GPU-native Embedding of Complex Geometries in Adaptive Octree Grids Applied to the Lattice Boltzmann Method
Pith reviewed 2026-05-17 03:40 UTC · model grok-4.3
The pith
A GPU-native ray-casting algorithm embeds stationary triangle meshes into block-structured octree grids and builds cut-link tables for lattice Boltzmann boundary conditions entirely on the device.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
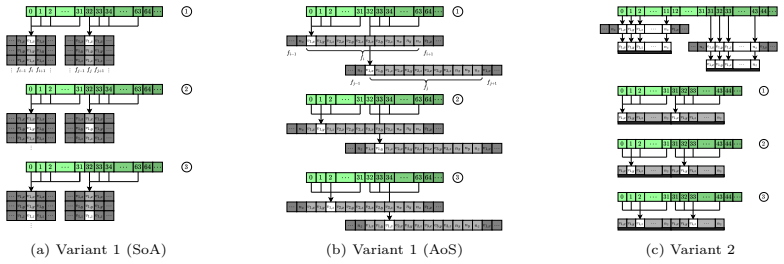
The central claim is that a GPU-native algorithm can incorporate stationary triangle-mesh geometries into block-structured forest-of-octrees grids by executing both solid voxelization and automated near-wall refinement entirely on the device, employing local ray casting accelerated by a hierarchy of spatial bins to eliminate index orderings and hash tables, and constructing a flattened lookup table of cut-link distances to support accurate interpolated bounce-back boundary conditions.
What carries the argument
Local ray-casting procedure with a hierarchy of spatial bins that classifies cut cells and computes cut-link distances for watertight meshes while enabling coalesced access on GPU-resident octree blocks.
If this is right
- Geometry embedding and interpolation impose only modest overhead on the overall solver runtime.
- Accurate force predictions are obtained for external flows past cylinders in 2D at Re=100 and spheres in 3D at Re=10,15,20.
- Stable near-wall resolution is maintained on adaptive Cartesian grids for the tested stationary geometries.
- The method is general and applies to other explicit solvers that require GPU-resident geometry embedding.
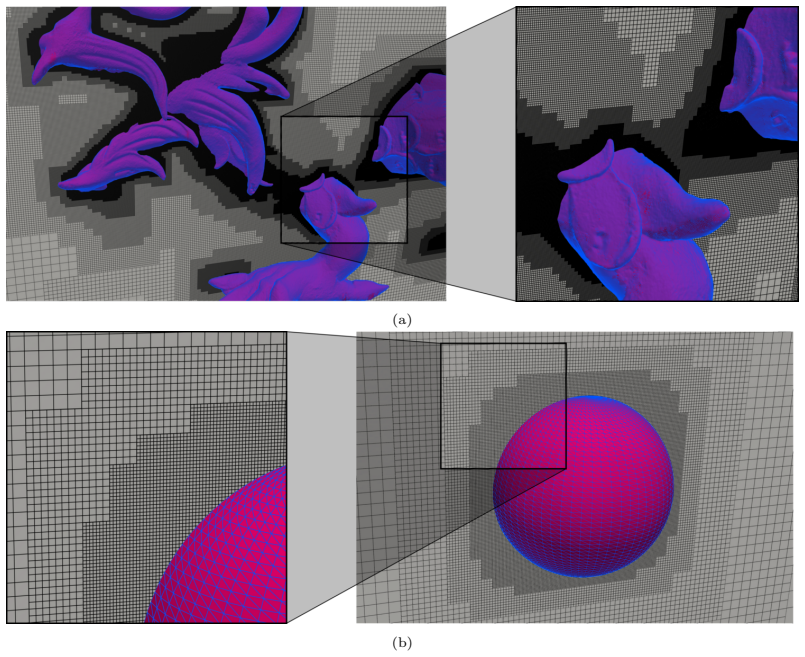
- Benchmark results confirm correctness for both low-triangle-count and high-triangle-count models from the Stanford 3D Scanning Repository.
Where Pith is reading between the lines
- Extending the ray-casting bins to handle time-varying meshes could support moving-boundary problems without repeated CPU-GPU transfers.
- The flattened cut-link table structure might integrate with other boundary-condition formulations beyond interpolated bounce-back.
- Performance on multi-GPU systems with meshes larger than 7 million triangles remains an open scaling question.
