Learning Under Low Illumination: A Dataset and Algorithm for Traffic Sign Recognition
Pith reviewed 2026-05-17 20:37 UTC · model grok-4.3
The pith
A new Indian nighttime traffic sign dataset and LENS-Net model tackle recognition under low illumination.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce INTSD, a large-scale nighttime traffic sign dataset collected across diverse regions of India containing street-level images spanning 41 traffic signboard classes, multiple distractor categories, and varied lighting and weather conditions. We present LENS-Net, which integrates adaptive illumination-aware detection with multimodal semantic reasoning for robust nighttime sign classification, and show through evaluations that current models face clear challenges on this data.
What carries the argument
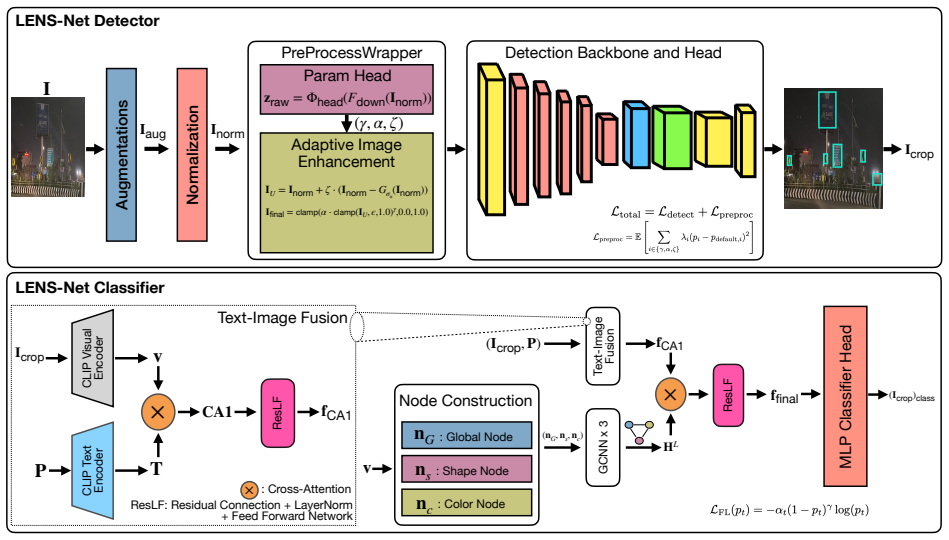
LENS-Net, which integrates adaptive illumination-aware detection with multimodal semantic reasoning to classify signs despite low-light degradations.
If this is right
- Standard daytime detectors and classifiers will underperform on INTSD, confirming the need for illumination-specific methods.
- LENS-Net provides a concrete baseline that future nighttime recognition work can compare against.
- The dataset enables joint training for detection and fine-grained classification under realistic low-light conditions.
- Autonomous driving and intelligent transportation systems can now be tested against documented nighttime sign challenges.
Where Pith is reading between the lines
- The same illumination-aware and multimodal techniques might transfer to other low-light vision tasks such as pedestrian or vehicle detection.
- Extending the collection protocol to additional countries or sensor types would test whether the observed performance gaps are universal.
- Integration of the dataset with existing daytime benchmarks could produce training regimes that maintain accuracy across day-to-night transitions.
Load-bearing premise
The collected images and labeling process accurately capture the full range of real-world low-light degradations and distractors that future systems will encounter outside the Indian collection sites.
What would settle it
A detection or classification model that reaches high accuracy on INTSD but shows large drops in performance on nighttime traffic signs collected from a different country or under lighting conditions absent from the dataset would show the data and model do not fully generalize.
