Learning Multimodal Embeddings for Traffic Accident Prediction and Causal Estimation
Pith reviewed 2026-05-17 02:15 UTC · model grok-4.3
The pith
Combining satellite images with road network graphs predicts traffic accidents at 90.1% AUROC and identifies causal factors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
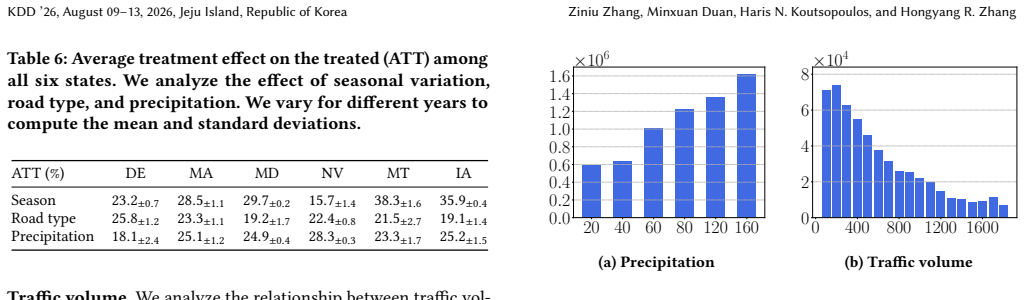
Integrating both visual and network embeddings improves prediction accuracy, achieving an average AUROC of 90.1%, a 3.7% gain over graph neural network models that use only graph structures. With the improved embeddings, a matching estimator identifies that accident rates rise by 24% under higher precipitation, by 22% on higher-speed roads such as motorways, and by 29% due to seasonal patterns, after adjusting for other confounding factors.
What carries the argument
Multimodal embeddings fusing satellite imagery features with graph neural network features on road network nodes.
If this is right
- Models achieve higher accuracy in forecasting accident locations when satellite data supplements road network information.
- Causal estimates indicate a 24% increase in accident rates with higher precipitation levels.
- Accident rates are 22% higher on motorways and similar high-speed roads.
- Seasonal patterns contribute to a 29% rise in accidents after adjustments.
- Removing satellite imagery features reduces model performance according to ablation studies.
Where Pith is reading between the lines
- The same multimodal setup could be tested on datasets from other countries or for predicting related events like near-misses.
- City planners might use these embeddings to simulate the impact of road changes on safety.
- Integration with real-time data streams could support proactive accident prevention alerts.
- Future work could explore whether the visual features capture specific elements like road markings or vegetation that affect visibility.
Load-bearing premise
Satellite imagery supplies predictive information about road surface and surroundings that is not already captured by the provided weather statistics, road type labels, and traffic volume features.
What would settle it
Training a graph-only model on the same dataset that reaches an AUROC of 90% or more without using satellite images would indicate that the visual modality is not necessary for the reported gains.
