiliary signal
axioms (1)
- domain assumption Hidden states of response trajectories encode multi-token semantic structures relevant to reasoning progress.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We use Effective Rank (ER) to quantify representational exploration and introduce its temporal derivatives, Effective Rank Velocity (ERV) and Effective Rank Acceleration (ERA)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ER and ERV exhibit near-zero correlation in semantic space
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
FACT-E: Causality-Inspired Evaluation for Trustworthy Chain-of-Thought Reasoning
FACT-E uses controlled perturbations as an instrumental signal to measure intra-chain faithfulness in CoT reasoning and combines it with answer consistency to select trustworthy trajectories.
Reference graph
Works this paper leans on
-
[1]
There is no functionf:RÑRsuch thatERVpmq “fpER finalpmqqfor all trajectories mPR K
-
[2]
There is no functiong:RÑRsuch thatER finalpmq “gpERVpmqqfor all trajectories mPR K. Equivalently,ER final andERVare not functionally dependent: they capture genuinely different aspects of the Effective Rank sequence. Proof.We viewER final andERVas real-valued functions onR K. The proof is purely algebraic and does not rely on any monotonicity ofm j. Step ...
-
[3]
the singular values satisfyσ 1 “ ¨ ¨ ¨ “σ k ą0andσ k`1 “ ¨ ¨ ¨ “σ r “0, then ERpZ1:T q “k
If the trajectory uses exactlykorthogonal semantic directions with equal energy and no others, i.e. the singular values satisfyσ 1 “ ¨ ¨ ¨ “σ k ą0andσ k`1 “ ¨ ¨ ¨ “σ r “0, then ERpZ1:T q “k
-
[4]
¨ ¨ ¨ “σ k “cą0, σ k`1 “ ¨ ¨ ¨ “σ r “0.(56) The normalized singular values are thus qi “
More generally, if the singular value spectrum ofZ 1:T becomes morespread outover more directions in the sense of majorization (i.e. the normalized singular value vector becomes more uniform over a larger support), thenERpZ 1:T qincreases. Consequently,ERpZ 1:T qis a basis-invariant, strictly increasing measure of the number of in- dependent semantic dire...
-
[5]
(Fixed semantic support) The support ofq pjq is independent ofj, i.e., the set of active semantic directions is fixed
-
[6]
(Uniformization within the support) For everyjě2,q pjq is more uniform thanq pj´1q on this fixed support, in the sense of majorization, so that by Prop. F.5 we havemj ´m j´1 “ ∆mj ěµfor someµą0. Intuitively, condition (i) says that the model has committed to a particular semantic subspace (a line of reasoning), and condition (ii) says that it keeps redist...
work page 2025
-
[7]
suggests that the last layers are most aligned with semantic meaning and model predictions. Empirically, using the final layer gives consistently better performance than using an intermediate layer: for example, GRPO + VERL with the last layer improves the average pass@1 from 41.69% (layer 14) to 43.44%, and the average pass@k from 61.52% (layer 14) to 64...
work page 2025
-
[8]
The divisors of 12 are:˘1,˘2,˘3,˘4,˘6,˘12
-
[9]
We need to find the smallestx, so we start with the smallest positive divisor, which is 1: x`1“1ù ñx“1´1ù ñx“0
-
[10]
To confirm, we substitutex“0back into the original expression: 12 0`1 “ 12 1 “12 Since 12 is an integer,x“0is indeed a valid solution
-
[11]
The next smallest divisor is -1: x`1“ ´1ù ñx“ ´1´1ù ñx“ ´2
We should also consider the negative divisors to ensure we have the smallest possible integer value. The next smallest divisor is -1: x`1“ ´1ù ñx“ ´1´1ù ñx“ ´2
-
[12]
No house faces two different streets
Substitutingx“ ´2back into the original expression: 12 ´2`1 “ 12 ´1 “ ´12 Since -12 is an integer,x“ ´2is also a valid solution, but it is not smaller thanx“0. Therefore, the smallest possible integer value ofxis 0 Vanilla GRPO To find the smallest possible integer value ofxsuch that 12 x`1 is an integer, we need to determine the divisors of 12. The divis...
-
[13]
There are 6 streets in the neighborhood
-
[14]
Each street has houses on both sides
-
[15]
There are 10 houses on each side of every street
-
[16]
No house faces two different streets, meaning each house is counted only once. First, calculate the number of houses on one side of a single street: 10houses/side Since there are houses on both sides of each street, multiply by 2: 10houses/sideˆ2sides/street“20houses/street Now, since there are 6 streets, multiply the number of houses per street by the nu...
-
[18]
For the denominator to be non-zero: x´2‰0 Solving this equation: x‰2 (Details omitted as they are not crucial for this case study.) Therefore, the smallest possible integer value for xsuch thatfpxqhas a real number value is: 3 (Details omitted as they are not crucial for this case study.)
