Knowledge Graphs Generation from Cultural Heritage Texts: Combining LLMs and Ontological Engineering for Scholarly Debates
Pith reviewed 2026-05-17 22:21 UTC · model grok-4.3
The pith
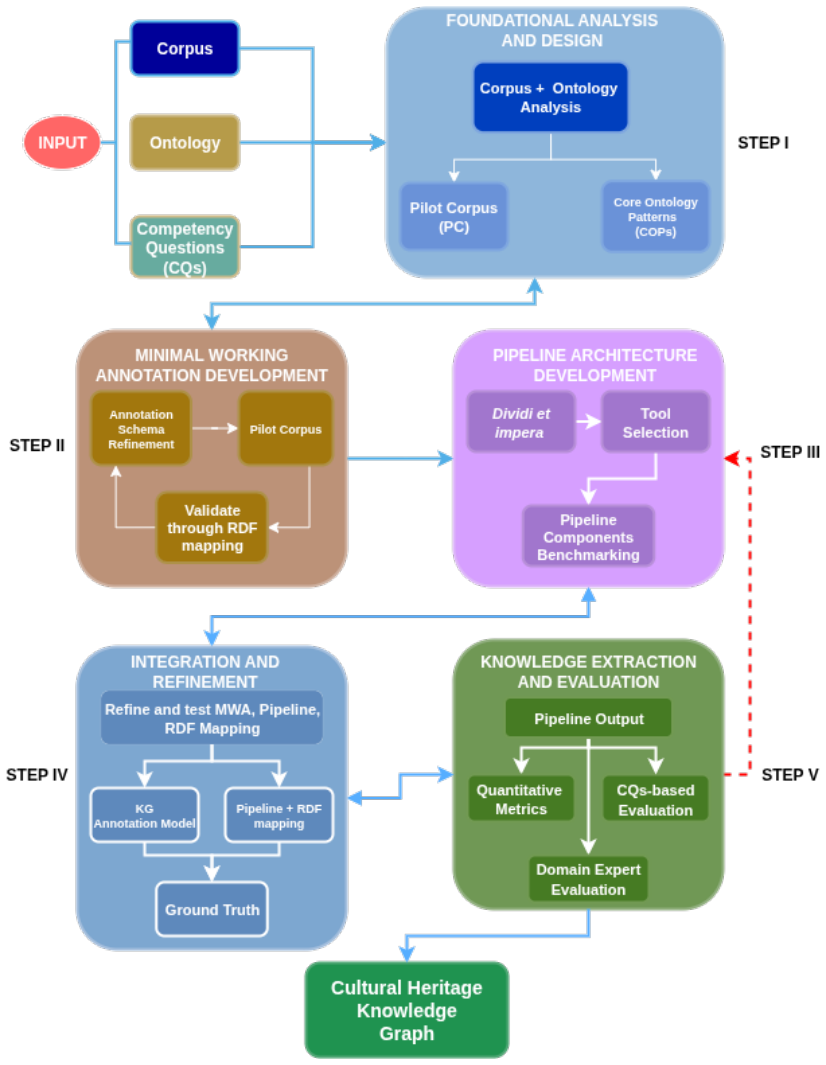
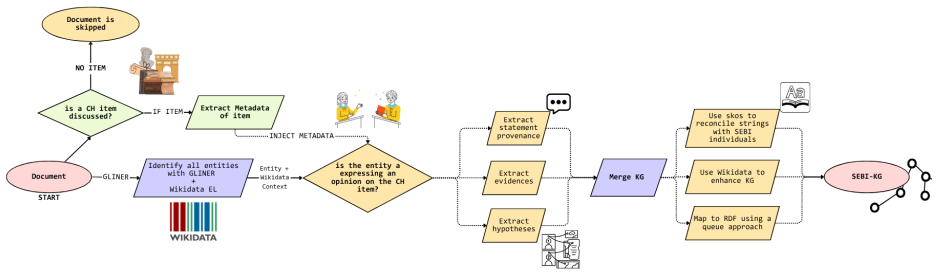
ATR4CH is a five-step methodology that guides large language models with cultural heritage ontologies to turn texts on scholarly debates into structured knowledge graphs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
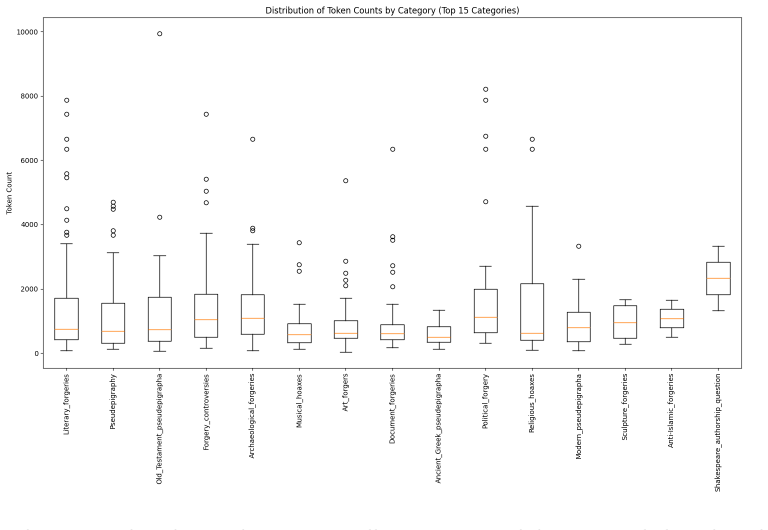
ATR4CH supplies the first systematic methodology for coordinating LLM-based extraction with Cultural Heritage ontologies by progressing through foundational analysis, annotation schema development, pipeline architecture, integration