Humanoid Whole-Body Badminton via Multi-Stage Reinforcement Learning
Pith reviewed 2026-05-17 22:39 UTC · model grok-4.3
The pith
A multi-stage reinforcement learning pipeline produces a unified whole-body controller for humanoid badminton without motion priors or expert demonstrations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
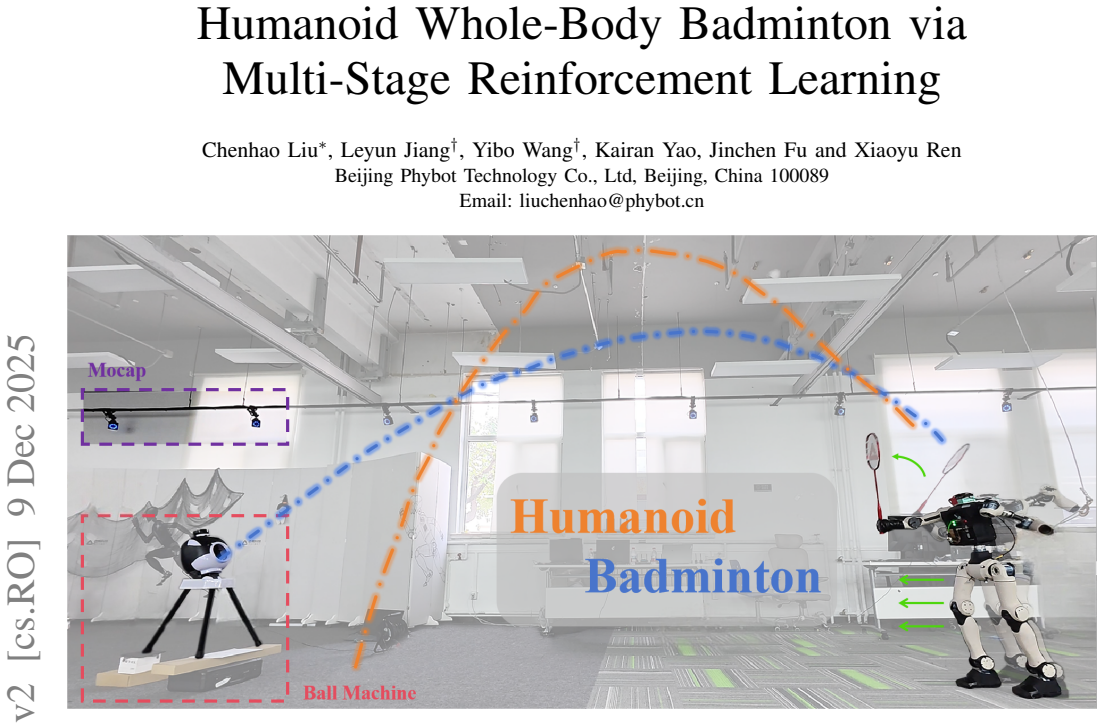
The authors develop a reinforcement-learning training pipeline that yields a unified whole-body controller for humanoid badminton, coordinating footwork and striking without motion priors or expert demonstrations. Training follows a three-stage curriculum (footwork acquisition, precision-guided swing generation, and task-focused refinement) so legs and arms jointly serve the hitting objective. For deployment, an Extended Kalman Filter estimates and predicts shuttlecock trajectories, while a prediction-free variant removes the EKF and explicit prediction. In simulation two robots sustain a rally of 21 consecutive hits; in real-world tests the robot reaches outgoing shuttle speeds up to 19.1 m
What carries the argument
the three-stage curriculum that progressively builds footwork, then precision swings, then task-focused refinement so locomotion and manipulation jointly optimize the hitting objective
If this is right
- Legs and arms can be trained to serve a shared dynamic objective rather than being optimized in isolation.
- Both prediction-using and prediction-free policies achieve comparable hitting performance on hardware.
- The same pipeline supports both machine-fed shuttles and human-robot rallies with mean return distances around 4 m.
- Whole-body coordination learned this way extends the range of feasible fast-moving object interactions for humanoids.
Where Pith is reading between the lines
- Similar curricula could be applied to other dynamic sports requiring simultaneous locomotion and striking, such as tennis or volleyball.
- The success of the prediction-free variant suggests that many dynamic tasks may not require explicit state estimation once the policy is sufficiently trained.
- Testing the same controller against faster or irregularly spinning shuttles would reveal the limits of the learned robustness.
Load-bearing premise
The three-stage curriculum enables the legs and arms to jointly optimize the hitting objective and the learned policy transfers from simulation to real hardware without additional motion priors or detailed domain randomization.
