DenoGrad: A Gradient-Based Framework for Data Refinement in Tabular and Time-Series Learning
Pith reviewed 2026-05-17 22:43 UTC · model grok-4.3
The pith
DenoGrad refines noisy data by optimizing inputs via gradients from a fixed pretrained neural network, improving predictions on tabular and time-series tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DenoGrad is a gradient-based framework for data refinement that leverages a pretrained neural network to iteratively correct noisy observations by optimizing the input space while keeping the model fixed, applicable to tabular regression and time-series forecasting with a consensus-based strategy for temporally coherent updates, yielding consistent improvements in downstream predictive performance while preserving the statistical structure on ten real-world datasets and improving generalization in clean data.
What carries the argument
Gradient-based optimization of the input data using a fixed pretrained neural network to reduce prediction loss.
If this is right
- Refined data leads to better predictive performance in downstream tasks.
- Statistical structure including distributions and correlations remains largely unchanged.
- Nominally clean datasets can see improved generalization as a regularization effect.
- The approach applies to both tabular and sequential data with appropriate adjustments for coherence.
- Model-guided refinement becomes a practical tool in data-centric machine learning.
Where Pith is reading between the lines
- Extending this to other modalities like images or text could broaden its use if suitable models are available.
- If the pretrained model has biases, the data adjustments might embed those biases into the refined dataset.
- Integrating this into standard preprocessing pipelines could reduce reliance on manual data cleaning steps.
- Experiments with controlled synthetic noise would help isolate whether corrections target true noise or model-specific issues.
Load-bearing premise
That small gradient-driven adjustments to the input data correct genuine noise rather than introducing new artifacts or overfitting to the fixed model's current biases.
What would settle it