-
[19]
For the square root to be defined, the expression inside it must be greater than or equal to zero: x´1ě0 Solving this inequality: xě1
-
[20]
(Details omitted as they are not crucial for this case study.)
For the function to be defined, the denominator must not be zero: x´2‰0 Solving this equation: x‰2 (Details omitted as they are not crucial for this case study.) Therefore, the smallest possible integer value for xsuch thatfpxqhas a real number value is3 . (Details omitted as they are not crucial for this case study.)
-
[22]
The smallest integer that satisfies this condition isx“3
For the denominator to be non-zero, we need: x´2‰0 Solving this equation: x‰2 Combining these two con- ditions,xmust be greater than or equal to 1 but not equal to 2. The smallest integer that satisfies this condition isx“3. Therefore, the smallest possible integer value for xsuch thatfpxqhas a real number value is3 . (Details omitted as they are not cruc...
-
[23]
For the square root to be defined, we need: x´1ě0 xě1
-
[24]
Therefore, the smallest possible integer value for xsuch thatfpxqhas a real number value is3
For the denominator to be non-zero, we need: x´2‰0 x‰2 Combining these two con- ditions, we get: xě1 x‰2 The smallest integer that satisfiesxě1andx‰2 isx“3. Therefore, the smallest possible integer value for xsuch thatfpxqhas a real number value is3 . (Details omitted as they are not crucial for this case study.) 1.Numerator Condition: The expression unde...
-
[25]
For the square root to be defined in the real num- bers, the expression inside it must be greater than or equal to zero: x´1ě0 Solving this inequality: xě1
-
[26]
(Details omitted as they are not crucial for this case study.)
For the function to be defined, the denominator must not be zero: x´2‰0 Solving this equation: x‰2 (Details omitted as they are not crucial for this case study.) Thus, the smallest possible integer value forxsuch thatfpxqhas a real num- ber value is3 . (Details omitted as they are not crucial for this case study.)
-
[27]
The expression inside the square root must be non-negative. 2. The de- nominator must not be zero. (Details omitted as they are not crucial for this case study.) ### Step 3: Combine the conditions From Step 1, we knowxě1. From Step 2, we knowx‰2. Therefore, the smallest integer value forxthat satisfies both conditions is the smallest integer greater than ...
-
[28]
For ?x´1to be de- fined, we need: x´1ě0ù ñxě1
-
[29]
For the denominator x´2to be non-zero, we need: x´2‰0ù ñx‰2 Combining these two con- ditions, we get: xě1andx‰2 The smallest integer that satisfiesxě1andx‰2 isx“1. (Details omitted as they are not crucial for this case study.) Sincefp1q “0is a real number, our solution is confirmed. Therefore, the smallest possible integer value for xsuch thatfpxqhas a re...
-
[30]
For ?x´1to be de- fined in the real numbers, we need: x´1ě0ù ñxě1
-
[31]
The smallest integer that satisfies this condition isx“3
For the denominator x´2to not be zero, we need: x´2‰0ù ñx‰2 Combining these two con- ditions,xmust be greater than or equal to 1 but not equal to 2. The smallest integer that satisfies this condition isx“3. Therefore, the smallest possible integer value for xsuch thatfpxqhas a real number value is3 . Figure 14: Case study demonstrating improved exploratio...
-
[32]
For the square root to be defined, we need: x´1ě0 Solving this inequality: xě1
-
[33]
The smallest integer that satisfies this condition isx“3
For the denominator to be non-zero, we need: x´2‰0 Solving this equation: x‰2 Combining these two con- ditions,xmust be greater than or equal to 1 but not equal to 2. The smallest integer that satisfies this condition isx“3. Therefore, the smallest possible integer value for xsuch thatfpxqhas a real number value is3 . (Details omitted as they are not cruc...
-
[34]
The expression inside the square root must be non-negative. 2. The de- nominator must not be zero. Let’s address these condi- tions one by one:
-
[35]
For the square root to be defined, the expression inside it must be greater than or equal to zero: x´1ě0ù ñxě1
-
[36]
The smallest integer that satis- fies this isx“3
For the denominator to be non-zero: x´2‰0ù ñx‰2 Combining these condi- tions, we needxto be greater than or equal to 1 but not equal to 2. The smallest integer that satis- fies this isx“3. Therefore, the smallest possible integer value for xsuch thatfpxqhas a real number value is3 . (Details omitted as they are not crucial for this case study.) 1.Numerato...
-
[37]
Recognize that the tri- angleABCis a right tri- angle with=BAC“ 90˝ and=ABC“60 ˝. Therefore,=ACB“ 30˝. (Details omitted as they are not crucial for this case study.)
-
[38]
SinceAC“48feet, and in a 30-60-90 triangle, the side opposite the 60° angle is ? 3times the side opposite the 30° angle, we can findAB: AB“48 ? 3 (Details omitted as they are not crucial for this case study.) Therefore, the square of the distance between Ab- dul and Bharat is6912 feet. To solve this problem, we need to use some geomet- ric principles, spe...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.