refinement, and comprehensive evaluation. In the authenticity assessment case study on Wikipedia articles, the sequential pipeline with Claude Sonnet 3.7, Llama 3.3 70B, and GPT-4o-mini reached F1 scores of 0.96-0.99 for metadata extraction, 0.7-0.8 for entity recognition, 0.65-0.75 for hypothesis extraction, 0.95-0.97 for evidence extraction, and 0.62 G-EVAL for discourse representation, with smaller models performing competitively.
What carries the argument
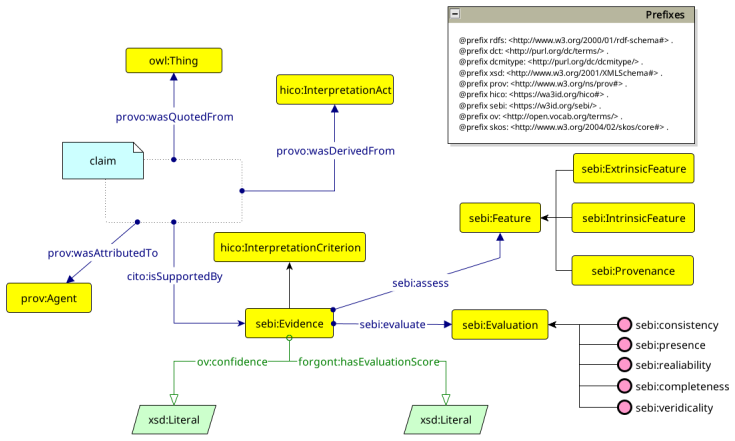
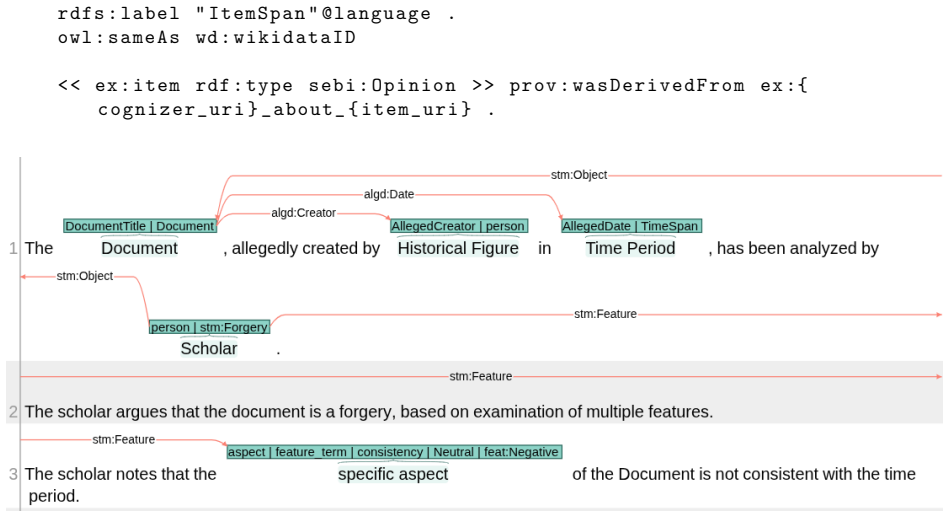
ATR4CH, the five-step adaptive text-to-RDF methodology that combines annotation models, ontological frameworks, and LLM-based extraction to convert unstructured cultural heritage texts into RDF knowledge graphs.