Observing that on datasets with known noise levels the method either fails to improve predictions or significantly distorts the data's statistical properties would challenge the central claim.
Figures

























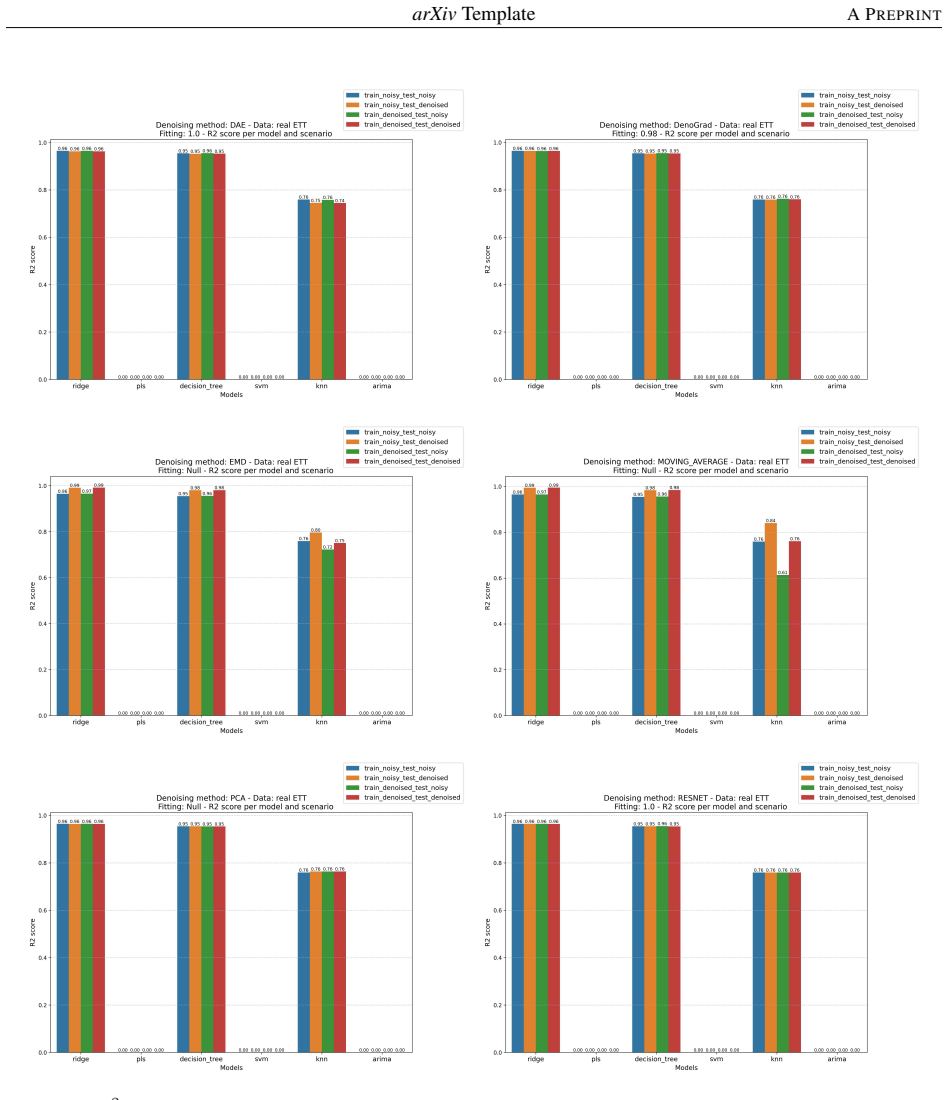


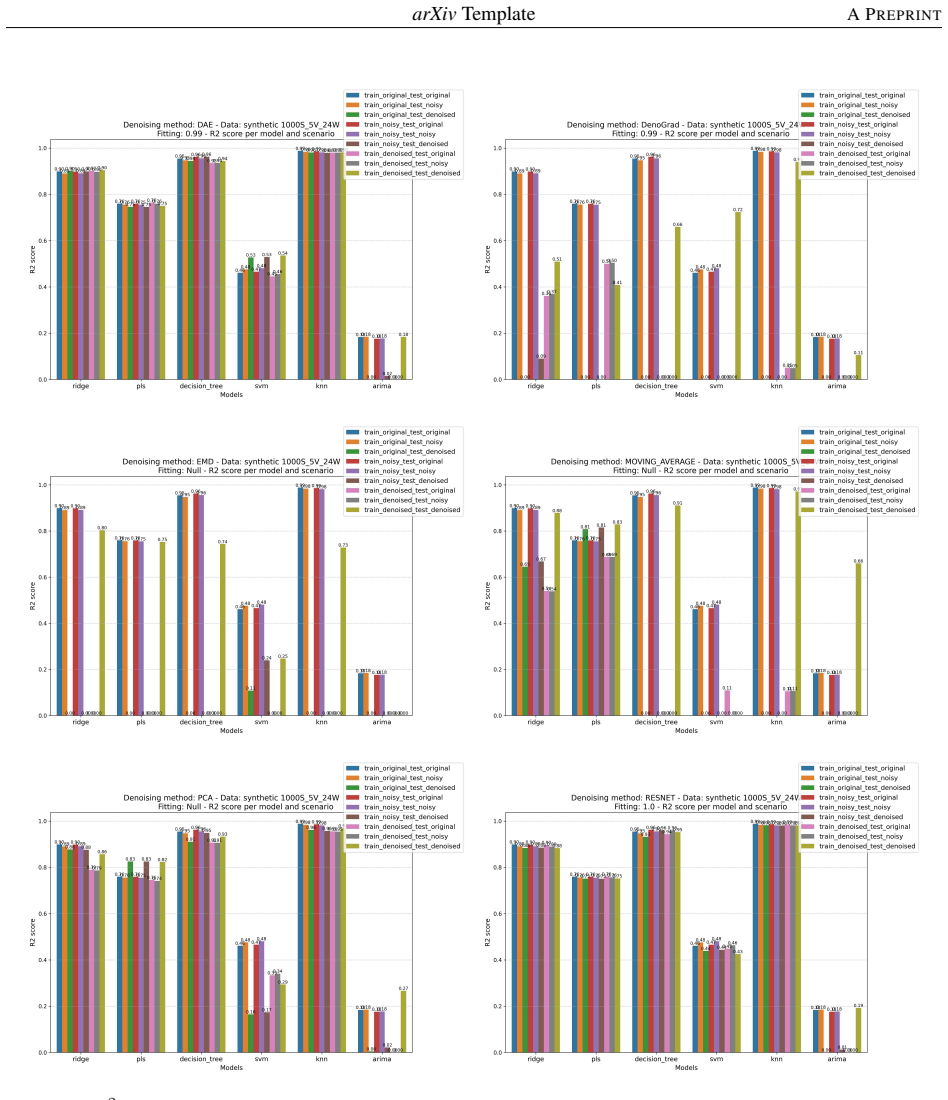

read the original abstract
In the Data-Centric Artificial Intelligence (AI) paradigm, improving data quality is essential for robust machine learning. However, many denoising methods rely on rigid statistical assumptions or require clean reference data, which limits their applicability in real-world scenarios. In this work, we propose DenoGrad, a gradient-based framework for data refinement that leverages a pretrained neural network to iteratively correct noisy observations by optimizing the input space while keeping the model fixed. DenoGrad is applicable to both tabular regression and time-series forecasting, and incorporates a consensus-based strategy to ensure temporally coherent updates in sequential settings. Experiments on ten real-world datasets show that the proposed approach yields consistent improvements in downstream predictive performance while preserving the statistical structure of the data, as measured by distributional and correlation-based metrics. In addition, DenoGrad can improve generalization in nominally clean datasets, acting as a form of dataset-level regularization. These results support model-guided data refinement as a practical component of data-centric machine learning workflows. Code is available at: https://github.com/ari-dasci/S-DenoGrad.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DenoGrad, a gradient-based framework for refining noisy tabular and time-series data. A pretrained neural network is held fixed while input observations are iteratively adjusted via gradients to minimize loss; a consensus mechanism enforces temporal coherence for sequential data. Experiments on ten real-world datasets report consistent gains in downstream predictive performance together with preservation of distributional and correlation-based statistical structure. The method is also claimed to improve generalization on nominally clean data by acting as dataset-level regularization. Code is released at the provided GitHub repository.
