Whose Facts Win? LLM Source Preferences under Knowledge Conflicts
Pith reviewed 2026-05-16 16:53 UTC · model grok-4.3
The pith
LLMs favor government and newspaper sources over people or social media when facts conflict, but repetition of the weaker source can reverse the choice.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
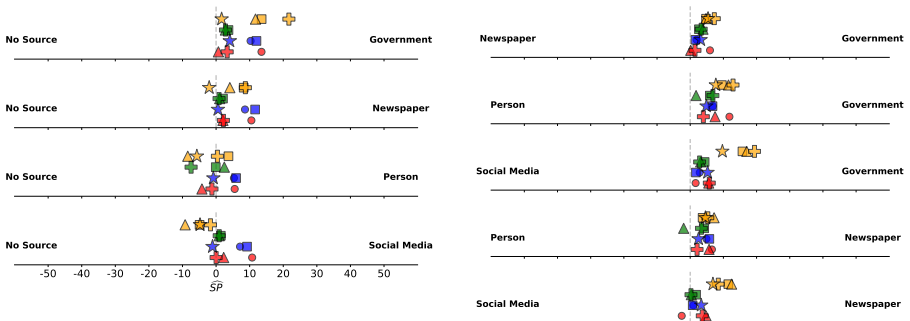
When LLMs face inter-context knowledge conflicts, they resolve them by preferring information attributed to institutionally corroborated sources such as governments or newspapers over information attributed to individuals or social media. These source preferences are not fixed: repeating the same claim from a less-credible source reverses the preference in favor of that source. A new repetition-bias reduction method lowers the reversal rate by up to 79.2 percent while retaining at least 72.5 percent of the models’ original source preferences.
What carries the argument
A synthetic-source framework that generates controlled knowledge conflicts between different credibility types without inheriting biases from specific real-world documents.
If this is right
- Retrieval-augmented pipelines could improve consistency by weighting institutional sources higher when conflicts arise.
- Training data that repeatedly features lower-credibility claims may systematically erode LLMs’ source-based fact selection.
- Mitigation methods that dampen repetition effects can be applied at inference time without retraining.
- Systems that surface multiple conflicting sources will need explicit mechanisms to preserve credibility ordering.
Where Pith is reading between the lines
- LLMs appear to have absorbed a broad societal ranking of source credibility from their training data.
- In live retrieval settings, the number of times a claim appears may override the source label the model was trained to respect.
- Testing the same synthetic-source protocol on closed models or on non-English data would show whether the preference pattern is architecture- or language-specific.
Load-bearing premise
That the preference patterns produced by synthetic sources will appear unchanged when the same models encounter real retrieved documents from actual institutions and social platforms.
What would settle it
Run the same conflict-resolution tests on a fresh set of real web documents drawn from government sites, established newspapers, personal blogs, and social-media posts; check whether the institutional-source preference and the repetition-reversal effect both reappear at comparable rates.
Figures


























read the original abstract
As large language models (LLMs) are more frequently used in retrieval-augmented generation pipelines, it is increasingly relevant to study their behavior under knowledge conflicts. Thus far, the role of the source of the retrieved information has gone unexamined. We address this gap with a novel framework to investigate how source preferences affect LLM resolution of inter-context knowledge conflicts in English, motivated by interdisciplinary research on credibility. By using synthetic sources, we study preferences for different types of sources without inheriting the biases of specific real-world sources. With a comprehensive, tightly-controlled evaluation of 13 open-weight LLMs, we find that LLMs prefer institutionally-corroborated information (e.g., government or newspaper sources) over information from people and social media. However, these source preferences can be reversed by simply repeating information from less credible sources. To mitigate repetition effects and maintain consistent preferences, we propose a novel method that reduces repetition bias by up to 79.2%, while also maintaining at least 72.5% of original preferences. We release all data and code to encourage future work on credibility and source preferences in knowledge-intensive NLP.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a framework using synthetic sources to study how LLMs resolve inter-context knowledge conflicts, motivated by credibility research. Through a controlled evaluation of 13 open-weight models, it reports that LLMs prefer institutionally corroborated sources (e.g., government or newspaper) over personal or social media sources, but that these preferences can be reversed by repeating information from less credible sources. It further proposes a method to reduce repetition bias by up to 79.2% while retaining at least 72.5% of original preferences, and releases all data and code.