- Similar local classification techniques could reduce host-device synchronization in other adaptive-grid CFD codes.
Load-bearing premise
The local ray-casting procedure with a hierarchy of spatial bins correctly classifies all cut cells and produces accurate cut-link distances for arbitrary watertight meshes without requiring CPU intervention or post-processing.
What would settle it
Direct comparison of GPU-classified cut cells and distances against an independent CPU voxelization reference on the Stanford Bunny or XYZ RGB Dragon mesh would show whether any surface intersections are misclassified.
Figures





























read the original abstract
Adaptive mesh refinement (AMR) reduces computational costs in CFD by concentrating resolution where needed, but efficiently embedding complex, non-aligned geometries on GPUs remains challenging. We present a GPU-native algorithm for incorporating stationary triangle-mesh geometries into block-structured forest-of-octrees grids, performing both solid voxelization and automated near-wall refinement entirely on the device. The method employs local ray casting accelerated by a hierarchy of spatial bins, leveraging efficient grid-block traversal to eliminate the need for index orderings and hash tables commonly used in CPU pipelines, and enabling coalesced memory access without CPU-GPU synchronization. A flattened lookup table of cut-link distances between fluid and solid cells is constructed to support accurate interpolated bounce-back boundary conditions for the lattice Boltzmann method (LBM). We implement this approach as an extension of the AGAL framework for GPU-based AMR and benchmark the geometry module using the Stanford Bunny (112K triangles) and XYZ RGB Dragon (7.2M triangles) models from the Stanford 3D Scanning Repository. The extended solver is validated for external flows past a circular/square cylinder (2D, $Re = 100$), and a sphere (3D, $\text{Re}\in\{10, 15, 20\}$). Results demonstrate that geometry handling and interpolation impose modest overhead while delivering accurate force predictions and stable near-wall resolution on adaptive Cartesian grids. The approach is general and applicable to other explicit solvers requiring GPU-resident geometry embedding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a GPU-native algorithm for embedding stationary triangle-mesh geometries into block-structured forest-of-octrees grids for the Lattice Boltzmann Method. It performs solid voxelization and automated near-wall refinement entirely on the GPU using local ray casting accelerated by a hierarchy of spatial bins. This eliminates the need for CPU-GPU synchronization and common CPU data structures like hash tables. A flattened lookup table of cut-link distances is constructed to support interpolated bounce-back boundary conditions. The method is implemented as an extension to the AGAL framework, benchmarked on complex models such as the Stanford Bunny with 112K triangles and the XYZ RGB Dragon with 7.2M triangles, and validated on external flows past 2D cylinders and a 3D sphere at low Reynolds numbers, demonstrating accurate force predictions with modest overhead.
Significance. This work has the potential to significantly impact GPU-based computational fluid dynamics by providing a fully device-resident approach to handling complex geometries in adaptive mesh refinement settings. The strengths include the self-contained implementation without fitted parameters, the use of efficient grid-block traversal for coalesced memory access, and practical benchmarks on large triangle counts. If the ray-casting accuracy holds for complex meshes, it offers a general method applicable to other explicit solvers.
major comments (2)
- [§4.3] §4.3: Performance benchmarks for the Stanford Bunny (112K triangles) and Dragon (7.2M triangles) report only execution times and memory usage; no quantitative measures of voxelization accuracy, cut-cell classification rates, or cut-link distance errors are provided for these complex cases (unlike the cylinder and sphere results in §4.1–4.2). This directly bears on the central claim of reliable, CPU-free operation for arbitrary watertight meshes.
- [§4.1] §4.1: The 2D cylinder (Re=100) and square cylinder force-coefficient comparisons lack reported uncertainty from grid-convergence studies or explicit baseline references, limiting assessment of the interpolated bounce-back accuracy on adaptive grids.
minor comments (2)
- The description of the spatial bin hierarchy in the methods section would benefit from an explicit equation or pseudocode listing the bin traversal order and intersection test.