Figures












read the original abstract
Traffic signboards are vital for road safety and intelligent transportation systems, enabling navigation and autonomous driving. Yet, recognizing traffic signs at night remains underexplored due to the scarcity of realistic public datasets capturing low-light degradations and distractor classes. Existing benchmarks are predominantly daytime and do not reflect challenges such as headlight glare, motion blur, sensor noise, and vandalized or ambiguous signage. To address these gaps, we introduce INTSD, a large-scale nighttime traffic sign dataset collected across diverse regions of India. INTSD contains street-level images spanning 41 traffic signboard classes, multiple distractor categories, and varied lighting and weather conditions. The dataset is designed to support both detection and fine-grained classification under realistic nighttime scenarios. To benchmark INTSD for nighttime sign recognition, we conduct extensive evaluations using state-of-the-art detection and classification models under standardized protocols. Additionally, we present LENS-Net, a strong baseline that integrates adaptive illumination-aware detection with multimodal semantic reasoning for robust nighttime sign classification. Experiments and ablations demonstrate the challenges posed by INTSD and establish competitive baselines for future research. The dataset and code for LENS-Net is publicly available for research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces INTSD, a large-scale nighttime traffic sign dataset collected across diverse regions of India containing street-level images spanning 41 traffic sign classes, multiple distractor categories, and varied lighting/weather conditions. It also presents LENS-Net as a baseline integrating adaptive illumination-aware detection with multimodal semantic reasoning, reports extensive evaluations of SOTA detection and classification models on the dataset under standardized protocols, and releases the dataset and code publicly.
Significance. If the dataset collection protocol and labeling accurately capture realistic low-light degradations and if LENS-Net evaluations are robust, the work would provide a valuable new benchmark and baseline for nighttime traffic sign recognition, addressing a documented scarcity in public datasets for this safety-critical application in intelligent transportation systems.
major comments (2)
- [§3 (Dataset Collection)] §3 (Dataset Collection): The abstract positions INTSD as addressing the global scarcity of realistic nighttime benchmarks capturing headlight glare, motion blur, sensor noise, and ambiguous signage. However, the collection is restricted to diverse regions of India; no discussion or validation addresses potential systematic differences in traffic sign standards, road infrastructure, headlight spectra, or extreme weather outside India. This directly affects whether INTSD can serve as a generalizable benchmark supporting the central claims.
- [§5 (Experiments and Ablations)] §5 (Experiments and Ablations): The abstract reports extensive evaluations and ablations demonstrating challenges and establishing competitive baselines for LENS-Net, yet no error bars, statistical significance tests, or details on post-hoc model selection choices are referenced. This makes it difficult to assess the strength of claims that LENS-Net provides a strong baseline relative to SOTA models.
minor comments (1)
- [Abstract] The abstract and introduction could include the total number of images and annotation statistics for INTSD to better convey dataset scale upfront.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive comments on our manuscript. We address each of the major comments point by point below, indicating the revisions we intend to make to improve the paper.
read point-by-point responses
-
Referee: [§3 (Dataset Collection)] The abstract positions INTSD as addressing the global scarcity of realistic nighttime benchmarks capturing headlight glare, motion blur, sensor noise, and ambiguous signage. However, the collection is restricted to diverse regions of India; no discussion or validation addresses potential systematic differences in traffic sign standards, road infrastructure, headlight spectra, or extreme weather outside India. This directly affects whether INTSD can serve as a generalizable benchmark supporting the central claims.
Authors: We appreciate the referee pointing out the need for clearer discussion on the geographic scope of INTSD. The dataset was specifically collected in India to capture realistic nighttime conditions in a region with diverse road infrastructure and sign variations that are underrepresented in existing benchmarks. However, we agree that without explicit discussion, it may be unclear how well the results generalize. In the revised manuscript, we will add a dedicated paragraph in Section 3 discussing potential systematic differences, such as variations in traffic sign designs across countries, differences in headlight technologies, and weather extremes not present in our collection sites. We will also note that while INTSD provides a valuable benchmark for low-illumination traffic sign recognition, cross-dataset validation with other regions would be beneficial for broader claims. This addition will help readers understand the intended scope and limitations. revision: yes
-
Referee: [§5 (Experiments and Ablations)] The abstract reports extensive evaluations and ablations demonstrating challenges and establishing competitive baselines for LENS-Net, yet no error bars, statistical significance tests, or details on post-hoc model selection choices are referenced. This makes it difficult to assess the strength of claims that LENS-Net provides a strong baseline relative to SOTA models.