Significance. If the reported gains prove robust and independent of the fixed model's inductive biases, the approach would offer a practical, reference-free tool for data-centric workflows in regression and forecasting. The explicit attention to statistical-structure preservation and the public code release are positive features that support reproducibility and further testing. However, the significance remains provisional until the central claim—that gradient updates correct genuine noise rather than model-specific artifacts—is more rigorously isolated from confounding factors.
major comments (3)
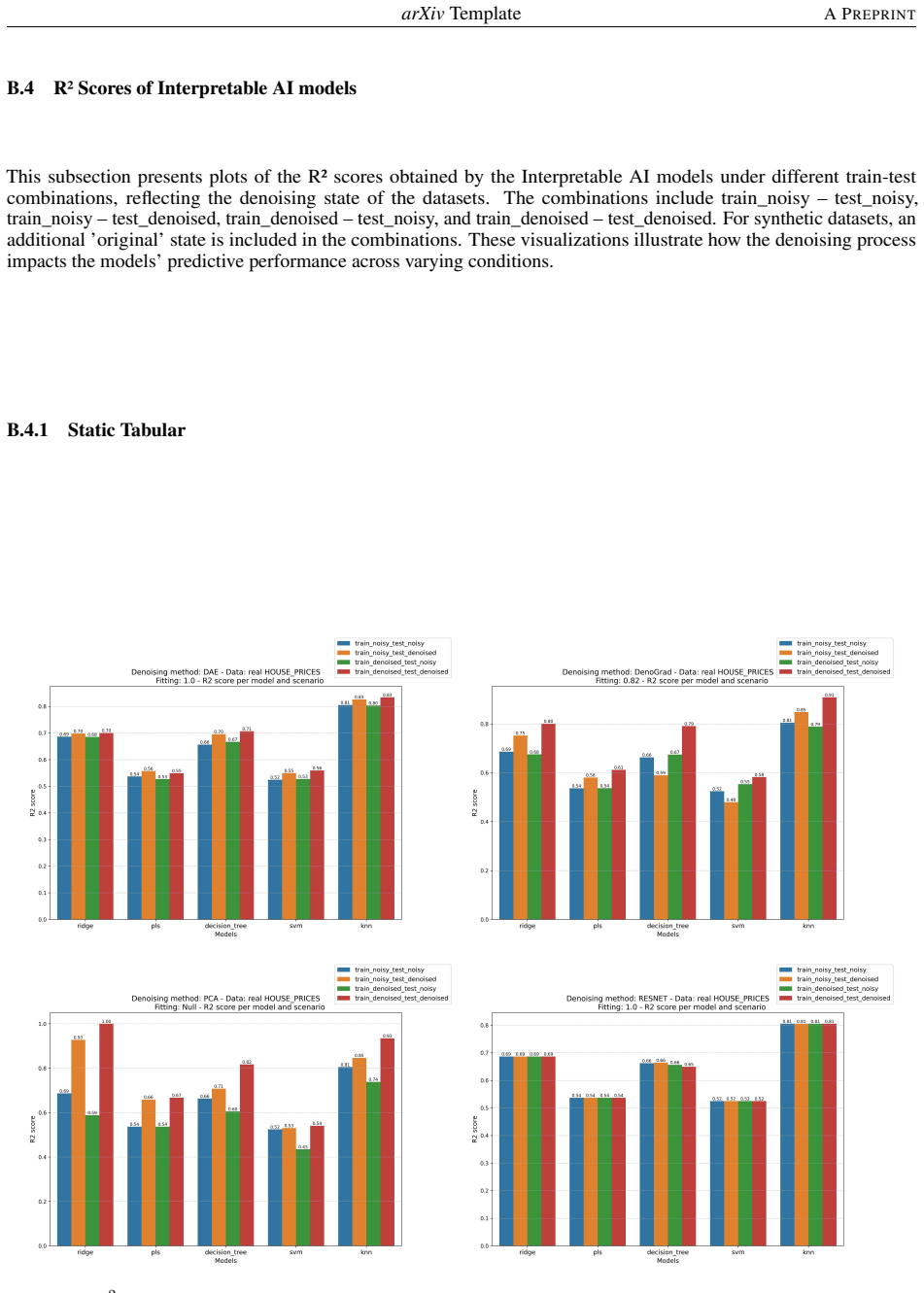
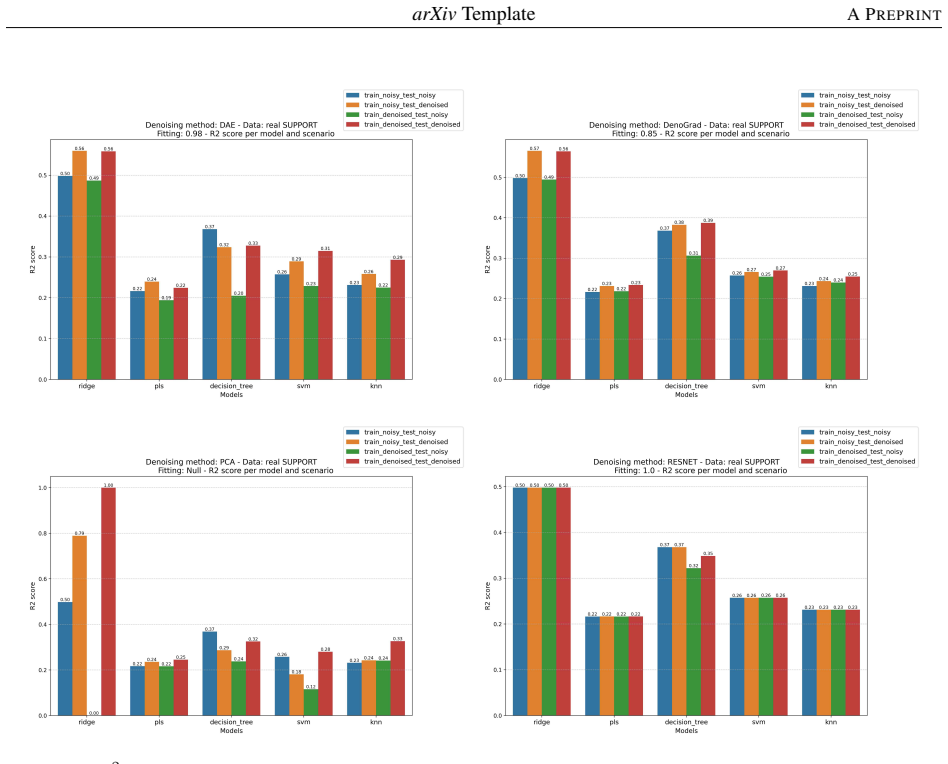
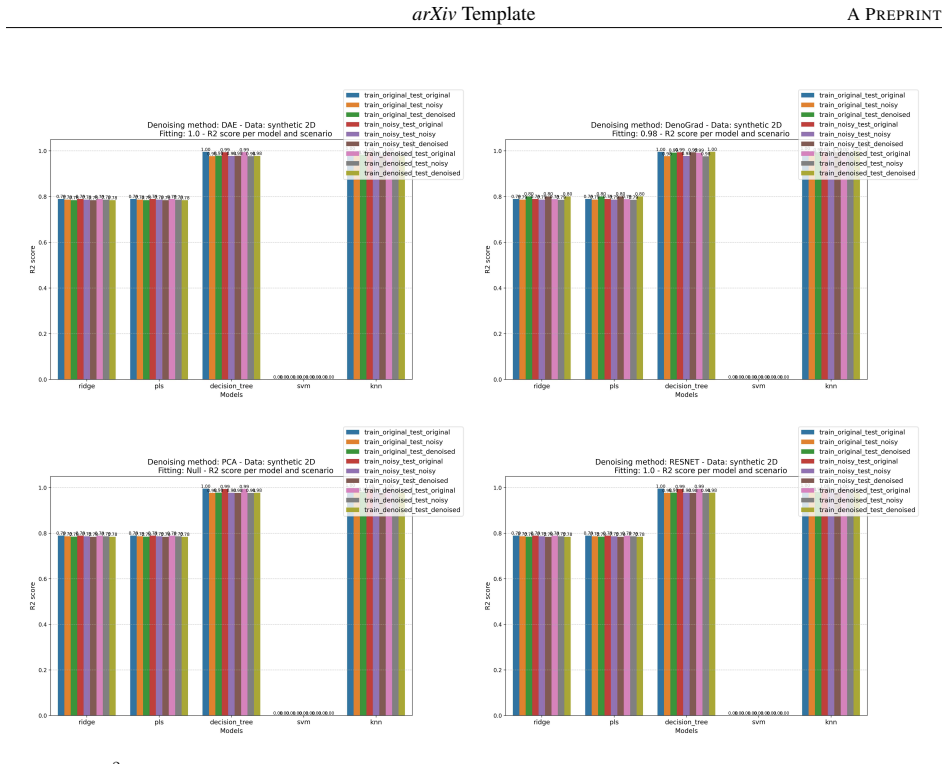
- [§5] §5 (Experiments): the headline claim of 'consistent improvements across ten datasets' is presented without statistical significance tests, confidence intervals, or a clear description of baseline selection and hyperparameter protocols. This omission prevents assessment of whether the gains exceed what could arise from selection effects or favorable tuning.