Figures




read the original abstract
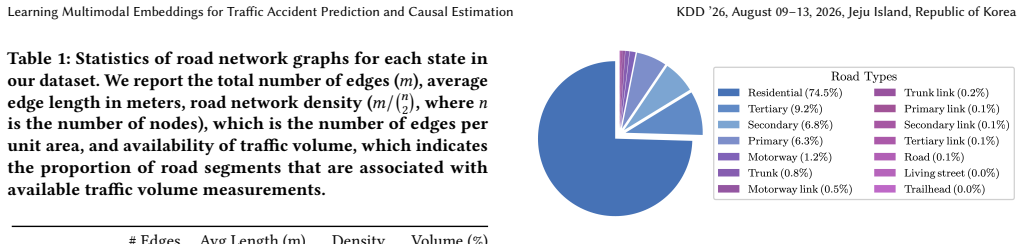
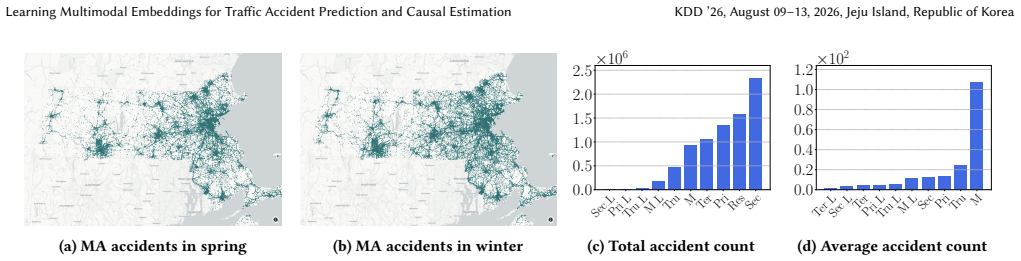
We consider analyzing traffic accident patterns using both road network data and satellite images aligned to road graph nodes. Previous work for predicting accident occurrences relies primarily on road network structural features while overlooking physical and environmental information from the road surface and its surroundings. In this work, we construct a large multimodal dataset spanning six U.S. states, containing nine million traffic accident records from official sources, and one million high-resolution satellite images for each node of the road network. Additionally, every node is annotated with features such as the region's weather statistics and road type (e.g., residential vs. motorway), and each edge is annotated with traffic volume information (i.e., Average Annual Daily Traffic). Utilizing this dataset, we conduct a comprehensive evaluation of multimodal learning methods that integrate both visual and network embeddings. Our findings show that integrating both data modalities improves prediction accuracy, achieving an average AUROC of $90.1\%$, a $3.7\%$ gain over graph neural network models that use only graph structures. With the improved embeddings, we conduct a causal analysis using a matching estimator to identify the key factors influencing traffic accidents. We find that accident rates rise by $24\%$ under higher precipitation, by $22\%$ on higher-speed roads such as motorways, and by $29\%$ due to seasonal patterns, after adjusting for other confounding factors. Ablation studies confirm that satellite imagery features are essential for achieving accurate prediction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper constructs a large multimodal dataset of road networks, satellite imagery, weather, road types, and traffic volumes across six U.S. states. It trains multimodal models that fuse graph embeddings with visual embeddings from satellite images to predict traffic accident occurrence, reporting an average AUROC of 90.1% (3.7% above graph-only GNN baselines). The learned embeddings are then used in a matching estimator to estimate causal effects, yielding reported increases of 24% under higher precipitation, 22% on motorways, and 29% due to seasonal patterns after covariate adjustment.
Significance. If the numerical claims are robust, the work shows that satellite imagery supplies complementary information about road surfaces and surroundings beyond standard tabular features, improving predictive performance on a large spatial graph task. The causal estimates, if credible, quantify the contribution of precipitation, road class, and seasonality to accident rates while adjusting for observed confounders, which could support targeted safety interventions. The scale of the released dataset (nine million accidents, one million images) is a concrete asset for the community.
major comments (3)
- Abstract and §4 (Results): the central AUROC claim of 90.1% and the 3.7% gain are reported without error bars, standard deviations across runs, or explicit train-test split details; given the spatial nature of the graph, this leaves open the possibility that the reported improvement is not statistically distinguishable from baseline variability or from leakage across nearby nodes.
- Causal analysis section (matching estimator): the 24%, 22%, and 29% effect sizes rest on the assumption that the multimodal embeddings plus listed covariates fully balance all confounders between treated and control units. No balance tables, sensitivity analysis for unmeasured confounding (e.g., enforcement intensity, driver demographics), or discussion of residual spatial autocorrelation are provided, which directly affects the validity of the causal interpretation.
- Experimental setup: the manuscript does not report an ablation on image resolution or preprocessing choices, nor does it quantify how much of the predictive gain is attributable to visual features versus the graph structure alone; these omissions make it hard to isolate the contribution of the satellite modality that is claimed to be essential.
minor comments (2)
- Clarify the exact alignment procedure between satellite image patches and graph nodes (e.g., centering, cropping radius) and whether any temporal mismatch exists between image acquisition dates and accident records.