- Figure captions for the Dragon and Bunny visualizations should note the number of refinement levels and the near-wall cell size to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review of our manuscript. We address each major comment point by point below, indicating the revisions we will make to strengthen the presentation of results and validation.
read point-by-point responses
-
Referee: [§4.3] §4.3: Performance benchmarks for the Stanford Bunny (112K triangles) and Dragon (7.2M triangles) report only execution times and memory usage; no quantitative measures of voxelization accuracy, cut-cell classification rates, or cut-link distance errors are provided for these complex cases (unlike the cylinder and sphere results in §4.1–4.2). This directly bears on the central claim of reliable, CPU-free operation for arbitrary watertight meshes.
Authors: We agree that quantitative accuracy metrics for the complex models would provide additional support for the method's reliability. The Bunny and Dragon benchmarks in §4.3 are intended to demonstrate scalability, performance, and memory usage of the fully GPU-resident pipeline on large, real-world triangle counts (up to 7.2M triangles) rather than to serve as primary accuracy validation. These models are taken from the Stanford 3D Scanning Repository and treated as watertight. Obtaining independent ground-truth voxelizations or precise cut-link errors for such intricate geometries is non-trivial without a separate reference discretization. The correctness of the ray-casting, binning, and cut-link construction is instead established through the controlled validation cases in §4.1–4.2, where force coefficients match literature values. In the revised manuscript we will add an explicit statement in §4.3 clarifying the purpose of these benchmarks and note that accuracy for arbitrary meshes is inferred from the validated algorithm plus the watertight-mesh assumption. revision: partial
-
Referee: [§4.1] §4.1: The 2D cylinder (Re=100) and square cylinder force-coefficient comparisons lack reported uncertainty from grid-convergence studies or explicit baseline references, limiting assessment of the interpolated bounce-back accuracy on adaptive grids.
Authors: We acknowledge that explicit grid-convergence data and uncertainty estimates would improve the assessment of the interpolated bounce-back implementation on adaptive grids. The reported force coefficients are compared to established literature values obtained with other LBM and CFD methods at Re=100. To address this point, we will add a grid-convergence study for the circular-cylinder case in the revised manuscript. This will include results at successive refinement levels, the observed order of convergence, and estimated uncertainties in the drag and lift coefficients, thereby providing a quantitative basis for the accuracy of the boundary treatment on the forest-of-octrees grids. revision: yes
Circularity Check
Algorithmic implementation is self-contained with no reduction of claims to fitted inputs or self-citation chains
full rationale
The paper describes a GPU-native algorithm for voxelization and refinement using local ray-casting with spatial binning hierarchies, without any equations that derive performance metrics, accuracy measures, or boundary conditions from quantities fitted to the same data or meshes. Validation uses separate simple geometries (cylinders, sphere) for quantitative checks and complex models (Bunny, Dragon) only for performance benchmarks. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes; the method is presented as a direct implementation extension of the AGAL framework. The central claims rest on explicit algorithmic steps and empirical timing/force results rather than any definitional or fitted equivalence. This is a standard honest non-finding for an implementation-focused methods paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Input triangle meshes are closed, watertight, and stationary.