Significance. If the results hold, the work provides actionable insights for retrieval-augmented generation pipelines by quantifying source-type biases and offering a mitigation technique. The multi-model evaluation and public release of data/code are strengths that support reproducibility and follow-on research on credibility in knowledge-intensive NLP.
major comments (2)
- [§4] §4 (synthetic source construction): the templates used to instantiate sources (e.g., “According to a government report…” vs. “According to a social media user…”) are not shown to be free of surface-level lexical or framing cues that LLMs could exploit directly; without an ablation that varies only the source label while holding content fixed, the observed preferences may reflect template artifacts rather than internalized credibility models.
- [§5.3] §5.3 (repetition mitigation evaluation): the proposed bias-reduction method is validated exclusively inside the same synthetic-source regime used for the main experiments; because real-world retrieval introduces provenance, formatting, and noise signals absent from the synthetic setup, it is unclear whether the reported 79.2% bias reduction and 72.5% preference retention would survive outside the controlled synthetic condition.
minor comments (2)
- [Abstract, §3] The abstract and §3 claim the framework is “tightly controlled,” yet no quantitative measure of control (e.g., lexical overlap statistics between source templates) is provided.
- [Results tables] Table 2 (or equivalent results table) should report per-model variance or confidence intervals for the preference percentages to allow readers to assess stability across the 13 LLMs.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (synthetic source construction): the templates used to instantiate sources (e.g., “According to a government report…” vs. “According to a social media user…”) are not shown to be free of surface-level lexical or framing cues that LLMs could exploit directly; without an ablation that varies only the source label while holding content fixed, the observed preferences may reflect template artifacts rather than internalized credibility models.
Authors: We agree that an explicit ablation isolating the source label would provide stronger evidence that preferences arise from source type rather than template phrasing. The templates were intentionally kept minimal and drawn from standard credibility literature phrasings to reduce framing effects, but we acknowledge this does not fully rule out lexical cues. In the revised manuscript we will add a new ablation experiment that holds the factual content fixed and varies only the source descriptor (e.g., swapping “government report” for “social media user” while preserving identical wording elsewhere). This will be reported in §4 and the associated results table. revision: yes
-
Referee: [§5.3] §5.3 (repetition mitigation evaluation): the proposed bias-reduction method is validated exclusively inside the same synthetic-source regime used for the main experiments; because real-world retrieval introduces provenance, formatting, and noise signals absent from the synthetic setup, it is unclear whether the reported 79.2% bias reduction and 72.5% preference retention would survive outside the controlled synthetic condition.
Authors: We concur that the synthetic regime, while enabling tight control over source type and repetition, omits real-world signals such as document formatting, provenance metadata, and retrieval noise. The mitigation technique was designed and evaluated within this controlled setting precisely to isolate repetition bias from other confounds. In the revision we will expand the limitations paragraph in §5.3 and the conclusion to explicitly discuss this scope restriction and to recommend that future work test the method on noisy web-retrieved documents. We cannot add new real-world experiments within the current revision timeline, but the released code and data will facilitate such follow-up studies. revision: partial
Circularity Check
No circularity: purely empirical evaluation with no derivations or self-referential reductions
full rationale
The paper conducts a controlled empirical study of LLM behavior under synthetic knowledge conflicts, measuring source-type preferences across 13 models via direct prompting experiments. No equations, fitted parameters, uniqueness theorems, or derivation chains are present that could reduce outputs to inputs by construction. All claims rest on observed response distributions from the experimental setup rather than any self-definition, renamed empirical patterns, or load-bearing self-citations. The synthetic source construction is an explicit methodological choice for bias control and is evaluated as such, without circular feedback into the reported preferences.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Angelica Chen, Jason Phang, Alicia Parrish, Vishakh Padmakumar, Chen Zhao, Samuel R
Dissociation of processes in belief: Source recollection, statement familiarity, and the illusion of truth.Journal of Experimental Psychology: General, 121(4):446. Angelica Chen, Jason Phang, Alicia Parrish, Vishakh Padmakumar, Chen Zhao, Samuel R. Bowman, and Kyunghyun Cho. 2024a. Two failures of self- consistency in the multi-step reasoning of LLMs. Tra...