- The ablation studies should include a table showing AUROC when each modality is removed individually, with the same train-test protocol used for the main results.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of robustness and interpretability that we will address in the revision. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: Abstract and §4 (Results): the central AUROC claim of 90.1% and the 3.7% gain are reported without error bars, standard deviations across runs, or explicit train-test split details; given the spatial nature of the graph, this leaves open the possibility that the reported improvement is not statistically distinguishable from baseline variability or from leakage across nearby nodes.
Authors: We agree that variability measures and split details are necessary to substantiate the claims. The full paper employs a spatial cross-validation scheme that holds out entire counties to reduce leakage from adjacent nodes. In the revised manuscript we will report standard deviations over five independent runs with different random seeds, include error bars on the AUROC figures, and add a statistical significance test for the 3.7% improvement over the graph-only baseline. revision: yes
-
Referee: Causal analysis section (matching estimator): the 24%, 22%, and 29% effect sizes rest on the assumption that the multimodal embeddings plus listed covariates fully balance all confounders between treated and control units. No balance tables, sensitivity analysis for unmeasured confounding (e.g., enforcement intensity, driver demographics), or discussion of residual spatial autocorrelation are provided, which directly affects the validity of the causal interpretation.
Authors: The matching estimator uses the multimodal embeddings to provide richer covariate balance than tabular features alone. We will add balance tables comparing treated and control groups before and after matching, include a sensitivity analysis for unmeasured confounding, and discuss residual spatial autocorrelation. While the embeddings capture visual and structural information that helps mitigate many spatial confounders, we cannot fully eliminate the possibility of unobserved factors such as enforcement intensity without external data. revision: partial
-
Referee: Experimental setup: the manuscript does not report an ablation on image resolution or preprocessing choices, nor does it quantify how much of the predictive gain is attributable to visual features versus the graph structure alone; these omissions make it hard to isolate the contribution of the satellite modality that is claimed to be essential.
Authors: The manuscript already contains modality ablations showing that satellite features are essential, but we accept that finer-grained analysis is warranted. We will add experiments varying image resolution and preprocessing pipelines, together with a table that isolates the incremental AUROC contribution of the visual embeddings over the graph-only model. revision: yes
- Complete proof that all possible unmeasured confounders have been eliminated in the causal estimates, since variables such as driver demographics and enforcement intensity are not present in the released dataset.
Circularity Check
No circularity: empirical prediction and standard matching estimator are independent of inputs
full rationale
The paper constructs a multimodal dataset, trains embedding models on held-out splits to report AUROC 90.1% (3.7% gain), and applies a matching estimator to the learned embeddings plus covariates to obtain the 24%/22%/29% causal estimates. These quantities are measured outcomes on unseen data and from a standard statistical procedure; no equation, definition, or self-citation reduces them to the training inputs by construction. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- model hyperparameters and embedding dimensions