- [§4.1] §4.1 (Method): the optimization keeps the network fixed and updates inputs to reduce loss, yet no diagnostic is supplied to distinguish recovery of true signal from alignment with the model's current decision boundaries. Because downstream evaluation uses models likely similar to the fixed one, the reported gains do not yet rule out overfitting to model-specific biases.
- [§4.2] §4.2 (Consensus strategy): the temporal-coherence mechanism is introduced to avoid incoherent updates, but the manuscript provides neither an ablation removing the consensus step nor quantitative metrics showing its effect on both predictive performance and correlation preservation.
minor comments (3)
- [§3] Notation for the gradient step size and iteration count should be introduced once in §3 and used consistently thereafter; currently the symbols appear only in the experimental protocol.
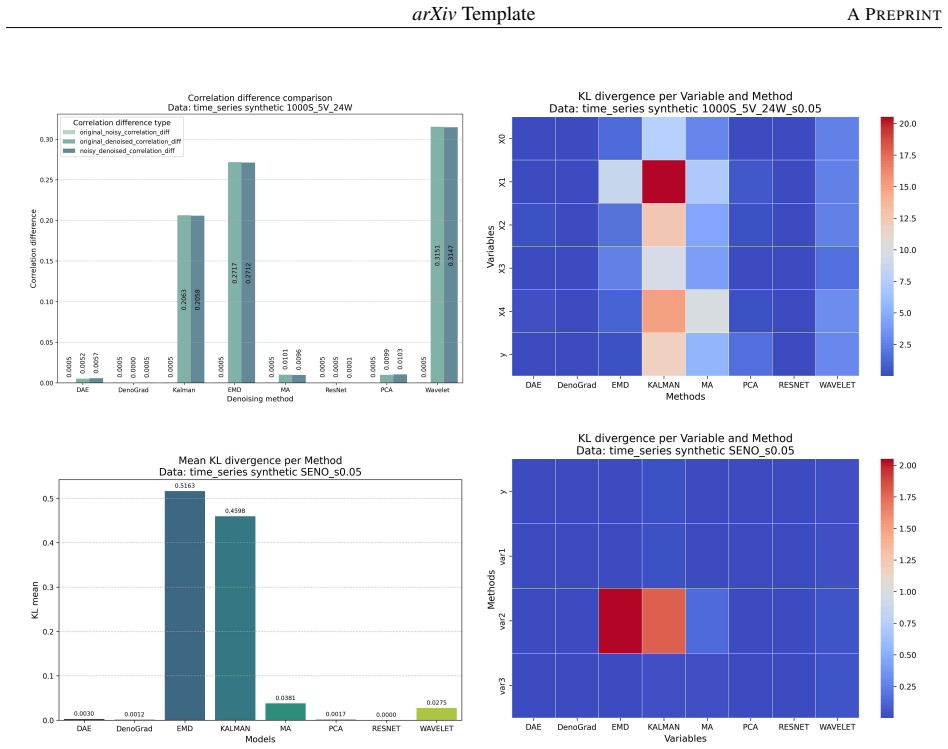
- [Figures] Figure captions for the distributional and correlation plots should explicitly state the exact metrics (e.g., Wasserstein distance, Pearson correlation) and the number of Monte-Carlo runs used to generate error bars.
