Tumor-anchored deep feature random forests for out-of-distribution detection in lung cancer segmentation
Pith reviewed 2026-05-17 00:02 UTC · model grok-4.3
The pith
A random forest trained on deep features anchored to predicted tumor regions detects out-of-distribution lung CT scans at over 93 percent AUROC with only 40 labeled examples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
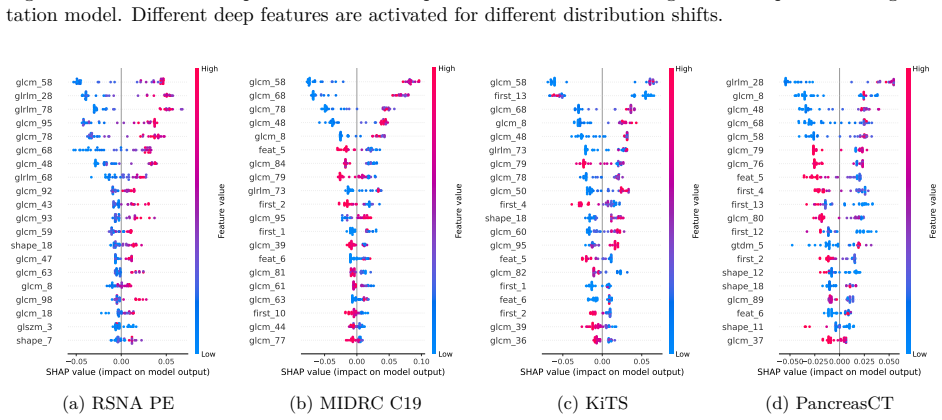
RF-Deep repurposes hierarchical activations from a pretrained-then-finetuned segmentation backbone by collecting them from multiple regions-of-interest centered on the model's predicted tumor regions, then trains a random forest on those descriptors with as few as 20 in-distribution and 20 OOD scans. On 2232 CT volumes this yields AUROC above 93 on near-OOD sets (pulmonary embolism, COVID-negative) and above 99 on far-OOD sets (kidney cancer, healthy pancreas), with transfer to blinded sets (COVID-positive, breast cancer) above 94 under ensemble use.
What carries the argument
Tumor-anchored feature aggregation that pools hierarchical deep activations from regions-of-interest centered on the segmentation model's own predicted tumor mask before random-forest classification.
If this is right
- Existing segmentation pipelines can insert a lightweight post-hoc filter that rejects or flags scans before erroneous tumor outlines are produced.
- Only twenty OOD examples suffice to train the detector, allowing adaptation to new scanner sites or protocols with modest labeling effort.
- The same detector works across segmentation backbones of different depths and pretraining strategies without retraining the main model.
- Ensemble versions of the detector maintain high performance on completely unseen clinical validation sets such as COVID-positive and breast-cancer CT scans.
Where Pith is reading between the lines
- Anchoring features to the predicted tumor rather than the entire image may reduce irrelevant anatomical noise and focus detection on the region that matters most for treatment planning.
- Even if the segmentation backbone itself is unreliable on OOD inputs, the mismatch in its own internal features around the predicted tumor can still provide a usable detection signal.
- The method could be combined with uncertainty maps already produced by the segmentor to create a stronger two-stage safety check.
- In hospital deployment the random forest would need periodic retraining on new scanner data to prevent performance drift from protocol changes.
Load-bearing premise
That deep features taken only from regions around the model's predicted tumor contain enough mismatch signal for a random forest to separate in-distribution from out-of-distribution scans when trained on just forty labeled examples.
What would settle it
A test collection of near-OOD lung CT scans in which the segmentation model produces accurate tumor outlines yet RF-Deep assigns low out-of-distribution scores, or in which the detector incorrectly flags many routine in-distribution scans.
