Tracing Moral Foundations in Large Language Models
Pith reviewed 2026-05-21 16:22 UTC · model grok-4.3
The pith
Large language models encode moral foundations internally in ways that align with human judgments, emerging from pretraining and modifiable by post-training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
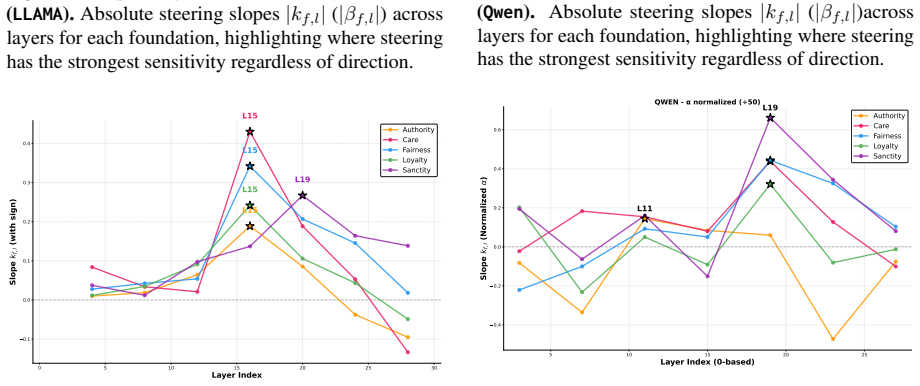
Models represent and distinguish moral foundations in a manner that aligns with human judgments, and that this moral geometry naturally emerges from pretraining and is selectively rewired by post-training. SAE features show clear semantic links to specific foundations, and steering along dense vectors or sparse features produces predictable shifts in foundation-relevant behavior.
What carries the argument
Sparse autoencoder features over the residual stream and dense MFT vectors used for layer-wise analysis and causal steering interventions.
If this is right
- Moral concepts are distributed and layered but show measurable alignment with human perceptual structure.
- Basic moral geometry arises from statistical regularities in language data during pretraining without explicit supervision.
- Post-training selectively rewires portions of this geometry while preserving others.
- Sparse features provide partially disentangled handles on individual moral foundations within shared representations.
- Causal interventions on these features or vectors produce consistent, predictable shifts in model behavior on moral tasks.
Where Pith is reading between the lines
- Targeted steering of these features could support more precise control over value-laden outputs in deployed systems.
- Similar techniques might reveal how other abstract value systems, such as political or fairness concepts, organize in the same models.
- The pretraining origin suggests moral-like structures could appear in any sufficiently large language model trained on broad text corpora.
Load-bearing premise
The Moral Foundations Theory categories and the specific prompts used to elicit moral judgments provide a faithful and unbiased probe of the models' internal conceptual structure rather than reflecting surface-level pattern matching to the input format.
What would settle it
Observing no predictable change in foundation-relevant outputs when applying the identified steering vectors or SAE features on new scenarios, or finding that the alignment with human moral judgments disappears under different prompt wordings.
Figures










read the original abstract
Large language models often produce human-like moral judgments, but it is unclear whether this reflects an internal conceptual structure or superficial ``moral mimicry.'' Using Moral Foundations Theory (MFT) as an analytic framework, we study how moral foundations are encoded, organized, and expressed across 14 base and instruction-tuned LLMs spanning four model families (Llama, Qwen2.5, Qwen3-MoE, Mistral) and scales from 7B to 70B. We employ a multi-level approach combining (i) layer-wise analysis of MFT concept representations and their alignment with human moral perceptions, (ii) pretrained sparse autoencoders (SAEs) over the residual stream to identify sparse features that support moral concepts, and (iii) causal steering interventions using dense MFT vectors and sparse SAE features. We find that models represent and distinguish moral foundations in a manner that aligns with human judgments, and that this moral geometry naturally emerges from pretraining and is selectively rewired by post-training. At a finer scale, SAE features show clear semantic links to specific foundations, suggesting partially disentangled mechanisms within shared representations. Finally, steering along either dense vectors or sparse features produces predictable shifts in foundation-relevant behavior, demonstrating a causal connection between internal representations and moral outputs. Together, our results provide mechanistic evidence that moral concepts in LLMs are distributed, layered, and partly disentangled, suggesting that pluralistic moral structure can emerge as a latent pattern from the statistical regularities of language alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that moral foundations from Moral Foundations Theory are represented and distinguished in LLMs in alignment with human judgments. This moral geometry emerges naturally from pretraining, is selectively rewired by post-training, and is supported by sparse SAE features with semantic links to specific foundations. Causal steering via dense MFT vectors or sparse features produces predictable shifts in foundation-relevant behavior, providing mechanistic evidence that moral concepts in LLMs are distributed, layered, and partly disentangled.