If this is right
- Cultural heritage institutions can convert textual knowledge into queryable knowledge graphs without prohibitive manual effort.
- Automated metadata enrichment and knowledge discovery become practical for large document collections.
- Smaller language models support cost-effective deployment while maintaining competitive extraction performance.
- The framework adapts across different cultural heritage domains and varying levels of institutional resources.
- Post-processing human oversight remains part of the workflow to finalize the knowledge graphs.
Where Pith is reading between the lines
- Testing ATR4CH on primary sources such as museum catalogs or historical records would show whether ontology guidance holds for text styles outside Wikipedia.
- Linking the resulting graphs to existing digital heritage platforms could enable ongoing updates as new debates appear in the literature.
- The same coordinated LLM-ontology pattern might transfer to other areas of contested knowledge such as legal opinions or scientific controversies.
- Wider adoption could lower the entry cost for smaller institutions to contribute to linked open data efforts in the cultural heritage sector.
Load-bearing premise
That large language model outputs guided by ontologies can reliably capture nuanced scholarly debates and discourse structures when the tests use only Wikipedia articles and rely on post-processing human oversight.
What would settle it
Applying the full ATR4CH pipeline to a collection of primary museum or archive documents on disputed artifacts and finding that expert review identifies more than 30 percent mismatch in extracted hypotheses or discourse structures compared with the Wikipedia results.
Figures






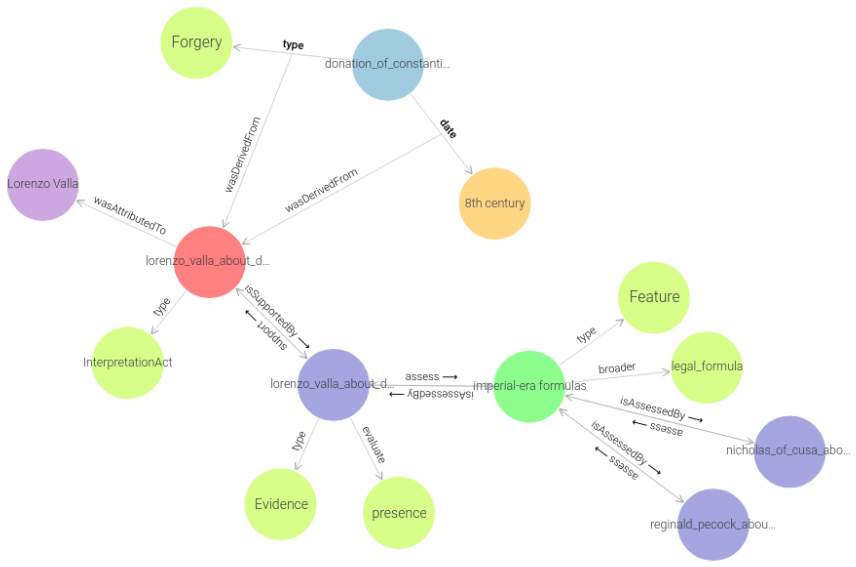
read the original abstract
Cultural Heritage texts contain rich knowledge that is difficult to query systematically due to the challenges of converting unstructured discourse into structured Knowledge Graphs (KGs). This paper introduces ATR4CH (Adaptive Text-to-RDF for Cultural Heritage), a systematic five-step methodology for Large Language Model-based Knowledge Extraction from Cultural Heritage documents. We validate the methodology through a case study on authenticity assessment debates. Methodology - ATR4CH combines annotation models, ontological frameworks, and LLM-based extraction through iterative development: foundational analysis, annotation schema development, pipeline architecture, integration refinement, and comprehensive evaluation. We demonstrate the approach using Wikipedia articles about disputed items (documents, artifacts...), implementing a sequential pipeline with three LLMs (Claude Sonnet 3.7, Llama 3.3 70B, GPT-4o-mini). Findings - The methodology successfully extracts complex Cultural Heritage knowledge: 0.96-0.99 F1 for metadata extraction, 0.7-0.8 F1 for entity recognition, 0.65-0.75 F1 for hypothesis extraction, 0.95-0.97 for