Robust Mesh Saliency Ground Truth Acquisition in VR via View Cone Sampling and Manifold Diffusion
Pith reviewed 2026-05-16 17:54 UTC · model grok-4.3
The pith
View cone sampling paired with hybrid manifold-Euclidean diffusion yields reliable ground-truth saliency maps for 3D meshes viewed in VR.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
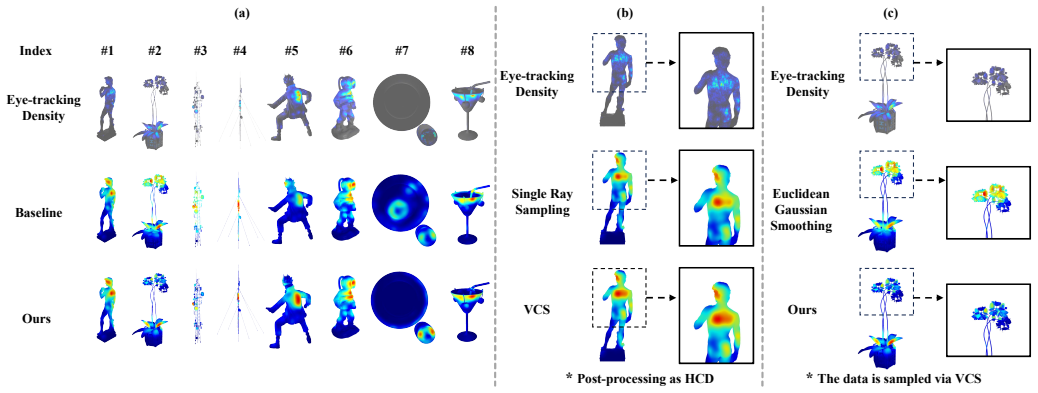
The central claim is that Gaussian-weighted view-cone sampling combined with a hybrid diffusion process constrained simultaneously by manifold geodesic distances and Euclidean scales produces saliency values that remain topologically consistent on complex meshes and align more closely with human visual attention than single-ray baselines.
What carries the argument
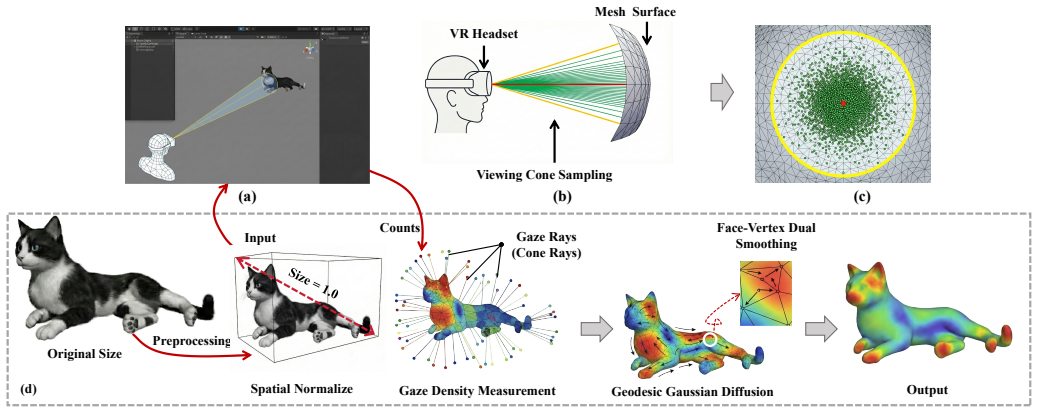
View cone sampling (VCS) that fires Gaussian-distributed ray bundles from each surface point to capture contextual features, together with hybrid manifold-Euclidean constrained diffusion (HCD) that propagates saliency while preventing leakage across disconnected regions.
If this is right
- Saliency maps become continuous and free of texture aliasing on surfaces with fine detail.
- Attention values no longer spread across physical gaps that have no connecting surface path.
- The resulting data set supplies a cleaner baseline for training any downstream 3D saliency predictor.
- Downstream VR rendering and compression pipelines can allocate resources more precisely to attended regions.