Authors: We thank the referee for this observation on the experimental reporting. Our evaluations were conducted over multiple random seeds to ensure reliability, but we acknowledge that the manuscript does not explicitly include error bars or statistical tests in the presented results. To address this, we will revise Section 5 to include standard deviation error bars in all performance tables and figures. Furthermore, we will add statistical significance testing (such as McNemar's test for classification or paired t-tests for detection metrics) between LENS-Net and the compared SOTA models. We will also elaborate on the hyperparameter tuning and model selection procedure to provide full transparency. These revisions will strengthen the evidence for LENS-Net as a competitive baseline. revision: yes
Circularity Check
No circularity: contributions are new data collection and architecture proposal
full rationale
The paper introduces a new nighttime traffic sign dataset (INTSD) collected in India and proposes LENS-Net as a baseline model integrating illumination-aware detection and multimodal reasoning. No load-bearing steps reduce by construction to fitted parameters, self-citations, or prior ansatzes. Evaluations use standard SOTA models on the new data under explicit protocols; the dataset itself is the primary input rather than a derived output. The central claims rest on empirical collection and architectural design, which are self-contained against external benchmarks and do not invoke uniqueness theorems or self-referential definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Deep neural networks trained on labeled images can learn features that generalize to unseen low-light conditions when sufficient diverse data is provided.
invented entities (1)
-
LENS-Net
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
LENS-Net detector wraps YOLOv8 with PreprocessWrapper predicting (γ, α, ζ) via tanh-scaled head and differentiable gamma/brightness/unsharp transforms plus L_preproc regularization.
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Classifier builds 3-node graph (global, shape, color) processed by 3-layer GCNN with symmetric normalized adjacency and cross-attention fusion.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
An erudite fine-grained visual classification model
Dongliang Chang, Yujun Tong, Ruoyi Du, Timothy Hospedales, Yi-Zhe Song, and Zhanyu Ma. An erudite fine-grained visual classification model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7268–7277, 2023. 2
work page 2023
-
[2]
Chen Chen, Qifeng Chen, Jia Xu, and Vladlen Koltun. Learning to see in the dark. InProceedings of the IEEE con- ference on computer vision and pattern recognition, pages 3291–3300, 2018. 1
work page 2018
-
[3]
Junzhou Chen, Heqiang Huang, Ronghui Zhang, Nengchao Lyu, Yanyong Guo, Hong-Ning Dai, and Hong Yan. Yolo-ts: Real-time traffic sign detection with enhanced accuracy us- 8 ing optimized receptive fields and anchor-free fusion.IEEE Transactions on Intelligent Transportation Systems, 2025. 7
work page 2025
-
[4]
Ziteng Cui, Kunchang Li, Lin Gu, Shenghan Su, Peng Gao, Zhengkai Jiang, Yu Qiao, and Tatsuya Harada. You only need 90k parameters to adapt light: a light weight trans- former for image enhancement and exposure correction. arXiv preprint arXiv:2205.14871, 2022. 2
-
[5]
Saba Dadsetan, David Pichler, David Wilson, Naira Hov- akimyan, and Jennifer Hobbs. Superpixels and graph con- volutional neural networks for efficient detection of nutri- ent deficiency stress from aerial imagery. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2950–2959, 2021. 2
work page 2021
-
[6]
Jifeng Dai, Yi Li, Kaiming He, and Jian Sun. R-fcn: Object detection via region-based fully convolutional networks.Ad- vances in neural information processing systems, 29, 2016. 2
work page 2016
-
[7]
Boosting object detection with zero-shot day-night domain adaptation