- [Code availability] The GitHub repository is welcome, but the paper should list the precise hyperparameter values and random seeds employed for each dataset so that the released code can be verified without additional reverse-engineering.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and describe the revisions we will implement to improve the manuscript's rigor and clarity.
read point-by-point responses
-
Referee: §5 (Experiments): the headline claim of 'consistent improvements across ten datasets' is presented without statistical significance tests, confidence intervals, or a clear description of baseline selection and hyperparameter protocols. This omission prevents assessment of whether the gains exceed what could arise from selection effects or favorable tuning.
Authors: We agree that additional statistical analysis is needed to support the claims. In the revised manuscript we will add paired statistical tests (t-tests or Wilcoxon signed-rank) with p-values across the ten datasets, report 95% confidence intervals on the performance deltas, and expand the experimental protocol section to explicitly describe baseline selection criteria and hyperparameter search procedures for both the fixed refinement model and all downstream evaluators. These changes will allow readers to evaluate whether the gains are robust to selection or tuning effects. revision: yes
-
Referee: §4.1 (Method): the optimization keeps the network fixed and updates inputs to reduce loss, yet no diagnostic is supplied to distinguish recovery of true signal from alignment with the model's current decision boundaries. Because downstream evaluation uses models likely similar to the fixed one, the reported gains do not yet rule out overfitting to model-specific biases.
Authors: This is a substantive concern. While the original experiments already evaluate refined data on multiple downstream models, we will add a dedicated diagnostic subsection in the revision. This will include (i) cross-architecture evaluation using models whose inductive biases differ from the fixed refinement network and (ii) quantitative comparison of input-feature shifts and decision-boundary alignment before and after refinement. These additions will help separate genuine signal recovery from model-specific alignment. revision: yes
-
Referee: §4.2 (Consensus strategy): the temporal-coherence mechanism is introduced to avoid incoherent updates, but the manuscript provides neither an ablation removing the consensus step nor quantitative metrics showing its effect on both predictive performance and correlation preservation.
Authors: We accept that an explicit ablation is required. In the revised manuscript we will include an ablation study on the time-series datasets that compares full DenoGrad against the variant without the consensus step. We will report both predictive performance metrics (e.g., MSE, MAE) and statistical-structure metrics (Pearson correlations, distributional distances) for both variants, thereby quantifying the consensus mechanism's contribution to coherence and accuracy. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper introduces DenoGrad as a gradient-based data refinement procedure that keeps a pretrained model fixed while iteratively adjusting inputs to reduce loss, with a consensus strategy for time-series coherence. All central claims rest on empirical results from experiments on ten real-world datasets, reporting downstream performance gains and preservation of distributional/correlation metrics. No equations or steps reduce by construction to the method's own fitted values or inputs; there are no self-definitional relations, fitted parameters renamed as predictions, or load-bearing self-citations that would force the reported improvements. The derivation and validation are self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- gradient step size and iteration count
axioms (1)
- domain assumption A pretrained model on the noisy data still produces gradients that point toward useful corrections rather than amplifying existing errors.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DenoGrad computes gradients of the loss with respect to the inputs themselves... (x′, y′) = (x, y) − ∇x,y L(f(x), y) · μ
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Experiments on ten real-world datasets show consistent improvements... while preserving statistical structure
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
M. Sidahmed, Attribute noise-sensitivity impact: Model performance and feature ranking, in: Americas Confer- ence on Information Systems, 2008, p. no info. URLhttps://api.semanticscholar.org/CorpusID:2960577
work page 2008
- [2]
-
[3]
Y . Li, H. Han, S. Shan, X. Chen, Disc: Learning from noisy labels via dynamic instance-specific selection and correction, 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2023) 24070– 24079. URLhttps://api.semanticscholar.org/CorpusID:260068694
work page 2023
-
[4]
A. Papenmeier, D. Kern, G. Englebienne, C. Seifert, It’s complicated: The relationship between user trust, model accuracy and explanations in ai, ACM Trans. Comput.-Hum. Interact. (2022).doi:10.1145/3495013. URLhttps://doi.org/10.1145/3495013
-
[5]