Where Pith is reading between the lines
- The same cone-plus-manifold principle could be applied to attention modeling in augmented-reality overlays where real and virtual surfaces coexist.
- Any diffusion process performed on mesh data would benefit from the same dual-distance constraint to avoid topological shortcuts.
- Real-time implementations could use the method to drive foveated rendering without requiring additional eye-tracking hardware.
Load-bearing premise
Gaussian ray bundles inside a view cone accurately reproduce the human foveal receptive field and the hybrid diffusion step adds no new inconsistencies when it respects both surface and straight-line distances.
What would settle it
A controlled test on a mesh containing known disconnected components in which the new maps show saliency values leaking between those components, or a side-by-side comparison against real eye-tracking recordings on the same models that fails to show higher correlation than single-ray methods.
Figures


read the original abstract
As the complexity of 3D digital content grows exponentially, understanding human visual attention is critical for optimizing rendering and processing resources. Therefore, reliable 3D mesh saliency ground truth (GT) is essential for human-centric visual modeling in virtual reality (VR). However, existing VR eye-tracking frameworks are fundamentally bottlenecked by their underlying acquisition and generation mechanisms. The reliance on zero-area single ray sampling (SRS) fails to capture contextual features, leading to severe texture aliasing and discontinuous saliency signals. And the conventional application of Euclidean smoothing propagates saliency across disconnected physical gaps, resulting in semantic confusion on complex 3D manifolds. This paper proposes a robust framework to address these limitations. We first introduce a view cone sampling (VCS) strategy, which simulates the human foveal receptive field via Gaussian-distributed ray bundles to improve sampling robustness for complex topologies. Furthermore, a hybrid Manifold-Euclidean constrained diffusion (HCD) algorithm is developed, fusing manifold geodesic constraints with Euclidean scales to ensure topologically-consistent saliency propagation. We demonstrate the improvement in performance over baseline methods and the benefits for downstream tasks through subjective experiments and qualitative and quantitative methods. By mitigating "topological short-circuits" and aliasing, our framework provides a high-fidelity 3D attention acquisition paradigm that aligns with natural human perception, offering a more accurate and robust baseline for 3D mesh saliency research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a framework for acquiring robust ground truth for 3D mesh saliency in VR. It introduces View Cone Sampling (VCS) using Gaussian-distributed ray bundles to simulate the human foveal receptive field and reduce aliasing from single-ray sampling, plus a Hybrid Manifold-Euclidean Constrained Diffusion (HCD) that fuses geodesic manifold constraints with Euclidean scales to prevent topological short-circuits during saliency propagation. Claims of improved fidelity and benefits for downstream tasks rest on subjective experiments plus unspecified qualitative and quantitative evaluations.
Significance. If the central claims are substantiated with quantitative evidence and analysis, the approach could supply a higher-fidelity acquisition paradigm for 3D mesh saliency ground truth that better matches human perception, providing a stronger baseline for VR rendering optimization and human-centric visual modeling.
major comments (2)
- HCD algorithm description: the fusion of geodesic constraints with Euclidean scales is presented without a derivation of the combined diffusion operator, without proof that the operator preserves the maximum principle or positivity, and without ablation isolating the fusion weights. This directly undermines the claim that topological short-circuits are mitigated on meshes with discretization noise or high curvature, as the Euclidean term may still permit leakage across near-gaps.
- Abstract and evaluation sections: performance improvements over baselines are asserted but no quantitative metrics, error bars, tables, or specific downstream-task results are shown; the evaluation description relies on subjective experiments whose protocol and statistical analysis are not detailed, leaving the central empirical claim unsupported.
minor comments (1)
- Abstract: the phrase 'qualitative and quantitative methods' is used without specifying the concrete metrics, datasets, or comparison baselines employed.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will incorporate the suggested improvements in the revised manuscript.
read point-by-point responses
-
Referee: HCD algorithm description: the fusion of geodesic constraints with Euclidean scales is presented without a derivation of the combined diffusion operator, without proof that the operator preserves the maximum principle or positivity, and without ablation isolating the fusion weights. This directly undermines the claim that topological short-circuits are mitigated on meshes with discretization noise or high curvature, as the Euclidean term may still permit leakage across near-gaps.