Zhipeng Du, Miaojing Shi, and Jiankang Deng. Boosting object detection with zero-shot day-night domain adaptation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12666–12676, 2024. 7
work page 2024
-
[8]
The via annota- tion software for images, audio and video
Abhishek Dutta and Andrew Zisserman. The via annota- tion software for images, audio and video. InProceedings of the 27th ACM international conference on multimedia, pages 2276–2279, 2019. 3
work page 2019
-
[9]
The mapillary traffic sign dataset for detection and classification on a global scale
Christian Ertler, Jerneja Mislej, Tobias Ollmann, Lorenzo Porzi, Gerhard Neuhold, and Yubin Kuang. The mapillary traffic sign dataset for detection and classification on a global scale. InEuropean conference on computer vision, pages 68–84. Springer, 2020. 1, 2, 3
work page 2020
-
[10]
Mark Everingham, SM Ali Eslami, Luc Van Gool, Christo- pher KI Williams, John Winn, and Andrew Zisserman. The pascal visual object classes challenge: A retrospective.Inter- national journal of computer vision, 111(1):98–136, 2015. 1
work page 2015
-
[11]
Robust physical-world attacks on deep learning visual classification
Kevin Eykholt, Ivan Evtimov, Earlence Fernandes, Bo Li, Amir Rahmati, Chaowei Xiao, Atul Prakash, Tadayoshi Kohno, and Dawn Song. Robust physical-world attacks on deep learning visual classification. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 1625–1634, 2018. 1
work page 2018
-
[12]
Traffic sign recognition using local vision transformer
Ali Farzipour, Omid Nejati Manzari, and Shahriar B Shok- ouhi. Traffic sign recognition using local vision transformer. In2023 13th International Conference on Computer and Knowledge Engineering (ICCKE), pages 191–196. IEEE,
-
[13]
Rich feature hierarchies for accurate object detection and semantic segmentation
Ross Girshick, Jeff Donahue, Trevor Darrell, and Jitendra Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. InProceedings of the IEEE con- ference on computer vision and pattern recognition, pages 580–587, 2014. 2
work page 2014
-
[14]
Zero-reference deep curve estimation for low-light image enhancement
Chunle Guo, Chongyi Li, Jichang Guo, Chen Change Loy, Junhui Hou, Sam Kwong, and Runmin Cong. Zero-reference deep curve estimation for low-light image enhancement. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 1780–1789, 2020. 2
work page 2020
-
[15]
Traffic Sign Classification Using Deep Inception Based Convolutional Networks
Mrinal Haloi. Traffic sign classification using deep in- ception based convolutional networks.arXiv preprint arXiv:1511.02992, 2015. 2
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[16]
Yan Han and Erdal Oruklu. Traffic sign recognition based on the nvidia jetson tx1 embedded system using convolutional neural networks. In2017 IEEE 60th International Midwest Symposium on Circuits and Systems (MWSCAS), pages 184–
-
[17]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 7
work page 2016
-
[18]
Cycada: Cycle-consistent adversarial domain adaptation
Judy Hoffman, Eric Tzeng, Taesung Park, Jun-Yan Zhu, Phillip Isola, Kate Saenko, Alexei Efros, and Trevor Darrell. Cycada: Cycle-consistent adversarial domain adaptation. In International conference on machine learning, pages 1989–
work page 1989
-
[19]
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural net- works.Advances in neural information processing systems, 25, 2012. 1
work page 2012
-
[20]
Alina Kuznetsova, Hassan Rom, Neil Alldrin, Jasper Ui- jlings, Ivan Krasin, Jordi Pont-Tuset, Shahab Kamali, Stefan Popov, Matteo Malloci, Alexander Kolesnikov, et al. The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale.Interna- tional journal of computer vision, 128(7):1956–1981, 2020. 1
work page 1956
-
[21]
Using fourier de- scriptors and spatial models for traffic sign recognition