A. Mokari, S. Eiserloh, O. Ryabchykov, U. Neugebauer, T. Bocklitz, A comparative study of robustness to noise and interpretability in u-net-based denoising of raman spectra., Spectrochimica acta. Part A, Molecular and biomolecular spectroscopy 344 Pt 1 (2025) 126577. URLhttps://api.semanticscholar.org/CorpusID:279965738
work page 2025
-
[6]
Z. He, Y . Wang, Y . Yang, P. Sun, L. Wu, H. Bai, J. Gong, R. Hong, M. Zhang, Double correction framework for denoising recommendation, in: Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2024, p. 1062–1072.doi:10.1145/3637528.3671692. URLhttps://doi.org/10.1145/3637528.3671692
- [7]
-
[8]
Larsen-Ledet, Embracing data noise, in: microsoft, 2023, p
I. Larsen-Ledet, Embracing data noise, in: microsoft, 2023, p. no info. URLhttps://api.semanticscholar.org/CorpusID:259300333
work page 2023
-
[9]
R. Hasan, C. H. Chu, Noise in datasets: What are the impacts on classification performance?, in: Proceedings of the 11th International Conference on Pattern Recognition Applications and Methods - ICPRAM, INSTICC, SciTePress, 2022, pp. 163–170.doi:10.5220/0010782200003122
-
[10]
D. García-Gil, J. Luengo, S. García, F. Herrera, Enabling smart data: noise filtering in big data classification, Information Sciences 479 (2019) 135–152
work page 2019
-
[11]
K. W. Al-Sabbagh, M. Staron, R. Hebig, Improving test case selection by handling class and attribute noise, J. Syst. Softw. 183 (2021) 111093. URLhttps://api.semanticscholar.org/CorpusID:244245120
work page 2021
-
[12]
R. K. L. Kennedy, J. M. Johnson, T. M. Khoshgoftaar, The effects of class label noise on highly-imbalanced big data, 2021 IEEE 33rd International Conference on Tools with Artificial Intelligence (ICTAI) (2021) 1427–1433. URLhttps://api.semanticscholar.org/CorpusID:245388536
work page 2021
-
[13]
E, Statistical physics, plasmas, fluids, and related interdisciplinary topics 48 1 (1993) R13–R16
Schreiber, Determination of the noise level of chaotic time series., Physical review. E, Statistical physics, plasmas, fluids, and related interdisciplinary topics 48 1 (1993) R13–R16. URLhttps://api.semanticscholar.org/CorpusID:12164904
work page 1993
-
[14]
J. M. Johnson, T. M. Khoshgoftaar, A survey on classifying big data with label noise, ACM Journal of Data and Information Quality 14 (2022) 1 – 43. URLhttps://api.semanticscholar.org/CorpusID:248070196
work page 2022
- [15]
-
[16]
C. M. Bishop, C. S. Quazaz, Regression with input-dependent noise: A bayesian treatment, in: Neural Information Processing Systems, 1996, p. no info. URLhttps://api.semanticscholar.org/CorpusID:14474914
work page 1996
-
[17]
P. W. Goldberg, C. K. I. Williams, C. M. Bishop, Regression with input-dependent noise: A gaussian process treatment, in: Neural Information Processing Systems, 1997, p. no info. URLhttps://api.semanticscholar.org/CorpusID:7482528 55 arXivTemplateA PREPRINT
work page 1997
-
[18]
S. Shankar, D. Sheldon, T. Sun, J. Pickering, T. G. Dietterich, Three-quarter sibling regression for denoising observational data, in: Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI-19, International Joint Conferences on Artificial Intelligence Organization, 2019, pp. 5960–5966. doi: 10.24963/ijcai.2019/8...
-
[19]
P. Chaudhary, I. Chauhan, B. R. Manoj, M. R. Bhatnagar, Linear regression-based channel estimation for non- gaussian noise, 2024 IEEE 99th Vehicular Technology Conference (VTC2024-Spring) (2024) 1–6. URLhttps://api.semanticscholar.org/CorpusID:272858899
work page 2024
-
[20]
S. G. Kwak, J. H. Kim, Central limit theorem: the cornerstone of modern statistics, Korean journal of anesthesiol- ogy 70 (2) (2017) 144
work page 2017
-
[21]
S. Santhosh, P. Soori, V . Shashidhar, Impact of additive noise on information loss characteristics of datasets, 2023 International Conference on the Confluence of Advancements in Robotics, Vision and Interdisciplinary Technology Management (IC-RVITM) (2023) 1–8. URLhttps://api.semanticscholar.org/CorpusID:267772787
work page 2023
-
[22]
E. Barnett, O. Kaiser, J. Masci, E. C. Wit, S. Fulda, Generative models for periodicity detection in noisy signals, Clocks & Sleep 6 (3) (2024) 359–388
work page 2024
-
[23]
E. Jafarigol, T. Trafalis, The paradox of noise: An empirical study of noise-infusion mechanisms to improve generalization, stability, and privacy in federated learning (2023).arXiv:2311.05790. URLhttps://arxiv.org/abs/2311.05790
- [24]
-
[25]
S. Wang, H. Chen, A novel deep learning method for the classification of power quality disturbances using deep convolutional neural network, Applied energy 235 (2019) 1126–1140
work page 2019
-
[26]
A. Barredo Arrieta, N. Díaz-Rodríguez, J. Del Ser, A. Bennetot, S. Tabik, A. Barbado, S. Garcia, S. Gil- Lopez, D. Molina, R. Benjamins, R. Chatila, F. Herrera, Explainable artificial intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI, Information Fusion 58 (2020) 82–115. doi: 10.1016/j.inffus.2019.12.012
-
[27]
D. Gunning, Explainable artificial intelligence (xai), Defense advanced research projects agency (DARPA), nd Web 2 (2) (2017) 1
work page 2017
-
[28]
Towards A Rigorous Science of Interpretable Machine Learning
F. Doshi-Velez, B. Kim, Towards a rigorous science of interpretable machine learning, arXiv preprint arXiv:1702.08608 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[29]
A. E. Hoerl, R. W. Kennard, Ridge regression: Biased estimation for nonorthogonal problems, Technometrics 12 (1) (1970) 55–67
work page 1970
-
[30]
