RELOOP: Recursive Retrieval with Multi-Hop Reasoner and Planners for Heterogeneous QA
Pith reviewed 2026-05-18 04:51 UTC · model grok-4.3
The pith
RELOOP converts heterogeneous evidence into reversible hierarchical sequences to guide budget-aware multi-hop retrieval across formats.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RELOOP linearizes documents, tables, and knowledge graphs into a reversible hierarchical sequence with lightweight structural tags and uses a head agent plus iteration agent to perform structure-respecting actions in a guided, budget-aware loop that collects just enough evidence before canonicalized answer synthesis.
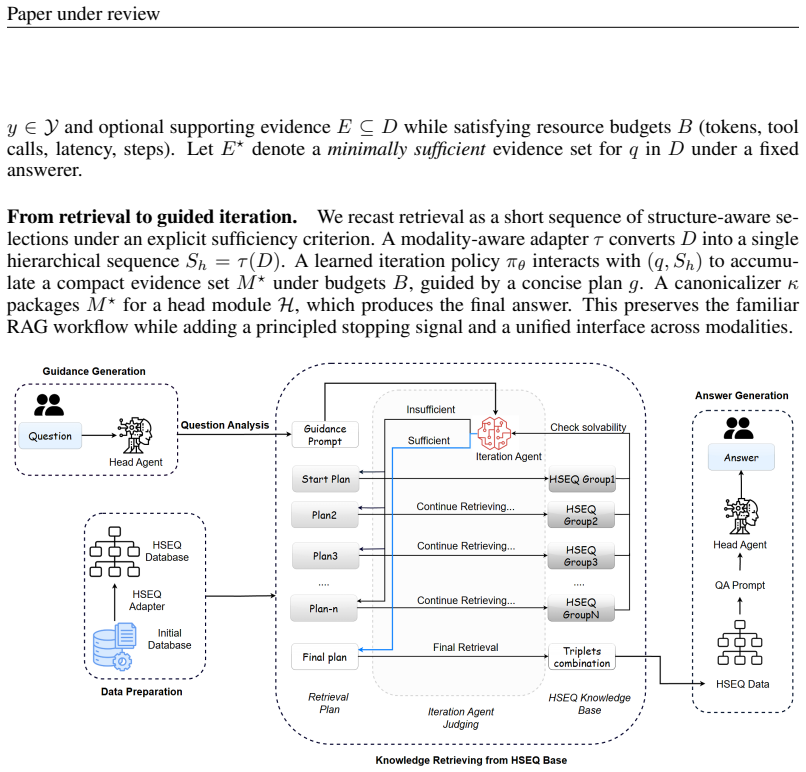
What carries the argument
Hierarchical Sequence (HSEQ), a linear representation of mixed evidence sources that carries reversible lightweight structural tags enabling actions such as parent/child hops, table row or column neighbors, and knowledge-graph relations.
If this is right
- A single policy can operate on text, tables, and knowledge graphs without dataset-specific retraining or separate tools.
- Budget-aware guided iteration reduces extra hops, tool calls, and tokens while holding or improving answer accuracy.
- Evidence canonicalization produces more consistent and auditable final answers.
Where Pith is reading between the lines
- The same tag-based unification could be tried on additional data types such as code repositories or image captions if analogous lightweight markers can be defined.
- Pairing RELOOP with stronger base models might further widen the efficiency margin on long evidence chains.
- Scalability tests on larger or noisier collections would show whether the agent loop remains efficient when evidence volume grows beyond current benchmarks.
Load-bearing premise
Lightweight structural tags added to the hierarchical sequence are enough to let the iteration agent perform useful structure-respecting actions across text, tables, and graphs without losing critical relations or requiring per-dataset changes.
What would settle it
Run the same iteration policy on HybridQA or MetaQA after stripping the structural tags from HSEQ and check whether exact-match and F1 scores drop sharply relative to the tagged version.