axioms (2)
- domain assumption Satellite images contain road-surface and environmental signals relevant to accident risk beyond weather statistics and road-type labels
- domain assumption The matching estimator balances all relevant confounders between locations with different precipitation levels
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We conduct a causal analysis using a matching estimator... accident rates rise by 24% under higher precipitation... ATT scores for seasonal variation, road type, and precipitation are 28.6%, 21.9%, and 24.2%.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
GIN + MoE... average AUROC of 90.1%, a 3.7% gain over graph neural network models that use only graph structures.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Roadtracer: Automatic extraction of road networks from aerial images
F. Bastani, S. He, S. Abbar, M. Alizadeh, H. Balakrishnan, S. Chawla, S. Madden, and D. DeWitt. “Roadtracer: Automatic extraction of road networks from aerial images”. In:Computer Vision and Pattern Recognition (CVPR). 2018, pp. 4720– 4728 (8, 9)
work page 2018
-
[2]
L. J. Blincoe, T. R. Miller, E. Zaloshnja, and B. Lawrence.The economic and societal impact of motor vehicle crashes, 2010 (Revised). Tech. rep. United States. Department of Transportation. National Highway Traffic Safety Administra- tion, 2015 (1)
work page 2010
-
[3]
TEMPO: Prompt- based Generative Pre-trained Transformer for Time Series Forecasting
D. Cao, F. Jia, S. O. Arik, T. Pfister, Y. Zheng, W. Ye, and Y. Liu. “TEMPO: Prompt- based Generative Pre-trained Transformer for Time Series Forecasting”. In: International Conference on Learning Representations (ICLR). 2024 (8). KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea Ziniu Zhang, Minxuan Duan, Haris N. Koutsopoulos, and Hongyang R. Zhang
work page 2024
-
[4]
FT-AED: Benchmark dataset for early freeway traffic anomalous event detection
A. Coursey, J. Ji, M. Quinones Grueiro, W. Barbour, Y. Zhang, T. Derr, G. Biswas, and D. Work. “FT-AED: Benchmark dataset for early freeway traffic anomalous event detection”. In:Advances in Neural Information Processing Systems (NeurIPS)37 (2024), pp. 15526–15549 (9)
work page 2024
-
[5]
Multimodal learning with graphs
Y. Ektefaie, G. Dasoulas, A. Noori, M. Farhat, and M. Zitnik. “Multimodal learning with graphs”. In:Nature Machine Intelligence5.4 (2023), pp. 340–350 ( 8)
work page 2023
-
[6]
Roadtagger: Robust road attribute inference with graph neural networks
S. He, F. Bastani, S. Jagwani, E. Park, S. Abbar, M. Alizadeh, H. Balakrishnan, S. Chawla, S. Madden, and M. A. Sadeghi. “Roadtagger: Robust road attribute inference with graph neural networks”. In:Association for the Advancement of Artificial Intelligence (AAAI). 2020, pp. 10965–10972 (8)
work page 2020
-
[7]
Inferring high-resolution traffic accident risk maps based on satellite imagery and GPS trajectories
S. He, M. A. Sadeghi, S. Chawla, M. Alizadeh, H. Balakrishnan, and S. Madden. “Inferring high-resolution traffic accident risk maps based on satellite imagery and GPS trajectories”. In:International Conference on Computer Vision (ICCV). 2021, pp. 11957–11965 (1, 8)
work page 2021
-
[8]
Inferring high-resolution traffic accident risk maps based on satellite imagery and GPS trajectories
S. He, M. A. Sadeghi, S. Chawla, M. Alizadeh, H. Balakrishnan, and S. Madden. “Inferring high-resolution traffic accident risk maps based on satellite imagery and GPS trajectories”. In:International Conference on Computer Vision (ICCV). 2021, pp. 11977–11985 (8)
work page 2021
-
[9]