S. Wold, A. Ruhe, H. Wold, W. Dunn, Iii, The collinearity problem in linear regression. the partial least squares (pls) approach to generalized inverses, SIAM Journal on Scientific and Statistical Computing 5 (3) (1984) 735–743
work page 1984
-
[31]
L. Breiman, J. Friedman, R. A. Olshen, C. J. Stone, Classification and regression trees, Routledge, 2017
work page 2017
-
[32]
H. Drucker, C. J. Burges, L. Kaufman, A. Smola, V . Vapnik, Support vector regression machines, Advances in neural information processing systems 9 (1996)
work page 1996
-
[33]
E. Fix, J. L. Hodges Jr, Discriminatory analysis. nonparametric discrimination: Consistency properties, Tech. rep., USA Air Force School of Aviation Medicine, Randolph Field (1951)
work page 1951
-
[34]
G. E. Box, G. M. Jenkins, Time series analysis: Forecasting and control, Holden-Day, 1970
work page 1970
- [35]
-
[36]
L. Peracchio, G. Nicora, T. M. Buonocore, R. Bellazzi, E. Parimbelli, Do you trust your model explanations? an analysis of xai performance under dataset shift, in: International Conference on Artificial Intelligence in Medicine, Springer, 2024, pp. 257–266
work page 2024
-
[37]
P. Milanfar, M. Delbracio, Denoising: a powerful building block for imaging, inverse problems and machine learning, Philosophical transactions. Series A, Mathematical, physical, and engineering sciences 383 (2024). URLhttps://api.semanticscholar.org/CorpusID:272550819
work page 2024
-
[38]
X. Gu, Y .-J. Wang, X. Zhu, C. Shi, Y . Guo, Y . Liu, J. Chen, Advancing humanoid locomotion: Mastering challenging terrains with denoising world model learning (2024).arXiv:2408.14472. URLhttps://arxiv.org/abs/2408.14472 56 arXivTemplateA PREPRINT
-
[39]
G. Frusque, O. Fink, Robust time series denoising with learnable wavelet packet transform, Advanced Engineering Informatics 62 (2024) 102669
work page 2024
-
[40]
D. Makwana, G. Deshmukh, O. Susladkar, S. Mittal, et al., Livenet: A novel network for real-world low-light image denoising and enhancement, in: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2024, pp. 5856–5865
work page 2024
-
[41]
P. Zhao, W. Zhang, X. Cao, X. Li, Denoising diffusion probabilistic model-enabled data augmentation method for intelligent machine fault diagnosis, Engineering Applications of Artificial Intelligence 139 (2025) 109520
work page 2025
-
[42]
L. P. F. Garcia, A. C. Lorena, A. C. P. de Leon Ferreira de Carvalho, A study on class noise detection and elimination, 2012 Brazilian Symposium on Neural Networks (2012) 13–18. URLhttps://api.semanticscholar.org/CorpusID:14146586
work page 2012
-
[43]
S. Zhou, Z. He, X. Chen, W. Chang, An anomaly detection method for uav based on wavelet decomposition and stacked denoising autoencoder, Aerospace 11 (5) (2024) 393
work page 2024
- [44]
-
[45]
J. Shi, K. Zhang, C. Guo, Y . Yang, Y . Xu, J. Wu, A survey of label-noise deep learning for medical image analysis, Medical Image Analysis 95 (2024) 103166.doi:https://doi.org/10.1016/j.media.2024.103166
-
[46]
A. Majumdar, Blind denoising autoencoder, IEEE transactions on neural networks and learning systems 30 (1) (2018) 312–317
work page 2018
-
[47]
A.-O. Boudraa, J.-C. Cexus, et al., Denoising via empirical mode decomposition, Proc. IEEE ISCCSP 4 (2006) (2006)
work page 2006
-
[48]
I. de Vries, A. de Jong, M. van der Hout-van der Jagt, J. van Laar, R. Vullings, Deep learning for sparse domain kalman filtering with applications on ecg denoising and motility estimation, IEEE Transactions on Biomedical Engineering 71 (8) (2024) 2321–2329.doi:10.1109/TBME.2024.3368105
-
[49]
Z. Shan, J. Yang, M. A. Sanjuán, C. Wu, H. Liu, A novel adaptive moving average method for signal denoising in strong noise background, The European Physical Journal Plus 137 (1) (2022) 50
work page 2022
-
[50]
W. Dong, M. Wo´ zniak, J. Wu, W. Li, Z. Bai, Denoising aggregation of graph neural networks by using principal component analysis, IEEE Transactions on Industrial Informatics 19 (3) (2023) 2385–2394. doi:10.1109/TII. 2022.3156658
work page doi:10.1109/tii 2023
-
[51]
H. Kang, C. Park, H. Yang, Evaluation of denoising performance of resnet deep learning model for ultrasound images corresponding to two frequency parameters, Bioengineering 11 (7) (2024) 723
work page 2024
-
[52]
C. Tian, M. Zheng, W. Zuo, B. Zhang, Y . Zhang, D. Zhang, Multi-stage image denoising with the wavelet transform, Pattern Recognition 134 (2023) 109050
work page 2023
-
[53]
D. L. Donoho, De-noising by soft-thresholding, IEEE transactions on information theory 41 (3) (2002) 613–627
work page 2002
-
[54]
W. S. McCulloch, W. Pitts, A logical calculus of the ideas immanent in nervous activity, The bulletin of mathemat- ical biophysics 5 (1943) 115–133
work page 1943
-
[55]
Z. L. Liu, Artificial neural networks, in: Artificial Intelligence for Engineers: Basics and Implementations, Springer, 2025, pp. 175–190
work page 2025
-
[56]
H. Robbins, S. Monro, A stochastic approximation method, The annals of mathematical statistics (1951) 400–407
work page 1951
-
[57]
K. Cho, B. van Merriënboer, C. Gulcehre, D. Bahdanau, F. Bougares, H. Schwenk, Y . Bengio, Learning phrase representations using RNN encoder–decoder for statistical machine translation, in: A. Moschitti, B. Pang, W. Daelemans (Eds.), Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Association for Computation...