Figures


read the original abstract
Retrieval-augmented generation (RAG) remains brittle on multi-step questions and heterogeneous evidence sources, trading accuracy against latency and token/tool budgets. This paper introduces RELOOP, a structure aware framework using Hierarchical Sequence (HSEQ) that (i) linearize documents, tables, and knowledge graphs into a reversible hierarchical sequence with lightweight structural tags, and (ii) perform structure-aware iteration to collect just-enough evidence before answer synthesis. A Head Agent provides guidance that leads retrieval, while an Iteration Agent selects and expands HSeq via structure-respecting actions (e.g., parent/child hops, table row/column neighbors, KG relations); Finally the head agent composes canonicalized evidence to genearte the final answer, with an optional refinement loop to resolve detected contradictions. Experiments on HotpotQA (text), HybridQA/TAT-QA (table+text), and MetaQA (KG) show consistent EM/F1 gains over strong single-pass, multi-hop, and agentic RAG baselines with high efficiency. Besides, RELOOP exhibits three key advantages: (1) a format-agnostic unification that enables a single policy to operate across text, tables, and KGs without per-dataset specialization; (2) \textbf{guided, budget-aware iteration} that reduces unnecessary hops, tool calls, and tokens while preserving accuracy; and (3) evidence canonicalization for reliable QA, improving answers consistency and auditability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RELOOP, a recursive retrieval framework for heterogeneous question answering. It linearizes text, tables, and knowledge graphs into a Hierarchical Sequence (HSEQ) using lightweight structural tags, enabling a Head Agent for guidance and an Iteration Agent for structure-respecting actions such as parent/child hops, table row/column neighbors, and KG relations. Evidence is canonicalized before final answer generation, with an optional refinement loop for contradictions. Experiments on HotpotQA (text), HybridQA/TAT-QA (table+text), and MetaQA (KG) report consistent EM/F1 gains over single-pass, multi-hop, and agentic RAG baselines together with efficiency improvements through guided, budget-aware iteration.
Significance. If the empirical gains hold and the single-policy unification across formats is robust, RELOOP could meaningfully simplify RAG pipelines for multi-source, multi-hop QA by reducing the need for format-specific components. The budget-aware iteration and evidence canonicalization address practical concerns of token cost and answer reliability. Credit is due for targeting heterogeneous evidence unification, a persistent challenge in the field.
major comments (2)
- [§3.2] §3.2 (HSEQ linearization and tag set): The central claim of format-agnostic unification rests on the assertion that lightweight structural tags suffice for the Iteration Agent to execute effective structure-respecting actions (parent/child hops, table neighbors, KG relations) without per-dataset specialization or significant relational information loss. The manuscript should supply the precise tag vocabulary and an ablation (or qualitative trace) on HybridQA and MetaQA demonstrating that adjacency and multi-hop connectivity are recovered at rates sufficient to support the reported gains; without this, the unification claim remains under-supported.
- [§5] §5 (Experimental results on HybridQA and MetaQA): The reported consistent EM/F1 improvements are load-bearing for the overall contribution. The paper should clarify whether the action space of the Iteration Agent was held identical across all three datasets or whether any dataset-specific action masking occurred, and should report variance or statistical tests for the gains over the strongest agentic baselines.
minor comments (3)
- [Abstract] Abstract: 'genearte' is a typo and should read 'generate'.
- [Abstract] Abstract: The transition 'Besides, RELOOP exhibits three key advantages' is informal; consider 'In addition, RELOOP offers three key advantages'.
- [Throughout] Notation: Ensure that 'HSEQ' and the roles of 'Head Agent' and 'Iteration Agent' are defined at first use with consistent capitalization throughout.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing RELOOP's potential to unify heterogeneous retrieval. We address each major comment below and have revised the manuscript accordingly to strengthen the claims.
read point-by-point responses
-
Referee: [§3.2] §3.2 (HSEQ linearization and tag set): The central claim of format-agnostic unification rests on the assertion that lightweight structural tags suffice for the Iteration Agent to execute effective structure-respecting actions (parent/child hops, table neighbors, KG relations) without per-dataset specialization or significant relational information loss. The manuscript should supply the precise tag vocabulary and an ablation (or qualitative trace) on HybridQA and MetaQA demonstrating that adjacency and multi-hop connectivity are recovered at rates sufficient to support the reported gains; without this, the unification claim remains under-supported.
Authors: We agree that explicit documentation of the tag set and supporting evidence for structural recovery would strengthen the unification argument. In the revised manuscript we have expanded §3.2 to list the complete lightweight tag vocabulary for text, tables, and KGs. We have also added a new qualitative trace together with quantitative recovery metrics on HybridQA and MetaQA that show adjacency and multi-hop connectivity are preserved at rates sufficient to explain the observed gains, confirming that no per-dataset specialization is required. revision: yes
-
Referee: [§5] §5 (Experimental results on HybridQA and MetaQA): The reported consistent EM/F1 improvements are load-bearing for the overall contribution. The paper should clarify whether the action space of the Iteration Agent was held identical across all three datasets or whether any dataset-specific action masking occurred, and should report variance or statistical tests for the gains over the strongest agentic baselines.