Tap: A comprehensive data repository for traffic accident prediction in road networks
B. Huang, B. Hooi, and K. Shu. “Tap: A comprehensive data repository for traffic accident prediction in road networks”. In:Proceedings of the 31st ACM International Conference on Advances in Geographic Information Systems. 2023, pp. 1–4 (2)
work page 2023
-
[10]
Travel time estimation for urban road networks using low frequency probe vehicle data
E. Jenelius and H. N. Koutsopoulos. “Travel time estimation for urban road networks using low frequency probe vehicle data”. In:Transportation Research Part B: Methodological53 (2013), pp. 64–81 (1)
work page 2013
-
[11]
Generalization in graph neural networks: Improved pac-bayesian bounds on graph diffusion
H. Ju, D. Li, A. Sharma, and H. R. Zhang. “Generalization in graph neural networks: Improved pac-bayesian bounds on graph diffusion”. In:International conference on artificial intelligence and statistics. PMLR. 2023, pp. 6314–6341 (8)
work page 2023
-
[12]
Crashformer: A multimodal architecture to predict the risk of crash
A. Karimi Monsefi, P. Shiri, A. Mohammadshirazi, N. Karimi Monsefi, R. Davies, S. Moosavi, and R. Ramnath. “Crashformer: A multimodal architecture to predict the risk of crash”. In:ACM SIGSPATIAL International Workshop on Advances in Urban-AI. 2023, pp. 42–51 (9)
work page 2023
-
[13]
Boosting multitask learning on graphs through higher-order task affinities
D. Li, H. Ju, A. Sharma, and H. R. Zhang. “Boosting multitask learning on graphs through higher-order task affinities”. In:ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD). 2023, pp. 1213–1222 (8)
work page 2023
-
[14]
Identification of Negative Transfers in Multitask Learning Using Surrogate Models
D. Li, H. Nguyen, and H. R. Zhang. “Identification of Negative Transfers in Multitask Learning Using Surrogate Models”. In:Transactions on Machine Learning Research(2024) (6)
work page 2024
-
[15]
Scalable Multitask Learning Using Gradient- based Estimation of Task Affinity
D. Li, A. Sharma, and H. R. Zhang. “Scalable Multitask Learning Using Gradient- based Estimation of Task Affinity”. In:ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD). 2024, pp. 1542–1553 (8)
work page 2024
-
[16]
Scalable Fine-tuning from Multiple Data Sources: A First-Order Approximation Approach
D. Li, Z. Zhang, L. Wang, and H. R. Zhang. “Scalable Fine-tuning from Multiple Data Sources: A First-Order Approximation Approach”. In:Findings of the Association for Computational Linguistics: EMNLP 2024(2024) (8)
work page 2024
-
[17]
Efficient Ensemble for Fine-tuning Language Models on Multiple Datasets
D. Li, Z. Zhang, L. Wang, and H. R. Zhang. “Efficient Ensemble for Fine-tuning Language Models on Multiple Datasets”. In:Association for Computational Linguistics (ACL). 2025 (8)
work page 2025
-
[18]
R. Li, Y. Xie, X. Jia, D. Wang, Y. Li, Y. Zhang, Z. Wang, and Z. Li. “SolarCube: An Integrative Benchmark Dataset Harnessing Satellite and In-situ Observations for Large-scale Solar Energy Forecasting”. In:Advances in Neural Information Processing Systems (NeurIPS)37 (2024), pp. 3499–3513 (8, 9)
work page 2024
-
[19]
Diffusion Convolutional Recurrent Neural Network: Data-Driven Traffic Forecasting
Y. Li, R. Yu, C. Shahabi, and Y. Liu. “Diffusion Convolutional Recurrent Neural Network: Data-Driven Traffic Forecasting”. In:International Conference on Learning Representations (ICLR). 2018 (1, 5, 8, 9)
work page 2018
-
[20]
Urbangpt: Spatio- temporal large language models
Z. Li, L. Xia, J. Tang, Y. Xu, L. Shi, L. Xia, D. Yin, and C. Huang. “Urbangpt: Spatio- temporal large language models”. In:ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD). 2024, pp. 5351–5362 (8)
work page 2024
-
[21]