Reference graph
Works this paper leans on
-
[1]
M. J. Berger, J. Oliger, Adaptive mesh refinement for hyperbolic partial differential equations, Journal of Computational Physics 53 (3) (1984) 484–512. doi:10.1016/0021-9991(84)90073-1
-
[2]
M. J. Berger, R. J. LeVeque, Adaptive Mesh Refinement Using Wave-Propagation Algorithms for Hyperbolic Systems , SIAM Journal on Numerical Analysis 35 (6) (1998) 2298–2316. doi:10.1137/S0036142997315974. URL http://epubs.siam.org/doi/10.1137/S0036142997315974
-
[3]
Journal of Computational Physics , keywords =
M. Berger, P. Colella, Local adaptive mesh refinement for shock hydrodynamics , Journal of Computational Physics 82 (1) (1989) 64–84. doi:10.1016/0021-9991(89)90035-1 . URL https://www.jstor.org/stable/10.2307/3323192?origin=crossrefhttps://linkinghub.elsevier.com/retrieve/ pii/0021999189900351
-
[4]
A. Dubey, A. Almgren, J. Bell, M. Berzins, S. Brandt, G. Bryan, P. Colella, D. Graves, M. Lijewski, F. Löffler, B. O’Shea, E. Schnetter, B. Van Straalen, K. Weide, A survey of high level frameworks in block-structured adaptive mesh refinement packages, Journal of parallel and distributed computing 74 (12) (2014) 3217–3227. 45
work page 2014
-
[5]
A. Dubey, M. Berzins, C. Burstedde, M. L. Norman, D. Unat, M. Wahib, K. Hinsen, A. Dubey, I. U. S. Argonne National Lab. (ANL), Argonne, Structured adaptive mesh refinement adaptations to retain performance portability with increasing heterogeneity, Computing in science & engineering 23 (5) (2021) 62–66
work page 2021
-
[6]
C. Burstedde, L. C. Wilcox, O. Ghattas, p4est: Scalable algorithms for parallel adaptive mesh refinement on forests of octrees, SIAM Journal on Scientific Computing 33 (3) (2011) 1103–1133. doi:10.1137/100791634
-
[7]
J. Holke, J. Markert, D. Knapp, L. Dreyer, S. Elsweijer, N. Böing, I. Lilikakis, J. Fussbroich, T. Leistikow, F. Becker, V. Uenlue, O. Albers, C. Burstedde, A. Basermann, C. Hergl, W. Julia, K. Schoenlein, J. Ackerschott, A. Evgenii, Z. Csati, A. Dutka, B. Geihe, P. Kestener, A. Kirby, H. Ranocha, S.-L. Michael, t8code - modular adaptive mesh refinement i...
-
[8]
M. Wahib, N. Maruyama, T. Aoki, Daino: A High-Level Framework for Parallel and Efficient AMR on GPUs, International Conference for High Performance Computing, Networking, Storage and Analysis, SC 0 (November) (2016) 621–632. doi:10.1109/SC.2016.52
-
[9]
H.-Y. Schive, J. A. ZuHone, N. J. Goldbaum, M. J. Turk, M. Gaspari, C.-Y. Cheng, GAMER-2: a GPU-accelerated adaptive mesh refinement code – accuracy, performance, and scalability , Monthly Notices of the Royal Astronomical Society 481 (4) (2018) 4815–4840. doi:10.1093/mnras/sty2586. URL https://academic.oup.com/mnras/article/481/4/4815/5106358
-
[10]
X. Luo, L. Wang, W. Ran, F. Qin, Gpu accelerated cell-based adaptive mesh refinement on unstructured quadrilateral grid, Computer physics communications 207 (2016) 114–122
work page 2016
-
[11]
A. Giuliani, L. Krivodonova, Adaptive mesh refinement on graphics processing units for applications in gas dynamics , Journal of Computational Physics 381 (2019) 67–90. doi:10.1016/j.jcp.2018.12.019. URL https://doi.org/10.1016/j.jcp.2018.12.019
-
[12]
I. Menshov, P. Pavlukhin, GPU-native gas dynamic solver on octree-based AMR grids, Journal of Physics: Conference Series 1640 (1) (2020). doi:10.1088/1742-6596/1640/1/012017
-
[13]
P. V. Pavlukhin, I. S. Menshov, Gpu-native dynamic octree-based grid adaptation to moving bodies, Lobachevskii journal of mathematics 45 (1) (2024) 308–318
work page 2024
- [14]
-
[15]
D. Mierke, C. Janßen, T. Rung, An efficient algorithm for the calculation of sub-grid distances for higher-order lbm boundary conditions in a gpu simulation environment , Computers & Mathematics with Applications 79 (1) (2020) 66–87, mesoscopic Methods in Engineering and Science. doi:https://doi.org/10.1016/j.camwa.2018.04.022. URL https://www.sciencedirec...