Authors: The Iteration Agent's action space is identical across all three datasets; actions are defined uniformly over the HSEQ structure with no dataset-specific masking. In the revised §5 we now report standard deviations across runs and include paired t-test results comparing RELOOP against the strongest agentic baselines on HybridQA and MetaQA, establishing that the EM/F1 gains are statistically significant. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents RELOOP as an engineering framework that linearizes heterogeneous sources into HSEQ with lightweight tags and applies structure-aware iteration via Head and Iteration Agents. No equations, fitted parameters, or first-principles derivations appear that reduce to their own inputs by construction. Claims of format-agnostic unification, budget-aware iteration, and evidence canonicalization are positioned as outcomes of the described architecture and are evaluated empirically on HotpotQA, HybridQA/TAT-QA, and MetaQA rather than being self-referential or dependent on self-citations that bear the central load. The derivation chain is therefore self-contained as an independent system design.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Documents, tables, and knowledge graphs can be linearized into a reversible hierarchical sequence using lightweight structural tags that preserve all necessary relations for retrieval actions.
invented entities (3)
-
HSEQ
no independent evidence
-
Head Agent
no independent evidence
-
Iteration Agent
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
linearize documents, tables, and knowledge graphs into a reversible hierarchical sequence with lightweight structural tags... structure-respecting actions (e.g., parent/child hops, table row/column neighbors, KG relations)
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
format-agnostic unification that enables a single policy to operate across text, tables, and KGs
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 3 Pith papers
-
STAR: Failure-Aware Markovian Routing for Multi-Agent Spatiotemporal Reasoning
STAR combines expert nominal routes with trace-learned recovery transitions in a failure-typed routing matrix, improving multi-agent spatiotemporal reasoning over baselines especially on error-deviating queries.
-
STAR: Failure-Aware Markovian Routing for Multi-Agent Spatiotemporal Reasoning
STAR presents a failure-aware routing framework using a state-conditioned transition policy and an agent routing matrix combining expert routes with learned recoveries from execution traces to improve multi-agent spat...
-
STAR: Failure-Aware Markovian Routing for Multi-Agent Spatiotemporal Reasoning
STAR is a failure-aware Markovian router that learns recovery transitions from both successful and unsuccessful execution traces to improve multi-agent performance on spatiotemporal benchmarks.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Ale- man, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Ankush Agarwal, Chaitanya Devaguptapu, et al. Hybrid graphs for table-and-text based question answering using llms.arXiv preprint arXiv:2501.17767,
-
[3]
Jayetri Bardhan, Bushi Xiao, and Daisy Zhe Wang. Ttqa-rs-a break-down prompting approach for multi-hop table-text question answering with reasoning and summarization.arXiv preprint arXiv:2406.14732,
-
[4]
Chi-Min Chan, Chunpu Xu, Ruibin Yuan, Hongyin Luo, Wei Xue, Yike Guo, and Jie Fu. Rq-rag: Learning to refine queries for retrieval augmented generation.arXiv preprint arXiv:2404.00610,
-
[5]
Wenhu Chen, Hanwen Zha, Zhiyu Chen, Wenhan Xiong, Hong Wang, and William Wang. Hy- bridqa: A dataset of multi-hop question answering over tabular and textual data.arXiv preprint arXiv:2004.07347,
-
[6]
Improving retrieval-augmented generation through multi-agent reinforcement learning
10 Paper under review Yiqun Chen, Lingyong Yan, Weiwei Sun, Xinyu Ma, Yi Zhang, Shuaiqiang Wang, Dawei Yin, Yiming Yang, and Jiaxin Mao. Improving retrieval-augmented generation through multi-agent reinforcement learning.arXiv preprint arXiv:2501.15228,
-
[7]
Rag-based question answering over heterogeneous data and text.arXiv preprint arXiv:2412.07420,
Philipp Christmann and Gerhard Weikum. Rag-based question answering over heterogeneous data and text.arXiv preprint arXiv:2412.07420,
-
[8]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. From local to global: A graph rag approach to query-focused summarization.arXiv preprint arXiv:2404.16130,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Retrieval-Augmented Generation for Large Language Models: A Survey
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, and Haofen Wang. Retrieval-augmented generation for large language models: A survey.arXiv preprint arXiv:2312.10997,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Re2g: Retrieve, rerank, generate.arXiv preprint arXiv:2207.06300,
Michael Glass, Gaetano Rossiello, Md Faisal Mahbub Chowdhury, Ankita Rajaram Naik, Pengshan Cai, and Alfio Gliozzo. Re2g: Retrieve, rerank, generate.arXiv preprint arXiv:2207.06300,
-
[11]
Large Language Model based Multi-Agents: A Survey of Progress and Challenges
Taicheng Guo, Xiuying Chen, Yaqi Wang, Ruidi Chang, Shichao Pei, Nitesh V Chawla, Olaf Wiest, and Xiangliang Zhang. Large language model based multi-agents: A survey of progress and challenges.arXiv preprint arXiv:2402.01680, 2024a. Yue Guo and Yi Yang. Econnli: evaluating large language models on economics reasoning.arXiv preprint arXiv:2407.01212,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
LightRAG: Simple and Fast Retrieval-Augmented Generation
Zirui Guo, Lianghao Xia, Yanhua Yu, Tu Ao, and Chao Huang. Lightrag: Simple and fast retrieval- augmented generation.arXiv preprint arXiv:2410.05779, 2024b. Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, et al. Metagpt: Meta programming for a multi-agent collabora...