When physics meets ma- chine learning: A survey of physics-informed machine learning
C. Meng, S. Griesemer, D. Cao, S. Seo, and Y. Liu. “When physics meets ma- chine learning: A survey of physics-informed machine learning”. In:Machine Learning for Computational Science and Engineering1.1 (2025), p. 20 (1)
work page 2025
-
[22]
National Highway Traffic Safety Administration.Early Estimate of Motor Vehicle Traffic Fatalities for 2024. Tech. rep. U.S. Department of Transportation, 2025 ( 1)
work page 2024
-
[23]
Graph neural net- works for road safety modeling: Datasets and evaluations for accident analy- sis
A. Nippani, D. Li, H. Ju, H. Koutsopoulos, and H. Zhang. “Graph neural net- works for road safety modeling: Datasets and evaluations for accident analy- sis”. In:Advances in neural information processing systems (NeurIPS)36 (2023), pp. 52009–52032 (1, 2, 4, 9)
work page 2023
-
[24]
W. H. Organization.Global status report on road safety 2018. Geneva, Switzer- land: World Health Organization, 2019 (1)
work page 2018
-
[25]
Deepwalk: Online learning of social representations
B. Perozzi, R. Al-Rfou, and S. Skiena. “Deepwalk: Online learning of social representations”. In:International Conference on Knowledge Discovery and Data Mining (KDD). New York City, USA: ACM, 2014, pp. 701–710 (5)
work page 2014
-
[26]
Graphgpt: Graph instruction tuning for large language models
J. Tang, Y. Yang, W. Wei, L. Shi, L. Su, S. Cheng, D. Yin, and C. Huang. “Graphgpt: Graph instruction tuning for large language models”. In:ACM SIGIR Conference on Research and Development in Information Retrieval. 2024, pp. 491–500 (8)
work page 2024
-
[27]
Higpt: Hetero- geneous graph language model
J. Tang, Y. Yang, W. Wei, L. Shi, L. Xia, D. Yin, and C. Huang. “Higpt: Hetero- geneous graph language model”. In:ACM SIGKDD conference on knowledge discovery and data mining (KDD). 2024, pp. 2842–2853 (8)
work page 2024
-
[28]
MG-TAR: Multi-view graph convolutional networks for traffic accident risk prediction
P. Trirat, S. Yoon, and J.-G. Lee. “MG-TAR: Multi-view graph convolutional networks for traffic accident risk prediction”. In:IEEE Transactions on Intelligent Transportation Systems24.4 (2023), pp. 3779–3794 (8)
work page 2023
-
[29]
M. Veillette, S. Samsi, and C. Mattioli. “Sevir: A storm event imagery dataset for deep learning applications in radar and satellite meteorology”. In:Advances in Neural Information Processing Systems (NeurIPS)33 (2020), pp. 22009–22019 (9)
work page 2020
-
[30]
OAM-TCD: A globally diverse dataset of high-resolution tree cover maps
J. Veitch-Michaelis, A. Cottam, D. Schweizer, E. Broadbent, D. Dao, C. Zhang, A. Almeyda Zambrano, and S. Max. “OAM-TCD: A globally diverse dataset of high-resolution tree cover maps”. In:Advances in Neural Information Processing Systems (NeurIPS)37 (2024), pp. 49749–49767 (8, 9)
work page 2024
-
[31]
P. Velickovic, G. Cucurull, A. Casanova, A. Romero, P. Lio, and Y. Bengio. “Graph attention networks”. In:stat1050.20 (2017), pp. 10–48550 (5)
work page 2017
-
[32]
Q. Wang, S. Wang, Y. Zheng, H. Lin, X. Zhang, J. Zhao, and J. Walker. “Deep hybrid model with satellite imagery: How to combine demand modeling and computer vision for travel behavior analysis?” In:Transportation Research Part B: Methodological181 (2024), p. 102914 (1)
work page 2024
-
[33]
S. Wang, B. Mo, Y. Zheng, S. Hess, and J. Zhao. “Comparing hundreds of machine learning and discrete choice models for travel demand modeling: An empirical benchmark”. In:Transportation Research Part B: Methodological190 (2024), p. 103061 (2)
work page 2024
-
[34]
Q. Wu, Z. Chen, W. Corcoran, M. Sra, and A. Singh. “GraphEval36K: Bench- marking Coding and Reasoning Capabilities of Large Language Models on Graph Datasets”. In:Findings of the Association for Computational Linguistics: NAACL 2025. 2025, pp. 8095–8117 (1)