- [16]
- [17]
-
[18]
S. C. G. Laboratory, The stanford 3d scanning repository, http://graphics.stanford.edu/data/3Dscanrep/, accessed: 2025-11-05
work page 2025
-
[19]
M. Schwarz, H.-P. Seidel, Fast parallel surface and solid voxelization on gpus , ACM Trans. Graph. 29 (6) (Dec. 2010). doi:10.1145/1882261.1866201. URL https://doi.org/10.1145/1882261.1866201
-
[20]
H. Jasak, Openfoam: open source cfd in research and industry, International Journal of Naval Architecture and Ocean Engineering 1 (2) (2009) 89–94
work page 2009
-
[21]
J. Holke, Scalable algorithms for parallel tree-based adaptive mesh refinement with general element types, Ph.D. thesis, Rheinische Friedrich-Wilhelms-Universität Bonn, Mathematisch-Naturwissenschaftliche Fakultät, Bonn, Germany, disser- tation zur Erlangung des Doktorgrades (Dr. rer. nat.) (Mar. 2018)
work page 2018
-
[22]
F. Schornbaum, U. Rüde, Extreme-scale block-structured adaptive mesh refinement, SIAM journal on scientific computing 40 (3) (2018) C358–C387
work page 2018
-
[23]
C. Stewart, C. Feichtinger, C. Godenschwager, C. Rettinger, C. Schwarzmeier, D. Ritter, D. Anderl, D. Staubach, D. Bar- tuschat, E. Fattahi, F. Winterhalter, F. Schornbaum, F. Hennig, G. Drozdov, H. Schottenhamml, I. Ostanin, J. Götz, J. Hönig, J. V. T. Risso, J. Habich, K. Iglberger, K. Pickl, L. Hufnagel, L. Werner, M. Holzer, M. Bauer, M. Markl, M. Kur...
-
[24]
L. Wang, F. Witherden, A. Jameson, An efficient gpu-based h-adaptation framework via linear trees for the flux recon- struction method, Journal of computational physics 502 (2024) 112823
work page 2024
-
[25]
Y. Wang, Y. Wu, Y. Zeng, M. Jiang, Z. Liu, An immersed boundary lattice boltzmann method on block-structured adaptive grids for the simulation of particle-laden flows on cpus/gpus , Computer Physics Communications 314 (2025) 109674. doi:https://doi.org/10.1016/j.cpc.2025.109674. URL https://www.sciencedirect.com/science/article/pii/S0010465525001766
-
[26]
Y. Wang, C. Zhong, J. Cao, C. Zhuo, S. Liu, A simplified finite volume lattice boltzmann method for simulations of fluid flows from laminar to turbulent regime, part i: Numerical framework and its application to laminar flow simulation , Computers & Mathematics with Applications 79 (5) (2020) 1590–1618. doi:https://doi.org/10.1016/j.camwa.2019. 09.017. 46...
-
[27]
J. A. Reyes Barraza, R. Deiterding, Towards a generalised lattice boltzmann method for aerodynamic simulations, Journal of Computational Science 45 (2020) 101182
work page 2020
-
[28]
A. Dupuis, B. Chopard, Theory and applications of an alternative lattice Boltzmann grid refinement algorithm , Physical Review E 67 (6) (2003) 066707. doi:10.1103/PhysRevE.67.066707. URL https://link.aps.org/doi/10.1103/PhysRevE.67.066707
-
[29]
M. Rohde, D. Kandhai, J. J. Derksen, H. E. A. van den Akker, A generic, mass conservative local grid refinement technique for lattice-Boltzmann schemes , International Journal for Numerical Methods in Fluids 51 (4) (2006) 439–468. doi:10.1002/fld.1140. URL https://onlinelibrary.wiley.com/doi/10.1002/fld.1140
-
[30]
D. Lagrava, O. Malaspinas, J. Latt, B. Chopard, Advances in multi-domain lattice boltzmann grid refinement, Journal of computational physics 231 (14) (2012) 4808–4822
work page 2012
-
[31]
T. Krüger, H. Kusumaatmaja, A. Kuzmin, O. Shardt, G. Silva, E. M. Viggen, The Lattice Boltzmann Method , Graduate Texts in Physics, Springer International Publishing, Cham, 2017. doi:10.1007/978-3-319-44649-3 . URL https://link.springer.com/book/10.1007/978-3-319-44649-3http://link.springer.com/10.1007/ 978-3-319-44649-3
-
[32]
O. Filippova, D. Hänel, Grid Refinement for Lattice-BGK Models , Journal of Computational Physics 147 (1) (1998) 219–
work page 1998
-
[33]
URL https://linkinghub.elsevier.com/retrieve/pii/S0021999198960892
doi:10.1006/jcph.1998.6089. URL https://linkinghub.elsevier.com/retrieve/pii/S0021999198960892
-
[34]
M. Bouzidi, M. Firdaouss, P. Lallemand, Momentum transfer of a boltzmann-lattice fluid with boundaries, Physics of fluids (1994) 13 (11) (2001) 3452–3459