What would settle it
A real-world test in which the robot repeatedly fails to coordinate foot placement with arm swing timing, producing rallies shorter than a few exchanges or outgoing speeds below 10 m/s, would show the curriculum does not achieve the claimed joint optimization and transfer.
Figures











read the original abstract
Humanoid robots have demonstrated strong capabilities for interacting with static scenes across locomotion and manipulation, yet dynamic real-world interactions remain challenging. As a step toward fast-moving object interactions, we present a reinforcement-learning training pipeline that yields a unified whole-body controller for humanoid badminton, coordinating footwork and striking without motion priors or expert demonstrations. Training follows a three-stage curriculum (footwork acquisition, precision-guided swing generation, and task-focused refinement) so legs and arms jointly serve the hitting objective. For deployment, we use an Extended Kalman Filter (EKF) to estimate and predict shuttlecock trajectories for target striking, and also develop a prediction-free variant that removes the EKF and explicit prediction. We validate the framework with five sets of experiments in simulation and on hardware. In simulation, two robots sustain a rally of 21 consecutive hits. In real-world tests with both machine-fed shuttles and human-robot rallies, the robot achieves outgoing shuttle speeds up to 19.1~m/s with a mean return landing distance of 4~m. Moreover, the prediction-free variant attains comparable performance to the EKF-based target-known policy. Overall, our approach enables dynamic yet precise goal striking in humanoid badminton and suggests a path toward more dynamics-critical whole-body interaction tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a reinforcement-learning training pipeline that yields a unified whole-body controller for humanoid badminton, coordinating footwork and striking without motion priors or expert demonstrations. Training follows a three-stage curriculum (footwork acquisition, precision-guided swing generation, and task-focused refinement) so legs and arms jointly serve the hitting objective. For deployment, an Extended Kalman Filter (EKF) estimates and predicts shuttlecock trajectories, with a prediction-free variant also developed. Validation includes simulation experiments with 21-hit rallies and real-world tests achieving outgoing shuttle speeds up to 19.1 m/s with a mean return landing distance of 4 m.
Significance. If the central claims hold, this work advances dynamic whole-body control for humanoids in fast-moving object interactions. The empirical results in simulation and hardware, including comparable performance of the prediction-free variant, provide supporting evidence for sim-to-real transfer in dynamic tasks and suggest broader applicability to other dynamics-critical interactions. The lack of reliance on motion priors is a notable strength.
major comments (2)
- [§3 (Curriculum Design)] §3 (Curriculum Design): The central claim that the three-stage curriculum produces a single unified policy in which legs and arms co-optimize for hitting is not supported by ablations. No comparison is reported against a single-stage baseline using the same total compute budget and reward shaping, so it remains unclear whether the 21-hit rallies and hardware metrics arise from joint optimization or from sequential specialization of independent skills.
- [Reward Formulation (Methods)] Reward Formulation (Methods): Stage-specific reward weights are referenced but the explicit reward functions, their mathematical forms, and how they enforce joint leg-arm optimization across stages are not detailed. This omission directly affects assessment of whether the final policy discovers coordinated whole-body strategies rather than composing separately trained behaviors.
minor comments (2)
- [Abstract] The abstract would benefit from reporting the number of independent training runs and variance for the 21-hit rally result to strengthen the robustness claim.
- [Figures] Figure captions and legends for hardware experiments could more clearly distinguish results from the EKF-based and prediction-free policies.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address the two major comments point by point below and outline the revisions we will make to strengthen the presentation of the curriculum and reward design.
read point-by-point responses
-
Referee: [§3 (Curriculum Design)] §3 (Curriculum Design): The central claim that the three-stage curriculum produces a single unified policy in which legs and arms co-optimize for hitting is not supported by ablations. No comparison is reported against a single-stage baseline using the same total compute budget and reward shaping, so it remains unclear whether the 21-hit rallies and hardware metrics arise from joint optimization or from sequential specialization of independent skills.
Authors: We acknowledge that the manuscript does not include a direct ablation against a single-stage baseline trained with an identical total compute budget and reward shaping. The three-stage curriculum was designed to progressively build the necessary skills for whole-body coordination in a high-dimensional task where direct end-to-end training often fails to converge to effective policies. While the current results demonstrate successful joint leg-arm behavior in both simulation rallies and hardware, we agree that a matched-compute single-stage comparison would provide clearer evidence. In the revised manuscript we will add this baseline experiment, using the same total training steps and reward components, to quantify the contribution of the staged approach. revision: yes
-
Referee: [Reward Formulation (Methods)] Reward Formulation (Methods): Stage-specific reward weights are referenced but the explicit reward functions, their mathematical forms, and how they enforce joint leg-arm optimization across stages are not detailed. This omission directly affects assessment of whether the final policy discovers coordinated whole-body strategies rather than composing separately trained behaviors.