work page doi:10.3115/v1/ 2014
-
[58]
R. Pascanu, T. Mikolov, Y . Bengio, On the difficulty of training recurrent neural networks, in: International conference on machine learning, Pmlr, 2013, pp. 1310–1318
work page 2013
-
[59]
S. Hochreiter, The vanishing gradient problem during learning recurrent neural nets and problem solutions, International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems 6 (02) (1998) 107–116
work page 1998
-
[60]
V . Nair, G. E. Hinton, Rectified linear units improve restricted boltzmann machines, in: Proceedings of the 27th international conference on machine learning (ICML-10), 2010, pp. 807–814
work page 2010
-
[61]
K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778. 57 arXivTemplateA PREPRINT
work page 2016
- [62]
-
[63]
S. Hochreiter, J. Schmidhuber, Long short-term memory, Neural computation 9 (8) (1997) 1735–1780
work page 1997
-
[64]
M. Beck, K. Pöppel, M. Spanring, A. Auer, O. Prudnikova, M. Kopp, G. Klambauer, J. Brandstetter, S. Hochreiter, xlstm: Extended long short-term memory, Advances in Neural Information Processing Systems 37 (2024) 107547–107603
work page 2024
-
[65]
J. J. Hopfield, Neural networks and physical systems with emergent collective computational abilities., Proceedings of the national academy of sciences 79 (8) (1982) 2554–2558
work page 1982
- [66]
-
[67]
J. van Doorn, A. Ly, M. Marsman, E.-J. Wagenmakers, Bayesian rank-based hypothesis testing for the rank sum test, the signed rank test, and spearman’sρ, Journal of Applied Statistics 47 (16) (2020) 2984–3006
work page 2020
-
[68]
harlfoxem, House Sales in King County, USA, Kaggle, https://www.kaggle.com/datasets/harlfoxem/housesalesprediction (2014)
work page 2014
-
[69]
N. Huu Tiep, Lattice-physics (PWR fuel assembly neutronics simulation results), UCI Machine Learning Reposi- tory, DOI: https://doi.org/10.24432/C5BK64 (2024)
-
[70]
A. Tsanas, M. Little, Parkinsons Telemonitoring, UCI Machine Learning Repository, DOI: https://doi.org/10.24432/C5ZS3N (2009)
-
[71]
B. S., R. Nagapadma, RT-IoT2022 , UCI Machine Learning Repository, DOI: https://doi.org/10.24432/C5P338 (2023)
-
[72]
Harrel, SUPPORT2, UCI Machine Learning Repository, DOI: https://doi.org/10.3886/ICPSR02957.v2 (2023)
F. Harrel, SUPPORT2, UCI Machine Learning Repository, DOI: https://doi.org/10.3886/ICPSR02957.v2 (2023)
-
[73]
W. U. API, Daily Climate time series data, Kaggle, URL: https://www.kaggle.com/datasets/sumanthvrao/daily- climate-time-series-data (2019)
work page 2019
-
[74]
H. Zhou, S. Zhang, J. Peng, S. Zhang, J. Li, H. Xiong, W. Zhang, Informer: Beyond efficient transformer for long sequence time-series forecasting, in: The Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, Virtual Conference, V ol. 35, AAAI Press, 2021, pp. 11106–11115
work page 2021
-
[75]
V . V . Venkitesh, Microsoft Stock- Time Series Analysis, Kaggle, URL: https://www.kaggle.com/datasets/vijayvvenkitesh/microsoft-stock-time-series-analysis (2021)
work page 2021
-
[76]
Y . Kopsinis, S. McLaughlin, Development of emd-based denoising methods inspired by wavelet thresholding, IEEE Transactions on signal Processing 57 (4) (2009) 1351–1362
work page 2009
-
[77]
J. Terrien, C. Marque, B. Karlsson, Automatic detection of mode mixing in empirical mode decomposition using non-stationarity detection: application to selecting imfs of interest and denoising, EURASIP Journal on Advances in Signal Processing 2011 (2011) 1–8
work page 2011
-
[78]
A.-O. Boudraa, J.-C. Cexus, Z. Saidi, Emd-based signal noise reduction, International Journal of Signal Processing 1 (1) (2004) 33–37
work page 2004
-
[79]
I. Daubechies, The wavelet transform, time-frequency localization and signal analysis, IEEE transactions on information theory 36 (5) (2002) 961–1005. 58
work page 2002
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.