work page 1994
-
[35]
I. Ginzburg, D. d’Humières, Multireflection boundary conditions for lattice boltzmann models, Physical review. E, Statis- tical, nonlinear, and soft matter physics 68 (6 Pt 2) (2003) 066614–066614
work page 2003
-
[36]
M. L. Sætra, A. R. Brodtkorb, K. A. Lie, Efficient GPU-Implementation of Adaptive Mesh Refinement for the Shallow- Water Equations, Journal of Scientific Computing 63 (1) (2015) 23–48. doi:10.1007/s10915-014-9883-4
-
[37]
D. Beckingsale, W. Gaudin, A. Herdman, S. Jarvis, Resident block-structured adaptive mesh refinement on thousands of graphics processing units, in: 2015 44th International Conference on Parallel Processing, IEEE, 2015, pp. 61–70
work page 2015
-
[38]
W. Zhang, A. Almgren, V. Beckner, J. Bell, J. Blaschke, C. Chan, M. Day, B. Friesen, K. Gott, D. Graves, M. Katz, A. Myers, T. Nguyen, A. Nonaka, M. Rosso, S. Williams, M. Zingale, AMReX: a framework for block-structured adaptive mesh refinement, Journal of Open Source Software 4 (37) (2019) 1370
work page 2019
-
[39]
P. Pavlukhin, I. Menshov, GPU-Aware AMR on Octree-Based Grids, in: V. Malyshkin (Ed.), Parallel Computing Tech- nologies, Springer International Publishing, Cham, 2019, pp. 214–220
work page 2019
-
[40]
S. Fang, H. Chen, Hardware accelerated voxelization, Computers & graphics 24 (3) (2000) 433–442
work page 2000
-
[41]
W. Li, Z. Fan, X. Wei, A. Kaufman, Flow simulation with complex boundaries, in: M. Pharr (Ed.), GPU Gems 2: Pro- gramming Techniques for High-Performance Graphics and General-Purpose Computation, Addison Wesley Professional, 2005, pp. 747–764
work page 2005
-
[42]
E. Eisemann, X. Décoret, Fast scene voxelization and applications , in: Proceedings of the 2006 Symposium on Interactive 3D Graphics and Games, I3D ’06, Association for Computing Machinery, New York, NY, USA, 2006, p. 71–78. doi: 10.1145/1111411.1111424. URL https://doi.org/10.1145/1111411.1111424
-
[43]
E. Eisemann, X. Décoret, Single-pass gpu solid voxelization for real-time applications, in: Proceedings of Graphics Interface 2008, GI ’08, Canadian Information Processing Society, CAN, 2008, p. 73–80
work page 2008
-
[44]
C. Crassin, S. Green, Octree-based sparse voxelization using the gpu hardware rasterizer, in: P. Cozzi, C. Riccio (Eds.), OpenGL Insights, CRC Press, 2012. doi:10.1201/b12288
-
[45]
M. Aleksandrov, S. Zlatanova, D. J. Heslop, Voxelisation algorithms and data structures: A review , Sensors 21 (24) (2021). doi:10.3390/s21248241. URL https://www.mdpi.com/1424-8220/21/24/8241
-
[46]
Akenine-Möller, Fast 3d triangle-box overlap testing , J
T. Akenine-Möller, Fast 3d triangle-box overlap testing , J. Graph. Tools 6 (1) (2002) 29–33. doi:10.1080/10867651.2001. 10487535. URL https://doi.org/10.1080/10867651.2001.10487535
-
[47]
S. Park, H. Shin, Efficient generation of adaptive cartesian mesh for computational fluid dynamics using gpu, International journal for numerical methods in fluids 70 (11) (2012) 1393–1404
work page 2012
-
[48]
J. J. Hasbestan, I. Senocak, Binarized-octree generation for cartesian adaptive mesh refinement around immersed geome- tries, Journal of Computational Physics 368 (2018) 179–195. doi:https://doi.org/10.1016/j.jcp.2018.04.039. URL https://www.sciencedirect.com/science/article/pii/S002199911830264X
-
[49]
C. F. Janßen, N. Koliha, T. Rung, A fast and rigorously parallel surface voxelization technique for gpu-accelerated cfd simulations, Communications in computational physics 17 (5) (2015) 1246–1270
work page 2015
-
[50]
T. Ma, P. Li, T. Ma, A three-dimensional cartesian mesh generation algorithm based on the gpu parallel ray casting method, Applied sciences 10 (1) (2020) 58–
work page 2020
-
[51]
R. Shukla, N. Arora, D. S. Banerjee, Voxelization of moving geometries on gpu, in: 2022 IEEE 24th Int Conf on High Performance Computing & Communications; 8th Int Conf on Data Science & Systems; 20th Int Conf on Smart City; 8th Int Conf on Dependability in Sensor, Cloud & Big Data Systems & Application (HPCC/DSS/SmartCity/DependSys), 2022, pp. 904–913. do...