Authors: We appreciate this observation. The manuscript describes the high-level structure and purpose of the stage-specific rewards but omits the full mathematical definitions. In the revised version we will provide the explicit reward equations for each stage, including all terms (e.g., foot placement, swing timing, shuttle velocity, and posture stability) and their respective weights. These formulations are constructed so that the hitting objective is shared across the body, encouraging the policy to discover coordinated strategies rather than independent sub-skills. The added detail will allow readers to evaluate the joint-optimization mechanism directly. revision: yes
Circularity Check
Empirical RL training pipeline exhibits no circular derivation
full rationale
The paper describes a multi-stage reinforcement learning pipeline for training a humanoid badminton controller, with results obtained via simulation training (21-hit rallies) and real-world hardware validation (19.1 m/s strikes). No mathematical derivation chain, first-principles equations, or uniqueness theorems are presented that reduce to the inputs by construction. Claims rest on empirical outcomes from curriculum-based policy optimization and EKF-based or prediction-free deployment, without fitted parameters renamed as predictions or self-citations serving as load-bearing justification for the central results. The approach is self-contained against external benchmarks of training success and transfer.
Axiom & Free-Parameter Ledger
free parameters (1)
- stage-specific reward weights
axioms (1)
- domain assumption The simulated environment sufficiently matches real-world dynamics for policy transfer
Forward citations
Cited by 3 Pith papers
-
Rhythm: Learning Interactive Whole-Body Control for Dual Humanoids
Rhythm transfers interactive whole-body behaviors from simulation to real dual Unitree G1 humanoids via interaction-aware retargeting and graph-reward RL.
-
SigLoMa: Learning Open-World Quadrupedal Loco-Manipulation from Ego-Centric Vision
SigLoMa enables dynamic loco-manipulation on quadrupeds from ego-centric 5 Hz vision alone by using Sigma Points for scalable exteroception, an ego-centric Kalman Filter for high-rate state estimation, and an active s...
-
HAIC: Humanoid Agile Object Interaction Control via Dynamics-Aware World Model
HAIC enables robust humanoid interactions with underactuated objects by predicting their dynamics from proprioceptive history and using a world model for adaptive control.
Reference graph
Works this paper leans on
-
[1]
Real-world hu- manoid locomotion with reinforcement learning.Science Robotics, 9(89):eadi9579, 2024
Ilija Radosavovic, Tete Xiao, Bike Zhang, Trevor Darrell, Jitendra Malik, and Koushil Sreenath. Real-world hu- manoid locomotion with reinforcement learning.Science Robotics, 9(89):eadi9579, 2024
work page 2024
-
[2]
BeyondMimic: From Motion Tracking to Versatile Humanoid Control via Guided Diffusion
Takara E Truong, Qiayuan Liao, Xiaoyu Huang, Guy Tevet, C Karen Liu, and Koushil Sreenath. Be- yondmimic: From motion tracking to versatile hu- manoid control via guided diffusion.arXiv preprint arXiv:2508.08241, 2(3), 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Yoon, Ryan Hoque, Lars Paulsen, Ge Yang, Jian Zhang, Sha Yi, Guanya Shi, and Xiaolong Wang
Ri-Zhao Qiu, Shiqi Yang, Xuxin Cheng, Chaitanya Chawla, Jialong Li, Tairan He, Ge Yan, David J Yoon, Ryan Hoque, Lars Paulsen, et al. Humanoid policy˜ human policy.arXiv preprint arXiv:2503.13441, 2025
-
[4]
Learning human- to-humanoid real-time whole-body teleoperation
Tairan He, Zhengyi Luo, Wenli Xiao, Chong Zhang, Kris Kitani, Changliu Liu, and Guanya Shi. Learning human- to-humanoid real-time whole-body teleoperation. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 8944–8951. IEEE, 2024
work page 2024
- [5]
-
[6]
Humanoid parkour learning.arXiv preprint arXiv:2406.10759, 2024