work page 2025
-
[35]
Understanding and Improving Information Transfer in Multi-Task Learning
S. Wu, H. R. Zhang, and C. Ré. “Understanding and Improving Information Transfer in Multi-Task Learning”. In:International Conference on Learning Representations. 2020 (6)
work page 2020
-
[36]
Precise high-dimensional asymptotics for quantifying heterogeneous transfers
F. Yang, H. R. Zhang, S. Wu, C. Ré, and W. J. Su. “Precise high-dimensional asymptotics for quantifying heterogeneous transfers”. In:Journal of Machine Learning Research26.113 (2025), pp. 1–88 (6)
work page 2025
-
[37]
A microscopic traffic simulator for evaluation of dynamic traffic management systems
Q. Yang and H. N. Koutsopoulos. “A microscopic traffic simulator for evaluation of dynamic traffic management systems”. In:Transportation research part C: emerging technologies4.3 (1996), pp. 113–129 (1)
work page 1996
-
[38]
Revisiting spatial-temporal similarity: A deep learning framework for traffic prediction
H. Yao, X. Tang, H. Wei, G. Zheng, and Z. Li. “Revisiting spatial-temporal similarity: A deep learning framework for traffic prediction”. In:Association for the Advancement of Artificial Intelligence (AAAI). 2019, pp. 5668–5675 (1)
work page 2019
-
[39]
Spatio-Temporal Graph Convolutional Networks: A Deep Learning Framework for Traffic Forecasting
B. Yu, H. Yin, and Z. Zhu. “Spatio-Temporal Graph Convolutional Networks: A Deep Learning Framework for Traffic Forecasting”. In:International Joint Conference on Artificial Intelligence (IJCAI). 2018, pp. 3634–3640 (8)
work page 2018
-
[40]
Z. Yuan, X. Zhou, and T. Yang. “Hetero-convlstm: A deep learning approach to traffic accident prediction on heterogeneous spatio-temporal data”. In:Proceed- ings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 2018, pp. 984–992 (2)
work page 2018
-
[41]
Linear-Time Demonstration Selection for In-Context Learning via Gradient Estimation
Z. Zhang, Z. Zhang, D. Li, L. Wang, J. Dy, and H. R. Zhang. “Linear-Time Demonstration Selection for In-Context Learning via Gradient Estimation”. In:Conference on Empirical Methods in Natural Language Processing (EMNLP). 2025, pp. 16470–16488 (8)
work page 2025
-
[42]
AllClear: A Comprehensive Dataset and Benchmark for Cloud Removal in Satellite Imagery
H. Zhou, C. H. Kao, C. P. Phoo, U. Mall, B. Hariharan, and K. Bala. “AllClear: A Comprehensive Dataset and Benchmark for Cloud Removal in Satellite Imagery”. In:Advances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track37 (2024), pp. 53571–53597 (8)
work page 2024
-
[43]
Tumtraffic-videoqa: A benchmark for unified spatio-temporal video understanding in traffic scenes
X. Zhou, K. Larintzakis, H. Guo, W. Zimmer, M. Liu, H. Cao, J. Zhang, V. Laksh- minarasimhan, L. Strand, and A. C. Knoll. “Tumtraffic-videoqa: A benchmark for unified spatio-temporal video understanding in traffic scenes”. In:Interna- tional Conference on Machine Learning (ICML). PMLR, 2025 (9)
work page 2025
-
[44]
D. Zhuang, Y. Bu, G. Wang, S. Wang, and J. Zhao. “Sauc: Sparsity-aware uncer- tainty calibration for spatiotemporal prediction with graph neural networks”. In:ACM International Conference on Advances in Geographic Information Sys- tems (SIGSPATIAL). 2024, pp. 160–172 (1)
work page 2024
-
[45]
D. Zhuang, S. Wang, H. Koutsopoulos, and J. Zhao. “Uncertainty quantification of sparse travel demand prediction with spatial-temporal graph neural net- works”. In:ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD). 2022, pp. 4639–4647 (1). Learning Multimodal Embeddings for Traffic Accident Prediction and Causal Estimation KDD ’26, August...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.