Fredrik Larsson and Michael Felsberg. Using fourier de- scriptors and spatial models for traffic sign recognition. In Scandinavian conference on image analysis, pages 238–249. Springer, 2011. 2, 7
work page 2011
-
[22]
Perceptual generative adversar- ial networks for small object detection
Jianan Li, Xiaodan Liang, Yunchao Wei, Tingfa Xu, Jiashi Feng, and Shuicheng Yan. Perceptual generative adversar- ial networks for small object detection. InProceedings of the IEEE conference on computer vision and pattern recog- nition, pages 1222–1230, 2017. 1
work page 2017
-
[23]
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. InInterna- tional conference on machine learning, pages 12888–12900. PMLR, 2022. 7, 8
work page 2022
-
[24]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740–755. Springer, 2014. 1
work page 2014
-
[25]
Feature pyra- mid networks for object detection
Tsung-Yi Lin, Piotr Doll ´ar, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. Feature pyra- mid networks for object detection. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 2117–2125, 2017. 2
work page 2017
-
[26]
Focal loss for dense object detection
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Doll´ar. Focal loss for dense object detection. InPro- ceedings of the IEEE international conference on computer vision, pages 2980–2988, 2017. 2, 7
work page 2017
-
[27]
Ziyu Lin, Yunfan Wu, Yuhang Ma, Junzhou Chen, Ronghui Zhang, Jiaming Wu, Guodong Yin, and Liang Lin. Yolo-llts: 9 Real-time low-light traffic sign detection via prior-guided enhancement and multi-branch feature interaction.arXiv preprint arXiv:2503.13883, 2025. 1
-
[28]
Ssd: Single shot multibox detector
Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, and Alexander C Berg. Ssd: Single shot multibox detector. InEuropean con- ference on computer vision, pages 21–37. Springer, 2016. 1, 2
work page 2016
-
[29]
Image-adaptive yolo for object detec- tion in adverse weather conditions
Wenyu Liu, Gaofeng Ren, Runsheng Yu, Shi Guo, Jianke Zhu, and Lei Zhang. Image-adaptive yolo for object detec- tion in adverse weather conditions. InProceedings of the AAAI conference on artificial intelligence, pages 1792–1800,
-
[30]
Chengsheng Mao, Liang Yao, and Yuan Luo. Imagegcn: Multi-relational image graph convolutional networks for dis- ease identification with chest x-rays.IEEE transactions on medical imaging, 41(8):1990–2003, 2022. 2
work page 1990
-
[31]
Markus Mathias, Radu Timofte, Rodrigo Benenson, and Luc Van Gool. Traffic sign recognition—how far are we from the solution? InThe 2013 international joint conference on Neural networks (IJCNN), pages 1–8. IEEE, 2013. 2
work page 2013
-
[32]
Subject representation learning from eeg using graph convolutional variational autoencoders
Aditya Mishra, Ahnaf Mozib Samin, Ali Etemad, and Javad Hashemi. Subject representation learning from eeg using graph convolutional variational autoencoders. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE,
work page 2025
-
[33]
Andreas Mogelmose, Mohan Manubhai Trivedi, and Thomas B Moeslund. Vision-based traffic sign detection and analysis for intelligent driver assistance systems: Per- spectives and survey.IEEE transactions on intelligent trans- portation systems, 13(4):1484–1497, 2012. 2
work page 2012
-
[34]
The mapillary vistas dataset for semantic understanding of street scenes
Gerhard Neuhold, Tobias Ollmann, Samuel Rota Bulo, and Peter Kontschieder. The mapillary vistas dataset for semantic understanding of street scenes. InProceedings of the IEEE international conference on computer vision, pages 4990– 4999, 2017. 2
work page 2017
-
[35]
Day- to-night image synthesis for training nighttime neural isps
Abhijith Punnappurath, Abdullah Abuolaim, Abdelrahman Abdelhamed, Alex Levinshtein, and Michael S Brown. Day- to-night image synthesis for training nighttime neural isps. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10769–10778, 2022. 1
work page 2022
-
[36]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 2, 7, 8