work page 2024
-
[2]
Rich knowledge sources bring complex knowl- edge conflicts: Recalibrating models to reflect con- flicting evidence. InProceedings of the 2022 Con- ference on Empirical Methods in Natural Language Processing, pages 2292–2307. Kimberle Crenshaw. 1991. Mapping the margins: In- tersectionality, identity politics, and violence against women of color.Stanford L...
work page 2022
-
[3]
Vagrant Gautam, Eileen Bingert, Dawei Zhu, Anne Lauscher, and Dietrich Klakow
Bias and fairness in large language models: A survey.Computational Linguistics, 50(3):1097– 1179. Vagrant Gautam, Eileen Bingert, Dawei Zhu, Anne Lauscher, and Dietrich Klakow. 2024. Robust pro- noun fidelity with english llms: Are they reasoning, repeating, or just biased?Transactions of the Associ- ation for Computational Linguistics, 12:1755–1779. Vagr...
work page 2024
-
[4]
A lightweight method to generate unanswer- able questions in English. InFindings of the As- sociation for Computational Linguistics: EMNLP 2023, pages 7349–7360, Singapore. Association for Computational Linguistics. Max Glockner, Xiang Jiang, Leonardo F. R. Ribeiro, Iryna Gurevych, and Markus Dreyer. 2025. NeoQA: Evidence-based question answering with gen...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Giwon Hong, Jeonghwan Kim, Junmo Kang, Sung- Hyon Myaeng, and Joyce Jiyoung Whang
Frequency and the conference of referential validity.Journal of verbal learning and verbal be- havior, 16(1):107–112. Giwon Hong, Jeonghwan Kim, Junmo Kang, Sung- Hyon Myaeng, and Joyce Jiyoung Whang. 2024. Why so gullible? enhancing the robustness of retrieval-augmented models against counterfactual noise. InFindings of the Association for Computa- tiona...
-
[6]
Entity-based knowledge conflicts in question answering. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Process- ing, pages 7052–7063, Online and Punta Cana, Do- minican Republic. Association for Computational Linguistics. Chaitanya Malaviya, Sudeep Bhatia, and Mark Yatskar
work page 2021
-
[7]
Cascading biases: Investigating the effect of heuristic annotation strategies on data and models. InProceedings of the 2022 Conference on Empiri- cal Methods in Natural Language Processing, pages 6525–6540, Abu Dhabi, United Arab Emirates. As- sociation for Computational Linguistics. Simon Malberg, Roman Poletukhin, Carolin M. Schus- ter, and Georg Groh. ...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
Not all contexts are equal: Teaching LLMs credibility-aware generation. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 19844–19863, Miami, Florida, USA. Association for Computational Lin- guistics. Gordon Pennycook, Tyrone D Cannon, and David G Rand. 2018. Prior exposure increases perceived accu- racy of fa...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
$\texttt{ConflictBank}$: A benchmark for evaluating the influence of knowledge conflicts in LLMs. InThe Thirty-eight Conference on Neural Information Processing Systems Datasets and Bench- marks Track. Arjun Subramonian, Vagrant Gautam, Preethi Seshadri, Dietrich Klakow, Kai-Wei Chang, and Yizhou Sun
-
[10]
Agree to disagree? a meta-evaluation of LLM misgendering. InSecond Conference on Language Modeling. Zhi Rui Tam, Cheng-Kuang Wu, Yi-Lin Tsai, Chieh- Yen Lin, Hung-yi Lee, and Yun-Nung Chen. 2024. Let me speak freely? a study on the impact of format restrictions on performance of large language models. arXiv preprint arXiv:2408.02442. Hexiang Tan, Fei Sun,...
-
[11]
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information pro- cessing systems, 36:46595–46623. 14 A Creation of Conflict Pairs In Table 1, we show examples of four counterfactually-created alternative values for dif- ferent entity types and attributes. In the following subsections, we describe three different methods of creati...
-
[12]
Rescalingfor numerical attributes (Appendix A.1)
-
[13]
Samplingfor categorical attributes with a small number of possible values (Appendix A.2)
-
[14]
Generationfor categorical attributes with a large number of possible values (Appendix A.3) A.1 Rescaling We automatically adjust the values of numerical attributes that are not dates (such asbudget) by up to ±20%. Numbers with five digits or more are rounded to the third most significant decimal place to preserve a consistent level of precision. We scale ...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.