work page doi:10.1109/hpcc-dss-smartcity-dependsys57074.2022.00146 2022
-
[52]
R. Kumar, R. Deep, D. S. Banerjee, N. Arora, Voxelization of moving deformable geometries on gpu, in: 2024 23rd International Symposium on Parallel and Distributed Computing (ISPDC), 2024, pp. 1–8. doi:10.1109/ISPDC62236. 47 2024.10705394
-
[53]
K. Zhou, Q. Hou, R. Wang, B. Guo, Real-time kd-tree construction on graphics hardware , ACM Trans. Graph. 27 (5) (Dec. 2008). doi:10.1145/1409060.1409079. URL https://doi.org/10.1145/1409060.1409079
-
[54]
J. Kalojanov, P. Slusallek, A parallel algorithm for construction of uniform grids , in: Proceedings of the Conference on High Performance Graphics 2009, HPG ’09, Association for Computing Machinery, New York, NY, USA, 2009, p. 23–28. doi:10.1145/1572769.1572773. URL https://doi.org/10.1145/1572769.1572773
-
[55]
C. Lauterbach, M. Garland, S. Sengupta, D. Luebke, D. Manocha, Fast bvh construction on gpus, Computer graphics forum 28 (2) (2009) 375–384
work page 2009
-
[56]
J. Pantaleoni, D. Luebke, Hlbvh: hierarchical lbvh construction for real-time ray tracing of dynamic geometry, in: Pro- ceedings of the Conference on High Performance Graphics, Eurographics Association, Goslar Germany, Germany, 2010, pp. 87–95
work page 2010
-
[57]
K. Garanzha, J. Pantaleoni, D. McAllister, S. N. Spencer, Simpler and faster hlbvh with work queues, in: Proceedings HPG 2011 : ACM SIGGRAPH Symposium on High Performance Graphics, Vancouver, British Columbia, Canada, August 5-7, 2011, ACM, New York, NY, USA, 2011, pp. 59–64
work page 2011
-
[58]
J. Kalojanov, M. Billeter, P. Slusallek, Two-level grids for ray tracing on gpus, Computer graphics forum 30 (2) (2011) 307–314
work page 2011
-
[59]
T. Karras, Maximizing parallelism in the construction of bvhs, octrees, and k-d trees, in: Proceedings of the Fourth ACM SIGGRAPH / Eurographics Conference on High-Performance Graphics, EGGH-HPG’12, Eurographics Association, Goslar, DEU, 2012, p. 33–37
work page 2012
-
[60]
S. Keller, A. Cavelan, R. Cabezon, L. Mayer, F. Ciorba, Cornerstone: Octree construction algorithms for scalable particle simulations, in: Proceedings of the Platform for Advanced Scientific Computing Conference, PASC ’23, Association for Computing Machinery, New York, NY, USA, 2023. doi:10.1145/3592979.3593417. URL https://doi.org/10.1145/3592979.3593417
-
[61]
Stanford Bunny.stl, https://commons.wikimedia.org/wiki/File:Stanford_Bunny.stl, downloaded from Wikimedia Commons, licensed under CC‑BY‑3.0 (Jan 23 2020)
work page 2020
-
[62]
J. Latt, O. Malaspinas, D. Kontaxakis, A. Parmigiani, D. Lagrava, F. Brogi, M. B. Belgacem, Y. Thorimbert, S. Leclaire, S. Li, F. Marson, J. Lemus, C. Kotsalos, R. Conradin, C. Coreixas, R. Petkantchin, F. Raynaud, J. Beny, B. Chopard, Palabos: Parallel lattice boltzmann solver, Computers & mathematics with applications 81 (1) (2021) 334–350
work page 2021
-
[63]
D. Russell, Z. Jane Wang, A cartesian grid method for modeling multiple moving objects in 2d incompressible viscous flow, Journal of Computational Physics 191 (1) (2003) 177–205. doi:https://doi.org/10.1016/S0021-9991(03)00310-3 . URL https://www.sciencedirect.com/science/article/pii/S0021999103003103
-
[64]