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Grag: Graph retrieval- augmented generation.arXiv preprint arXiv:2405.16506,
Yuntong Hu, Zhihan Lei, Zheng Zhang, Bo Pan, Chen Ling, and Liang Zhao. Grag: Graph retrieval- augmented generation.arXiv preprint arXiv:2405.16506,
-
[14]
Md Ashraful Islam, Mohammed Eunus Ali, and Md Rizwan Parvez. Mapcoder: Multi-agent code generation for competitive problem solving.arXiv preprint arXiv:2405.11403,
-
[15]
11 Paper under review Soyeong Jeong, Jinheon Baek, Sukmin Cho, Sung Ju Hwang, and Jong C Park. Adaptive-rag: Learning to adapt retrieval-augmented large language models through question complexity.arXiv preprint arXiv:2403.14403,
-
[16]
Active retrieval augmented generation
Zhengbao Jiang, Frank F Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. Active retrieval augmented generation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 7969–7992,
work page 2023
-
[17]
Flashrag: A modular toolkit for efficient retrieval-augmented generation research
Jiajie Jin, Yutao Zhu, Zhicheng Dou, Guanting Dong, Xinyu Yang, Chenghao Zhang, Tong Zhao, Zhao Yang, and Ji-Rong Wen. Flashrag: A modular toolkit for efficient retrieval-augmented generation research. InCompanion Proceedings of the ACM on Web Conference 2025, pp. 737– 740,
work page 2025
-
[18]
Prefix-Tuning: Optimizing Continuous Prompts for Generation
Xiang Lisa Li and Percy Liang. Prefix-tuning: Optimizing continuous prompts for generation.arXiv preprint arXiv:2101.00190,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Pei Liu, Xin Liu, Ruoyu Yao, Junming Liu, Siyuan Meng, Ding Wang, and Jun Ma. Hm-rag: Hierar- chical multi-agent multimodal retrieval augmented generation.arXiv preprint arXiv:2504.12330,
-
[20]
Haoran Luo, Zichen Tang, Shiyao Peng, Yikai Guo, Wentai Zhang, Chenghao Ma, Guanting Dong, Meina Song, Wei Lin, Yifan Zhu, et al. Chatkbqa: A generate-then-retrieve framework for knowledge base question answering with fine-tuned large language models.arXiv preprint arXiv:2310.08975,
-
[21]
Graph- constrained reasoning: Faithful reasoning on knowledge graphs with large language models
Linhao Luo, Zicheng Zhao, Gholamreza Haffari, Yuan-Fang Li, Chen Gong, and Shirui Pan. Graph- constrained reasoning: Faithful reasoning on knowledge graphs with large language models. arXiv preprint arXiv:2410.13080,
-
[22]
Shengjie Ma, Chengjin Xu, Xuhui Jiang, Muzhi Li, Huaren Qu, Cehao Yang, Jiaxin Mao, and Jian Guo. Think-on-graph 2.0: Deep and faithful large language model reasoning with knowledge- guided retrieval augmented generation.arXiv preprint arXiv:2407.10805,
-
[23]
Costas Mavromatis and George Karypis. Gnn-rag: Graph neural retrieval for large language model reasoning.arXiv preprint arXiv:2405.20139,
-
[24]
Graph retrieval-augmented generation: A survey.arXiv preprint arXiv:2408.08921,
Boci Peng, Yun Zhu, Yongchao Liu, Xiaohe Bo, Haizhou Shi, Chuntao Hong, Yan Zhang, and Siliang Tang. Graph retrieval-augmented generation: A survey.arXiv preprint arXiv:2408.08921,
-
[25]
Metaqa: Combining expert agents for multi- skill question answering.arXiv preprint arXiv:2112.01922,
Haritz Puerto, G¨ozde G¨ul S ¸ahin, and Iryna Gurevych. Metaqa: Combining expert agents for multi- skill question answering.arXiv preprint arXiv:2112.01922,
-
[26]
Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG
12 Paper under review Aditi Singh, Abul Ehtesham, Saket Kumar, and Tala Talaei Khoei. Agentic retrieval-augmented generation: A survey on agentic rag.arXiv preprint arXiv:2501.09136,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Multi-Agent Collaboration Mechanisms: A Survey of LLMs
Khanh-Tung Tran, Dung Dao, Minh-Duong Nguyen, Quoc-Viet Pham, Barry O’Sullivan, and Hoang D Nguyen. Multi-agent collaboration mechanisms: A survey of llms.arXiv preprint arXiv:2501.06322,
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Ruiyi Yang, Hao Xue, Imran Razzak, Hakim Hacid, and Flora D Salim. Beyond single pass, looping through time: Kg-irag with iterative knowledge retrieval.arXiv preprint arXiv:2503.14234,
-
[29]
HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W Cohen, Ruslan Salakhutdinov, and Christopher D Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering.arXiv preprint arXiv:1809.09600,
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Evaluation of retrieval- augmented generation: A survey.arXiv preprint arXiv:2405.07437,
Hao Yu, Aoran Gan, Kai Zhang, Shiwei Tong, Qi Liu, and Zhaofeng Liu. Evaluation of retrieval- augmented generation: A survey.arXiv preprint arXiv:2405.07437,
-
[31]
Retrieval-augmented generation across heterogeneous knowledge
Wenhao Yu. Retrieval-augmented generation across heterogeneous knowledge. InProceedings of the 2022 conference of the North American chapter of the association for computational linguis- tics: human language technologies: student research workshop, pp. 52–58,
work page 2022
-
[32]
Xiaohan Yu, Pu Jian, and Chong Chen. Tablerag: A retrieval augmented generation framework for heterogeneous document reasoning.arXiv preprint arXiv:2506.10380,
-
[33]
Retrieval-Augmented Generation for AI-Generated Content: A Survey
Penghao Zhao, Hailin Zhang, Qinhan Yu, Zhengren Wang, Yunteng Geng, Fangcheng Fu, Ling Yang, Wentao Zhang, and Bin Cui. Retrieval-augmented generation for ai-generated content: A survey.arXiv preprint arXiv:2402.19473,
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Fengbin Zhu, Wenqiang Lei, Youcheng Huang, Chao Wang, Shuo Zhang, Jiancheng Lv, Fuli Feng, and Tat-Seng Chua. Tat-qa: A question answering benchmark on a hybrid of tabular and textual content in finance.arXiv preprint arXiv:2105.07624, 2021a. Fengbin Zhu, Wenqiang Lei, Chao Wang, Jianming Zheng, Soujanya Poria, and Tat-Seng Chua. Retrieving and reading: A...
-
[35]
Jingwei Zuo, Maksim Velikanov, Ilyas Chahed, Younes Belkada, Dhia Eddine Rhayem, Guillaume Kunsch, Hakim Hacid, Hamza Yous, Brahim Farhat, Ibrahim Khadraoui, et al. Falcon-h1: A family of hybrid-head language models redefining efficiency and performance.arXiv preprint arXiv:2507.22448,
-
[36]
relies on invariants (T1)–(T3), which are satisfied by construction in the HSEQ adapters (offsets and row indices/ordering are recorded; triplets are stored verbatim). Ad- missibility is a regularity condition stating that an orderρexists (often paragraph/row-first) placing supporting segments early; in practice this is further improved by guidance. Assum...
work page 2048
-
[37]
Takeaway.Guidance steers the iterator to a high-yield paragraph in the first step, which already contains the sufficient evidence (film identity and source novel). Subsequent steps provide cor- roboration from structured rows. The provenance inκ(M τ)makes the final answer auditable: the paragraphp 6df9c849explicitly tiesNight Watch(2004, Bekmambetov) to t...
work page 2004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.