evidence extraction, and 0.62 G-EVAL for discourse representation. Smaller models performed competitively, enabling cost-effective deployment. Originality - This is the first systematic methodology for coordinating LLM-based extraction with Cultural Heritage ontologies. ATR4CH provides a replicable framework adaptable across CH domains and institutional resources. Research Limitations - The produced KG is limited to Wikipedia articles. While the results are encouraging, human oversight is necessary during post-processing. Practical Implications - ATR4CH enables Cultural Heritage institutions to systematically convert textual knowledge into queryable KGs, supporting automated metadata enrichment and knowledge discovery.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ATR4CH, a five-step methodology (foundational analysis, annotation schema development, pipeline architecture, integration refinement, and comprehensive evaluation) that combines LLMs with Cultural Heritage ontologies to extract structured knowledge graphs from texts, with a focus on scholarly debates such as authenticity assessments. It validates the approach in a case study on Wikipedia articles about disputed items using Claude Sonnet 3.7, Llama 3.3 70B, and GPT-4o-mini, reporting F1 scores of 0.96-0.99 (metadata), 0.7-0.8 (entity recognition), 0.65-0.75 (hypothesis), 0.95-0.97 (evidence), and 0.62 G-EVAL (discourse).
Significance. If the central claims hold, ATR4CH would supply the first replicable framework for CH institutions to convert unstructured discourse into queryable KGs, enabling metadata enrichment and knowledge discovery. The manuscript earns credit for its concrete empirical metrics across three LLMs (including competitive results from smaller models), explicit acknowledgment of the need for human post-processing oversight, and presentation of a sequential pipeline that integrates annotation models with ontological frameworks.
major comments (1)
- [Case Study / Evaluation] Case Study / Evaluation section: All reported metrics (0.65-0.75 F1 for hypothesis extraction, 0.62 G-EVAL for discourse representation) derive exclusively from Wikipedia articles on disputed items. These are secondary, consensus-oriented summaries with explicit structure and lower ambiguity than primary CH sources such as excavation reports or scholarly monographs; this scope limitation directly weakens the replicability claim that ATR4CH supplies an adaptable framework across CH domains.
minor comments (3)
- [Abstract] Abstract: The findings paragraph reports '0.95-0.97 for evidence extraction' without specifying the metric; this should be clarified as F1 to maintain consistency with the other reported scores.
- [Findings] Findings: A summary table comparing F1 and G-EVAL scores across the three LLMs for each extraction task (metadata, entities, hypotheses, evidence, discourse) would improve readability and allow direct comparison of model performance.