work page 2021
-
[37]
Yolo9000: better, faster, stronger
Joseph Redmon and Ali Farhadi. Yolo9000: better, faster, stronger. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 7263–7271, 2017. 2
work page 2017
-
[38]
You only look once: Unified, real-time object de- tection
Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. You only look once: Unified, real-time object de- tection. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 779–788, 2016. 1, 7
work page 2016
-
[39]
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks.Advances in neural information process- ing systems, 28, 2015. 1, 2, 7
work page 2015
-
[40]
J Rodrigues and J Carbonera. Graph convolutional networks for image classification: Comparing approaches for building graphs from images. InProceedings of the 26th International Conference on Enter-prise Information Systems-Volume 1: ICEIS, pages 437–446, 2024. 2
work page 2024
-
[41]
Acdc: The adverse conditions dataset with correspondences for semantic driving scene understanding
Christos Sakaridis, Dengxin Dai, and Luc Van Gool. Acdc: The adverse conditions dataset with correspondences for semantic driving scene understanding. InProceedings of the IEEE/CVF international conference on computer vision, pages 10765–10775, 2021. 1
work page 2021
-
[42]
Russian traffic sign images dataset.Computer optics, 40(2):294–300, 2016
Vladislav Igorevich Shakhuro and Anton Sergeevich Konushin. Russian traffic sign images dataset.Computer optics, 40(2):294–300, 2016. 1, 2
work page 2016
-
[43]
The german traffic sign recognition bench- mark: a multi-class classification competition
Johannes Stallkamp, Marc Schlipsing, Jan Salmen, and Christian Igel. The german traffic sign recognition bench- mark: a multi-class classification competition. InThe 2011 international joint conference on neural networks, pages 1453–1460. IEEE, 2011. 2
work page 2011
-
[44]
Johannes Stallkamp, Marc Schlipsing, Jan Salmen, and Christian Igel. Man vs. computer: Benchmarking machine learning algorithms for traffic sign recognition.Neural net- works, 32:323–332, 2012. 2
work page 2012
-
[45]
Xiaoqiang Sun, Kuankuan Liu, Long Chen, Yingfeng Cai, and Hai Wang. Llth-yolov5: a real-time traffic sign detection algorithm for low-light scenes.Automotive Innovation, 7(1): 121–137, 2024. 1, 2
work page 2024
-
[46]
Traffic sign detec- tion and recognition based on convolutional neural network
Ying Sun, Pingshu Ge, and Dequan Liu. Traffic sign detec- tion and recognition based on convolutional neural network. In2019 Chinese automation congress (CAC), pages 2851–
-
[47]
Training data-efficient image transformers & distillation through at- tention
Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Herv ´e J´egou. Training data-efficient image transformers & distillation through at- tention. InInternational conference on machine learning, pages 10347–10357. PMLR, 2021. 7, 8
work page 2021
-
[48]
Low-light image enhancement framework for improved object detection in fisheye lens datasets
Dai Quoc Tran, Armstrong Aboah, Yuntae Jeon, Maged Shoman, Minsoo Park, and Seunghee Park. Low-light image enhancement framework for improved object detection in fisheye lens datasets. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR) Workshops, pages 7056–7065, 2024. 2
work page 2024
-
[49]
Cnn2graph: Build- ing graphs for image classification
Vivek Trivedy and Longin Jan Latecki. Cnn2graph: Build- ing graphs for image classification. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 1–11, 2023. 2
work page 2023
-
[50]
Rishabh Uikey, Haroon R Lone, and Akshay Agarwal. In- dian traffic sign detection and classification through a unified framework.IEEE Transactions on Intelligent Transportation Systems, 25(10):14866–14875, 2024. 3, 7, 8, 6
work page 2024
-
[51]
Learning to navigate for fine-grained clas- sification