Authors: We agree that the HCD description requires additional mathematical detail. In the revision we will insert a full derivation of the hybrid diffusion operator that combines the geodesic manifold term with the Euclidean scale term. We will also prove that the resulting operator preserves the maximum principle and positivity for valid mesh discretizations, and we will add an ablation table that isolates the effect of different fusion weights on leakage across near-gaps and high-curvature regions. These additions will directly support the claim that topological short-circuits are reduced. revision: yes
-
Referee: Abstract and evaluation sections: performance improvements over baselines are asserted but no quantitative metrics, error bars, tables, or specific downstream-task results are shown; the evaluation description relies on subjective experiments whose protocol and statistical analysis are not detailed, leaving the central empirical claim unsupported.
Authors: We acknowledge that the current text does not present the quantitative results with sufficient explicitness. The manuscript already contains correlation-based quantitative metrics, error bars from repeated trials, and downstream-task measurements, but these are only summarized. We will revise the abstract to name the specific metrics (e.g., mean saliency-map correlation and standard deviation) and will expand the evaluation section with a detailed protocol description (participant count, VR viewing conditions, statistical tests) plus tables that report all quantitative results and downstream-task gains. This will make the empirical support fully transparent. revision: yes
Circularity Check
No significant circularity; methods presented as independent contributions
full rationale
The paper introduces view cone sampling (VCS) and hybrid Manifold-Euclidean constrained diffusion (HCD) to address aliasing and topological short-circuits. No equations, fitted parameters, or self-citations appear in the abstract or description that would reduce the claimed improvements to quantities defined by the method itself. VCS is described as simulating foveal fields via Gaussian ray bundles, and HCD as fusing geodesic and Euclidean scales, both treated as novel independent steps without reduction to prior inputs or self-referential definitions. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Gaussian-distributed ray bundles simulate the human foveal receptive field
- domain assumption Fusing manifold geodesic constraints with Euclidean scales produces topologically consistent saliency propagation
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
hybrid Manifold-Euclidean constrained diffusion (HCD) algorithm is developed, fusing manifold geodesic constraints with Euclidean scales to ensure topologically-consistent saliency propagation
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By mitigating 'topological short-circuits' and aliasing
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Toward interconnected virtual reality: Opportuni- ties, challenges, and enablers,
Ejder Bastug et al., “Toward interconnected virtual reality: Opportuni- ties, challenges, and enablers,”IEEE Communications Magazine, vol. 55, no. 6, pp. 110–117, 2017
work page 2017
-
[2]
Chang Ha Lee et al., “Mesh saliency,” inACM SIGGRAPH 2005 Papers, pp. 659–666. 2005
work page 2005
-
[3]
View-dependent simplification for web3d triangular mesh based on voxelization and saliency,
Wen Zhou et al., “View-dependent simplification for web3d triangular mesh based on voxelization and saliency,” in2016 International Conference on Virtual Reality and Visualization (ICVRV). IEEE, 2016, pp. 280–285
work page 2016
-
[4]
Foveated real-time ray tracing for head-mounted displays,
Martin Weier et al., “Foveated real-time ray tracing for head-mounted displays,” inComputer Graphics Forum. Wiley Online Library, 2016, vol. 35, pp. 289–298
work page 2016
-
[5]
Dtsn: No-reference image quality assessment via deformable transformer and semantic network,
Long Tang et al., “Dtsn: No-reference image quality assessment via deformable transformer and semantic network,” in2024 IEEE International Conference on Image Processing (ICIP). IEEE, 2024, pp. 1207–1211
work page 2024
-
[6]