D. Calhoun, A cartesian grid method for solving the two-dimensional streamfunction-vorticity equations in irregular regions, Journal of Computational Physics 176 (2) (2002) 231–275. doi:https://doi.org/10.1006/jcph.2001.6970. URL https://www.sciencedirect.com/science/article/pii/S0021999101969700
-
[65]
C. Liu, X. Zheng, C. Sung, Preconditioned multigrid methods for unsteady incompressible flows , Journal of Computational Physics 139 (1) (1998) 35–57. doi:https://doi.org/10.1006/jcph.1997.5859. URL https://www.sciencedirect.com/science/article/pii/S0021999197958599
-
[66]
J.-I. Choi, R. C. Oberoi, J. R. Edwards, J. A. Rosati, An immersed boundary method for complex incompressible flows , Journal of Computational Physics 224 (2) (2007) 757–784. doi:https://doi.org/10.1016/j.jcp.2006.10.032. URL https://www.sciencedirect.com/science/article/pii/S0021999106005481
-
[67]
J. Kim, D. Kim, H. Choi, An immersed-boundary finite-volume method for simulations of flow in complex geometries , Journal of Computational Physics 171 (1) (2001) 132–150. doi:https://doi.org/10.1006/jcph.2001.6778. URL https://www.sciencedirect.com/science/article/pii/S0021999101967786
-
[68]
A. K. Saha, K. Muralidhar, G. Biswas, Transition and chaos in two-dimensional flow past a square cylinder, Journal of engineering mechanics 126 (5) (2000) 523–532
work page 2000
-
[69]
A. Fakhari, T. Lee, Finite-difference lattice boltzmann method with a block-structured adaptive-mesh-refinement tech- nique, Phys. Rev. E 89 (2014) 033310. doi:10.1103/PhysRevE.89.033310. URL https://link.aps.org/doi/10.1103/PhysRevE.89.033310
-
[70]
A. P. Singh, A. K. De, V. K. Carpenter, V. Eswaran, K. Muralidhar, Flow past a transversely oscillating square cylinder in free stream at low reynolds numbers , International Journal for Numerical Methods in Fluids 61 (6) (2009) 658–682. arXiv:https://onlinelibrary.wiley.com/doi/pdf/10.1002/fld.1979, doi:https://doi.org/10.1002/fld.1979. URL https://onlin...
-
[71]
A. Pavlov, S. Sazhin, R. Fedorenko, M. Heikal, A conservative finite difference method and its application for the analysis of a transient flow around a square prism , International Journal of Numerical Methods for Heat & Fluid Flow 10 (1) (2000) 6–47. arXiv:https://www.emerald.com/hff/article-pdf/10/1/6/650843/09615530010306894.pdf, doi:10.1108/ 09615530...
-
[72]
M. Mikhailov, A. S. Freire, The drag coefficient of a sphere: An approximation using shanks transform , Powder Technology 237 (2013) 432–435. doi:https://doi.org/10.1016/j.powtec.2012.12.033. URL https://www.sciencedirect.com/science/article/pii/S0032591012008327
-
[73]
F. W. Roos, W. W. Willmarth, Some experimental results on sphere and disk drag , AIAA Journal 9 (2) (1971) 285–291. arXiv:https://doi.org/10.2514/3.6164, doi:10.2514/3.6164. URL https://doi.org/10.2514/3.6164 48
-
[74]
P. P. Brown, D. F. Lawler, Sphere drag and settling velocity revisited , Journal of Environmental Engineering 129 (3) (2003) 222–231. arXiv:https://ascelibrary.org/doi/pdf/10.1061/\%28ASCE\%290733-9372\%282003\%29129\ %3A3\%28222\%29, doi:10.1061/(ASCE)0733-9372(2003)129:3(222). URL https://ascelibrary.org/doi/abs/10.1061/%28ASCE%290733-9372%282003%29129%...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.