Figures









read the original abstract
Accurate segmentation of lung tumors from 3D computed tomography (CT) scans is essential for automated treatment planning and response assessment. Despite self-supervised pretraining on numerous datasets, state-of-the-art transformer backbones remain susceptible to out-of-distribution (OOD) inputs, often producing confidently incorrect segmentations with potential for risk in clinical deployment. Hence, we introduce RF-Deep, a lightweight post-hoc random forests-based framework that leverages deep features trained with limited outlier exposure, requiring as few as 40 labeled scans (20 in-distribution and 20 OOD), to improve scan-level OOD detection. RF-Deep repurposes the hierarchical features from the pretrained-then-finetuned segmentation backbones, aggregating features from multiple regions-of-interest anchored to predicted tumor regions to capture OOD likelihood. We evaluated RF-Deep on 2,232 CT volumes spanning near-OOD (pulmonary embolism, COVID-19 negative) and far-OOD (kidney cancer, healthy pancreas) datasets. RF-Deep achieved AUROC >~93 on the challenging near-OOD datasets, where it outperformed the next best method by 4--7 percentage points, and produced near-perfect detection (AUROC >~99) on far-OOD datasets. The approach also showed transferability to two blinded validation datasets under the ensemble configuration (COVID-19 positive and breast cancer; AUROC >~94). RF-Deep maintained consistent performance across backbones of different depths and pretraining strategies, demonstrating applicability of post-hoc detectors as a safety filter for clinical deployment of tumor segmentation pipelines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RF-Deep, a lightweight post-hoc framework that trains random forests on hierarchical deep features extracted from a pretrained segmentation backbone and aggregated only from regions-of-interest anchored to the model's own predicted tumor masks. Using as few as 40 labeled scans (20 ID + 20 OOD), the method is evaluated for scan-level OOD detection on 2,232 CT volumes spanning near-OOD (pulmonary embolism, COVID-negative) and far-OOD (kidney cancer, healthy pancreas) datasets, with additional transfer tests on blinded sets. It reports AUROC >~93 on near-OOD (outperforming the next-best baseline by 4-7 points) and >~99 on far-OOD, while remaining consistent across different backbone depths and pretraining strategies.
Significance. If the reported AUROC gains are reproducible and the tumor-anchored aggregation is shown to be robust rather than an artifact of the small training set, the work would provide a practical, low-data safety filter for clinical deployment of lung-tumor segmentation models. The approach's post-hoc nature and limited supervision requirement are attractive for real-world use where full retraining is costly.
major comments (3)
- [Abstract / Methods] Abstract and Methods: The central performance claim rests on feature aggregation from ROIs defined by the segmentation model's predicted tumor mask. On near-OOD inputs the model is already known to produce confidently wrong segmentations; if the predicted mask is empty, tiny, or mislocalized, the aggregated features are drawn from background or artifact regions. No statistics on predicted-mask volume, overlap with ground truth, or failure rate on the OOD test sets are reported, nor is an ablation against full-volume or random-region aggregation provided. This leaves open whether the anchoring contributes signal or merely enables memorization of spurious correlations from the 40-scan training set.
- [Results] Results: AUROC values are reported without error bars, confidence intervals, or statistical significance tests for the 4-7 point gains over baselines. With only 20 OOD training scans and no detail on how the OOD labels were obtained or how the baseline detectors were re-implemented, it is difficult to judge whether the improvements are stable or sensitive to the particular choice of 20 OOD examples.
- [Experiments] Experiments: The manuscript states that RF-Deep maintains consistent performance across backbones of different depths and pretraining strategies, yet provides no quantitative table or figure showing per-backbone AUROC on the same OOD splits. Without these numbers it is impossible to verify the claimed robustness.
minor comments (2)
- [Abstract] The abstract uses the approximate symbol '~' for AUROC thresholds; exact values and the number of runs should be stated in the main text or tables.
- [Methods] Clarify the exact random-forest hyperparameters (number of trees, maximum depth, feature sampling) and whether they were tuned on a validation split or fixed a priori.
Simulated Author's Rebuttal
We thank the referee for the insightful comments, which have helped us identify areas to strengthen our manuscript. We address each major comment below and will make the necessary revisions to improve clarity and robustness of the presented results.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and Methods: The central performance claim rests on feature aggregation from ROIs defined by the segmentation model's predicted tumor mask. On near-OOD inputs the model is already known to produce confidently wrong segmentations; if the predicted mask is empty, tiny, or mislocalized, the aggregated features are drawn from background or artifact regions. No statistics on predicted-mask volume, overlap with ground truth, or failure rate on the OOD test sets are reported, nor is an ablation against full-volume or random-region aggregation provided. This leaves open whether the anchoring contributes signal or merely enables memorization of spurious correlations from the 40-scan training set.