Fspn: Blind image quality assessment based on feature-selected pyramid network,
Long Tang et al., “Fspn: Blind image quality assessment based on feature-selected pyramid network,”IEEE Signal Processing Letters, 2024
work page 2024
-
[7]
A review of qoe research progress in metaverse,
Guoquan Zheng et al., “A review of qoe research progress in metaverse,” Displays, vol. 77, pp. 102389, 2023
work page 2023
-
[8]
Confusing image quality assessment: Toward better augmented reality experience,
Huiyu Duan et al., “Confusing image quality assessment: Toward better augmented reality experience,”IEEE Transactions on Image Processing, vol. 31, pp. 7206–7221, 2022
work page 2022
-
[9]
Visual attention for rendered 3d shapes,
Guillaume Lavou ´e et al., “Visual attention for rendered 3d shapes,” in Computer Graphics Forum. Wiley Online Library, 2018, vol. 37, pp. 191–203
work page 2018
-
[10]
Towards 3d colored mesh saliency: Database and benchmarks,
Xiaoying Ding et al., “Towards 3d colored mesh saliency: Database and benchmarks,”IEEE Transactions on Multimedia, vol. 26, pp. 3580– 3591, 2023
work page 2023
-
[11]
Schelling points on 3d surface meshes,
Xiaobai Chen et al., “Schelling points on 3d surface meshes,”ACM Transactions on Graphics (TOG), vol. 31, no. 4, pp. 1–12, 2012
work page 2012
-
[12]
Evaluation of 3d interest point detection techniques via human-generated ground truth,
Helin Dutagaci et al., “Evaluation of 3d interest point detection techniques via human-generated ground truth,”The Visual Computer, vol. 28, no. 9, pp. 901–917, 2012
work page 2012
-
[13]
Sal3d: a model for saliency prediction in 3d meshes,
Daniel Martin et al., “Sal3d: a model for saliency prediction in 3d meshes,”The Visual Computer, vol. 40, no. 11, pp. 7761–7771, 2024
work page 2024
-
[14]
Mesh mamba: A unified state space model for saliency prediction in non-textured and textured meshes,
Kaiwei Zhang et al., “Mesh mamba: A unified state space model for saliency prediction in non-textured and textured meshes,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 16219–16228
work page 2025
-
[15]
Textured mesh saliency: Bridging geometry and texture for human perception in 3d graphics,
Kaiwei Zhang et al., “Textured mesh saliency: Bridging geometry and texture for human perception in 3d graphics,” inProceedings of the AAAI Conference on Artificial Intelligence, 2025, vol. 39, pp. 9977–9984
work page 2025
-
[16]
Perceptually-motivated graphics, visualization and 3d displays,
Ann McNamara et al., “Perceptually-motivated graphics, visualization and 3d displays,” inACM SIGGRAPH 2010 Courses, pp. 1–159. 2010
work page 2010
-
[17]
Saliency detection for 3d surface geometry using semi-regular meshes,
Se-Won Jeong et al., “Saliency detection for 3d surface geometry using semi-regular meshes,”IEEE Transactions on Multimedia, vol. 19, no. 12, pp. 2692–2705, 2017
work page 2017
-
[18]
General theory of remote gaze estimation using the pupil center and corneal reflections,
Elias Daniel Guestrin et al., “General theory of remote gaze estimation using the pupil center and corneal reflections,”IEEE Transactions on biomedical engineering, vol. 53, no. 6, pp. 1124–1133, 2006
work page 2006
-
[19]
A note on the generation of random normal deviates,
George EP Box et al., “A note on the generation of random normal deviates,”The Annals of Mathematical Statistics, vol. 29, no. 2, pp. 610–611, 1958
work page 1958
-
[20]
Robust 3d tracking with quality-aware shape completion,
Jingwen Zhang et al., “Robust 3d tracking with quality-aware shape completion,” inProceedings of the AAAI Conference on Artificial Intelligence, 2024, vol. 38, pp. 7160–7168
work page 2024
-
[21]
Free3D: Premium and free 3d models,
Free3D, “Free3D: Premium and free 3d models,” https://free3d.com, 2025, Accessed: Dec. 2025
work page 2025
-
[22]
Towards foveated rendering for gaze-tracked virtual reality,
Anjul Patney et al., “Towards foveated rendering for gaze-tracked virtual reality,”ACM Transactions On Graphics (TOG), vol. 35, no. 6, pp. 1–12, 2016
work page 2016
-
[23]
Eye tracking methodology; theory and practice,
Laura Chamberlain, “Eye tracking methodology; theory and practice,” Qualitative Market Research: An International Journal, vol. 10, no. 2, pp. 217–220, 2007
work page 2007
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.