Ziwen Zhuang, Shenzhe Yao, and Hang Zhao. Humanoid parkour learning.arXiv preprint arXiv:2406.10759, 2024
-
[7]
Hover: Versatile neural whole- body controller for humanoid robots
Tairan He, Wenli Xiao, Toru Lin, Zhengyi Luo, Zhenjia Xu, Zhenyu Jiang, Jan Kautz, Changliu Liu, Guanya Shi, Xiaolong Wang, et al. Hover: Versatile neural whole- body controller for humanoid robots. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 9989–9996. IEEE, 2025
work page 2025
-
[8]
Achieving human level competitive robot table tennis
David B DAmbrosio, Saminda Abeyruwan, Laura Graesser, Atil Iscen, Heni Ben Amor, Alex Bewley, Barney J Reed, Krista Reymann, Leila Takayama, Yuval Tassa, et al. Achieving human level competitive robot table tennis. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 74–82. IEEE, 2025
work page 2025
-
[9]
Robotic table tennis: A case study into a high speed learning system
David B D’Ambrosio, Navdeep Jaitly, Vikas Sindhwani, Ken Oslund, Peng Xu, Nevena Lazic, Anish Shankar, Tianli Ding, Jonathan Abelian, Erwin Coumans, et al. Robotic table tennis: A case study into a high speed learning system. InRobotics: Science and Systems, 2023
work page 2023
-
[10]
Zhi Su, Bike Zhang, Nima Rahmanian, Yuman Gao, Qiayuan Liao, Caitlin Regan, Koushil Sreenath, and S Shankar Sastry. Hitter: A humanoid table tennis robot via hierarchical planning and learning.arXiv preprint arXiv:2508.21043, 2025
-
[11]
Muqun Hu, Wenxi Chen, Wenjing Li, Falak Mandali, Zijian He, Renhong Zhang, Praveen Krisna, Katherine Christian, Leo Benaharon, Dizhi Ma, et al. Towards versatile humanoid table tennis: Unified reinforcement learning with prediction augmentation.arXiv preprint arXiv:2509.21690, 2025
-
[12]
Yuntao Ma, Andrei Cramariuc, Farbod Farshidian, and Marco Hutter. Learning coordinated badminton skills for legged manipulators.Science Robotics, 10(102):eadu3922, 2025
work page 2025
-
[13]
Yuntao Ma, Farbod Farshidian, Takahiro Miki, Joonho Lee, and Marco Hutter. Combining learning-based loco- motion policy with model-based manipulation for legged mobile manipulators.IEEE Robotics and Automation Letters, 7(2):2377–2384, 2022
work page 2022
-
[14]
Catch it! learning to catch in flight with mobile dexterous hands
Yuanhang Zhang, Tianhai Liang, Zhenyang Chen, Yanjie Ze, and Huazhe Xu. Catch it! learning to catch in flight with mobile dexterous hands. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 14385–14391, 2025
work page 2025
-
[15]
Hold my beer: Learning gentle humanoid locomotion and end-effector stabilization control, 2025
Yitang Li, Yuanhang Zhang, Wenli Xiao, Chaoyi Pan, Haoyang Weng, Guanqi He, Tairan He, and Guanya Shi. Learning gentle humanoid locomotion and end-effector stabilization control.arXiv preprint arXiv:2505.24198, 2025
-
[16]
Haochen Wang, Zhiwei Shi, Chengxi Zhu, Yafei Qiao, Cheng Zhang, Fan Yang, Pengjie Ren, Lan Lu, and Dong Xuan. Integrating learning-based manipulation and physics-based locomotion for whole-body badminton robot control.arXiv preprint arXiv:2504.17771, 2025
-
[17]
Deep whole-body control: Learning a unified policy for ma- nipulation and locomotion
Zipeng Fu, Xuxin Cheng, and Deepak Pathak. Deep whole-body control: Learning a unified policy for ma- nipulation and locomotion. In Karen Liu, Dana Kulic, and Jeff Ichnowski, editors,Proceedings of The 6th Con- ference on Robot Learning, volume 205 ofProceedings of Machine Learning Research, pages 138–149. PMLR, 14–18 Dec 2023
work page 2023
-
[18]
Multi-critic learning for whole-body end-effector twist tracking
Aravind Elanjimattathil Vijayan, Andrei Cramariuc, Mat- tia Risiglione, Christian Gehring, and Marco Hutter. Multi-critic learning for whole-body end-effector twist tracking. In Joseph Lim, Shuran Song, and Hae-Won Park, editors,Proceedings of The 9th Conference on Robot Learning, volume 305 ofProceedings of Machine Learning Research, pages 1470–1485. PML...