- [Research Limitations] Research Limitations: The statement that 'human oversight is necessary during post-processing' could be expanded with concrete examples of the types of errors or nuances that require intervention.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review, as well as for recognizing the potential significance of ATR4CH and the value of our empirical results across multiple LLMs. We address the major comment below.
read point-by-point responses
-
Referee: [Case Study / Evaluation] Case Study / Evaluation section: All reported metrics (0.65-0.75 F1 for hypothesis extraction, 0.62 G-EVAL for discourse representation) derive exclusively from Wikipedia articles on disputed items. These are secondary, consensus-oriented summaries with explicit structure and lower ambiguity than primary CH sources such as excavation reports or scholarly monographs; this scope limitation directly weakens the replicability claim that ATR4CH supplies an adaptable framework across CH domains.
Authors: We agree that the evaluation is confined to Wikipedia articles on disputed items, which are secondary sources with relatively explicit structure. The manuscript already states this limitation explicitly in the Research Limitations section: 'The produced KG is limited to Wikipedia articles.' Wikipedia articles were chosen for the case study because they contain accessible, well-documented examples of scholarly debates on authenticity assessments, enabling direct testing of the pipeline's ability to extract hypotheses, evidence, and discourse relations. The ATR4CH methodology itself consists of five general steps (foundational analysis, annotation schema development, pipeline architecture, integration refinement, and comprehensive evaluation) that are intended to be repeatable and adaptable to other CH texts and ontologies. The replicability claim therefore refers primarily to the systematic process rather than to the specific numerical results generalizing unchanged to primary sources. Nevertheless, the referee's point is well taken: stronger evidence of adaptability would require evaluation on primary documents such as excavation reports. We will revise the manuscript to (a) more explicitly frame the current case study as a proof-of-concept demonstration, (b) add a dedicated subsection discussing concrete adaptations needed for less-structured primary sources, and (c) moderate the language around cross-domain adaptability to better reflect the present scope. revision: partial
Circularity Check
No significant circularity; methodology is empirically grounded
full rationale
The paper presents ATR4CH as a five-step empirical methodology for LLM-guided extraction of entities, hypotheses, evidence, and discourse into KGs from cultural heritage texts, validated directly via reported F1 scores (0.7-0.8 entity, 0.65-0.75 hypothesis, 0.95-0.97 evidence) and G-EVAL discourse scores on a Wikipedia case study. No equations, parameter fits, or derivations are shown that reduce by construction to the inputs; the central replicability claim rests on these independent performance metrics rather than self-definition or self-citation chains. The methodology description and evaluation results are self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Ontologies can effectively guide LLM-based extraction of complex elements such as hypotheses, evidence, and discourse relations from cultural heritage texts.
invented entities (1)
-
ATR4CH methodology
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Reasoning4Sciences: Bridging Reasoning Language Models to All Scientific Branches
Survey of RLM adoption in 28 disciplines reveals maturity disparities via a new assessment framework, with focus on development, evaluation, and public resources.
Reference graph
Works this paper leans on
-
[1]
doi: 10.1007/978-3-030-71305-8 12
Springer. doi: 10.1007/978-3-030-71305-8 12. R. H¨ artel. Il falso documento del conte giovanni di moggio (875). In G. Pugnetti and B. Lucci, editors,Mue¸ c. Societˆ at Filologjiche Furlane/Societ` a Filologica Friulana, XCIV Congr` es, pages 247–252, Udin/Udine, 2017. Olaf Hartig. Foundations of rdf∗and sparql∗:(an alternative approach to statement-level...
-
[2]
doi: 10.1109/ACCESS.2022.3201542
ISSN 2169-3536. doi: 10.1109/ACCESS.2022.3201542. Yassir Lairgi, Ludovic Moncla, R´ emy Cazabet, Khalid Benabdeslem, and Pierre Cl´ eau. iText2KG: Incremental Knowledge Graphs Construction Using Large Language Models, 2024. URLhttp: //arxiv.org/abs/2409.03284. T. Lebo et al. Prov-o: The prov ontology. W3c recommendation, World Wide Web Consortium,
-
[3]
URLhttp://www.w3.org/TR/2013/REC-prov-o-20130430/. Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K¨ uttler, Mike Lewis, Wen-tau Yih, Tim Rockt¨ aschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive nlp tasks. InProceedings of the 34th International Confer...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.