Ze Yang, Tiange Luo, Dong Wang, Zhiqiang Hu, Jun Gao, and Liwei Wang. Learning to navigate for fine-grained clas- sification. InProceedings of the European conference on computer vision (ECCV), pages 420–435, 2018. 2
work page 2018
-
[52]
BD D100K: A diverse driving video database with scalable annotation tooling,
Fisher Yu, Wenqi Xian, Yingying Chen, Fangchen Liu, Mike Liao, Vashisht Madhavan, Trevor Darrell, et al. Bdd100k: A 10 diverse driving video database with scalable annotation tool- ing.arXiv preprint arXiv:1805.04687, 2(5):6, 2018. 2
-
[53]
Unpaired image-to-image translation using cycle- consistent adversarial networks
Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A Efros. Unpaired image-to-image translation using cycle- consistent adversarial networks. InProceedings of the IEEE international conference on computer vision, pages 2223– 2232, 2017. 1
work page 2017
-
[54]
Traffic-sign detection and classifica- tion in the wild
Zhe Zhu, Dun Liang, Songhai Zhang, Xiaolei Huang, Baoli Li, and Shimin Hu. Traffic-sign detection and classifica- tion in the wild. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2110–2118,
-
[55]
1, 2 11 Navigating in the Dark: A Multimodal Framework and Dataset for Nighttime Traffic Sign Recognition Supplementary Material
-
[56]
A summary of all figures is given in Table 4
Indian Nighttime Traffic Sign Dataset This section provides representative examples from our dataset, illustrating the various challenges, supplementary classes, weather conditions, and daytime scenarios detailed in Section 3. A summary of all figures is given in Table 4. Table 4. Summary of all the figures. Figure Description Figure 7 Sensor and weather ...
-
[57]
The top-row samples, captured using smartphones, generally exhibit higher visual quality compared to the bottom-row images captured with an action camera. Figure 12. Images with multiple signboards in one frame, creating the kind of visual clutter common on Indian roads. Both images have been taken from smartphone. Figure 13. Four distinct signboard desig...
-
[58]
All hyperparameters and training set- tings reported here correspond to those used in our study
Implementation Details This section provides the implementation details for both components of our pipeline: (i) LENS-Net detector, and (ii) LENS-Net classifier. All hyperparameters and training set- tings reported here correspond to those used in our study. We used a system with a 16 GB NVIDIA GeForce RTX 5080 to train the model. The LENS-Net detector an...
-
[59]
Method We provide the complete architecture of the LENS-Net de- tector in Algorithm 2. For a given image cropI crop from the LENS-Net detector, we pass it through the frozen CLIP Vision Transformer (ViT). We extract the output embed- ding from the CLIP image encoder (E img clip ), yielding an L2-normalized global feature vectorv∈R D. This vector serves as...
-
[60]
We also provide the class-wise performance for Rishabh et al
Additional Results Table 8 reports the per-class precision, recall, and support across all 41 traffic-sign categories for the LENS-Net clas- sifier, averaged over the five cross-validation folds. We also provide the class-wise performance for Rishabh et al
-
[61]
(the strongest baseline) for comparison. The results show that the LENS-Net classifier maintains strong perfor- mance even for classes with extremely limited samples. For rare classes, such asairport,blow horn,cross road, and steep ascent, which contain very few (relative to dominant classes) samples per fold, the model achieves non-trivial precision or r...
-
[62]
Frequently Asked Questions Q: Why do you use 5-fold cross-validation? The use of stratified 5-fold cross-validation is crucial for several reasons. First, it ensures that each image in the dataset is used for both training and testing, thereby reduc- ing bias in the evaluation process. Second, by averaging the performance metrics across all folds, we obta...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.