work page 2025
-
[19]
Arm-constrained curriculum learning for loco- manipulation of a wheel-legged robot
Zifan Wang, Yufei Jia, Lu Shi, Haoyu Wang, Haizhou Zhao, Xueyang Li, Jinni Zhou, Jun Ma, and Guyue Zhou. Arm-constrained curriculum learning for loco- manipulation of a wheel-legged robot. In2024 IEEE/RSJ International Conference on Intelligent Robots and Sys- tems (IROS), pages 10770–10776. IEEE, 2024
work page 2024
-
[20]
Dianyong Hou, Chengrui Zhu, Zhen Zhang, Zhibin Li, Chuang Guo, and Yong Liu. Efficient learning of a uni- fied policy for whole-body manipulation and locomotion skills.arXiv preprint arXiv:2507.04229, 2025
-
[21]
Umi on legs: Making manipulation policies mobile with manipulation-centric whole-body controllers,
Huy Ha, Yihuai Gao, Zipeng Fu, Jie Tan, and Shuran Song. Umi on legs: Making manipulation policies mobile with manipulation-centric whole-body controllers.arXiv preprint arXiv:2407.10353, 2024
-
[22]
Yuntao Ma, Yang Liu, Kaixian Qu, and Marco Hut- ter. Learning accurate whole-body throwing with high- frequency residual policy and pullback tube acceleration. arXiv preprint arXiv:2506.16986, 2025
-
[23]
Varsm: Versatile autonomous racquet sports machine
Fan Yang, Zhiwei Shi, Sixian Ye, Jiazhong Qian, Wenjie Wang, and Dong Xuan. Varsm: Versatile autonomous racquet sports machine. In2022 ACM/IEEE 13th Interna- tional Conference on Cyber-Physical Systems (ICCPS), pages 203–214, 2022
work page 2022
-
[24]
Zulfiqar Zaidi, Daniel Martin, Nathaniel Belles, Viach- eslav Zakharov, Arjun Krishna, Kin Man Lee, Peter Wagstaff, Sumedh Naik, Matthew Sklar, Sugju Choi, et al. Athletic mobile manipulator system for robotic wheelchair tennis.IEEE Robotics and Automation Let- ters, 8(4):2245–2252, 2023
work page 2023
-
[25]
Zhongyu Li, Xue Bin Peng, Pieter Abbeel, Sergey Levine, Glen Berseth, and Koushil Sreenath. Rein- forcement learning for versatile, dynamic, and robust bipedal locomotion control.The International Journal of Robotics Research, 44(5):840–888, 2025
work page 2025
-
[26]
Asymmetric actor critic for image-based robot learning
Lerrel Pinto, Marcin Andrychowicz, Peter Welinder, Wo- jciech Zaremba, and Pieter Abbeel. Asymmetric actor critic for image-based robot learning. InProceedings of Robotics: Science and Systems, Pittsburgh, Pennsylvania, June 2018
work page 2018
-
[27]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[28]
Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning
Viktor Makoviychuk, Lukasz Wawrzyniak, Yunrong Guo, Michelle Lu, Kier Storey, Miles Macklin, David Hoeller, Nikita Rudin, Arthur Allshire, Ankur Handa, et al. Isaac gym: High performance gpu-based physics simulation for robot learning.arXiv preprint arXiv:2108.10470, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[29]
Learning to walk in minutes using massively parallel deep reinforcement learning
Nikita Rudin, David Hoeller, Philipp Reist, and Marco Hutter. Learning to walk in minutes using massively parallel deep reinforcement learning. InConference on robot learning, pages 91–100. PMLR, 2022
work page 2022
-
[30]
The physics of badminton.New Journal of Physics, 17(6):063001, 2015
Caroline Cohen, Baptiste Darbois Texier, David Qu ´er´e, and Christophe Clanet. The physics of badminton.New Journal of Physics, 17(6):063001, 2015
work page 2015
-
[31]
Learning agile and dynamic motor skills for legged robots.Science Robotics, 4(26):eaau5872, 2019
Jemin Hwangbo, Joonho Lee, Alexey Dosovitskiy, Dario Bellicoso, Vassilios Tsounis, Vladlen Koltun, and Marco Hutter. Learning agile and dynamic motor skills for legged robots.Science Robotics, 4(26):eaau5872, 2019
work page 2019
-
[32]
Filip Bjelonic, Fabian Tischhauser, and Marco Hut- ter. Towards bridging the gap: Systematic sim-to- real transfer for diverse legged robots.arXiv preprint arXiv:2509.06342, 2025. APPENDIX A. System Parameters Per-joint PD gains(Table I) list the proportional and derivative gains used by the 500 Hz joint-space PD controller for each controllable DoF in bo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.