Authors: We agree that this is a critical point to address for validating the tumor-anchored approach. In the revised version, we will report statistics on the predicted tumor mask volumes (e.g., mean and distribution of mask sizes), Dice overlap with ground truth where available for ID cases, and failure rates (e.g., empty mask percentage) on both ID and OOD test sets. Furthermore, we will include an ablation study comparing our tumor-anchored aggregation to full-volume feature aggregation and random-region sampling. This will demonstrate that the anchoring provides meaningful signal beyond potential spurious correlations in the small training set. revision: yes
-
Referee: [Results] Results: AUROC values are reported without error bars, confidence intervals, or statistical significance tests for the 4-7 point gains over baselines. With only 20 OOD training scans and no detail on how the OOD labels were obtained or how the baseline detectors were re-implemented, it is difficult to judge whether the improvements are stable or sensitive to the particular choice of 20 OOD examples.
Authors: We acknowledge the need for more rigorous statistical reporting. The revised manuscript will include error bars (standard deviation over multiple random seeds or cross-validation splits) and 95% confidence intervals for all AUROC values. We will also conduct and report statistical significance tests, such as DeLong's test for comparing AUROCs. Additionally, we will expand the methods section to detail how the OOD labels were sourced from the respective public datasets and provide specifics on the re-implementation of baseline methods to facilitate reproducibility and assessment of stability. revision: yes
-
Referee: [Experiments] Experiments: The manuscript states that RF-Deep maintains consistent performance across backbones of different depths and pretraining strategies, yet provides no quantitative table or figure showing per-backbone AUROC on the same OOD splits. Without these numbers it is impossible to verify the claimed robustness.
Authors: We apologize for not including these details in the original submission. In the revision, we will add a table (or supplementary figure) presenting the AUROC values for each backbone variant (different depths and pretraining strategies) on the identical OOD evaluation splits. This will quantitatively support the consistency claim and allow readers to assess the robustness across architectures. revision: yes
Circularity Check
No significant circularity in empirical RF-Deep method
full rationale
The paper presents an empirical post-hoc framework in which a random forest is trained on hierarchical features extracted from a segmentation backbone and aggregated from regions anchored to the model's predicted tumor masks, using an external set of 20 ID + 20 OOD labeled scans. No equations, uniqueness theorems, or self-citation chains are invoked that reduce the final AUROC or OOD score to a quantity defined by the same fitted parameters or by construction. Performance is measured on held-out external near-OOD and far-OOD volumes, rendering the central claim independent of any internal definitional loop.
Axiom & Free-Parameter Ledger
free parameters (1)
- Random forest hyperparameters (trees, depth, feature sampling)
axioms (1)
- domain assumption Deep features from a segmentation backbone contain information usable for distinguishing in-distribution from out-of-distribution CT volumes when aggregated around predicted tumor locations.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
RF-Deep repurposes the hierarchical features from the pretrained-then-finetuned segmentation backbones, aggregating features from multiple regions-of-interest anchored to predicted tumor regions
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We extracted deep feature representations from n=4 tumor-anchored 3D ROIs per scan ... random forest classifiers employed 1,000 trees
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Brennan Nichyporuk, Jillian Cardinell, Justin Szeto, Raghav Mehta, Jean-Pierre Falet, Douglas L
Springer Nature Switzerland. Brennan Nichyporuk, Jillian Cardinell, Justin Szeto, Raghav Mehta, Jean-Pierre Falet, Douglas L. Arnold, Sotirios A. Tsaftaris, and Tal Arbel. Rethinking generalization: The impact of annotation style on medical image segmentation.Machine Learning for Biomedical Imaging, 2022. Maxime Oquab, Timothée Darcet, Theo Moutakanni, Hu...
work page 2022
-
[2]
IEEE. Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 2019. Walter HL Pinaya, Petru-Daniel Tudosiu, Robert Gray, Geraint Rees, Paras...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.