Significance. If the results hold under scrutiny, the work offers mechanistic interpretability evidence that pluralistic moral structures can arise as latent patterns from language statistics alone. The combination of representation analysis, SAE feature discovery, and causal interventions strengthens claims about internal conceptual organization and suggests avenues for targeted control of moral outputs in AI systems.
major comments (1)
- Methods section describing prompt design and MFT elicitation: All three core methods (layer-wise representation analysis, SAE feature extraction, and steering interventions) rely on MFT-derived categories and prompts. To substantiate the claim that the observed moral geometry reflects pre-existing internal structure rather than prompt-induced surface matching, the paper must report controls such as scrambled prompts, neutral templates, or non-MFT moral scenarios. This is load-bearing for the central assertion that the geometry 'naturally emerges from pretraining.'
minor comments (2)
- Abstract: Specify the exact split between base and instruction-tuned models among the 14 LLMs to better support claims about pretraining versus post-training effects.
- Results on SAE features: Provide quantitative metrics (e.g., activation correlations or inter-rater agreement on semantic interpretations) rather than relying solely on qualitative semantic links to foundations.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. The concern about distinguishing pre-existing internal structure from prompt artifacts is a substantive one that directly bears on our central claims. We address it point by point below and commit to revisions that strengthen the manuscript.
read point-by-point responses
-
Referee: Methods section describing prompt design and MFT elicitation: All three core methods (layer-wise representation analysis, SAE feature extraction, and steering interventions) rely on MFT-derived categories and prompts. To substantiate the claim that the observed moral geometry reflects pre-existing internal structure rather than prompt-induced surface matching, the paper must report controls such as scrambled prompts, neutral templates, or non-MFT moral scenarios. This is load-bearing for the central assertion that the geometry 'naturally emerges from pretraining.'
Authors: We agree that explicit controls are required to rule out surface-level prompt matching and thereby support the claim of natural emergence from pretraining. In the revised manuscript we will add a new control subsection to the Methods. We will report three sets of experiments: (i) scrambled prompts in which moral-foundation labels are randomly reassigned while preserving lexical content, (ii) neutral templates that omit all MFT-specific wording, and (iii) prompts drawn from non-MFT ethical scenarios. For each core method we will quantify the drop in alignment, feature activation, and steering efficacy under these controls relative to the original MFT prompts. We will also include base-model-only results to further isolate pretraining effects. These additions will be integrated into the layer-wise, SAE, and intervention analyses and will be accompanied by statistical tests. revision: yes
Circularity Check
No significant circularity: claims rest on external human benchmarks and causal interventions
full rationale
The paper's central derivation uses MFT as an external analytic framework to probe representations via layer-wise analysis, SAE feature extraction, and steering interventions. Alignment is measured against independent human moral perception data, and causal effects are tested through interventions on identified vectors/features. None of these steps define moral vectors in terms of the target alignment metric or rename fitted quantities as predictions. No self-citation chains, uniqueness theorems, or ansatzes from prior author work are invoked as load-bearing. The analysis is self-contained against external benchmarks and does not reduce its outputs to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Moral Foundations Theory categories are psychologically valid and can be used as an analytic framework for machine representations
Forward citations
Cited by 1 Pith paper
-
Psychological Steering of Large Language Models
Mean-difference residual stream injections outperform personality prompting for OCEAN trait steering in most LLMs, with hybrids performing best and showing approximate linearity but non-human trait covariances.
Reference graph
Works this paper leans on
-
[1]
Moral foundations of large language models. InProceedings of the 2024 Conference on Empiri- cal Methods in Natural Language Processing, pages 17737–17752. Suhaib Abdurahman, Mohammad Atari, Farzan Karimi- Malekabadi, Mona J Xue, Jackson Trager, Peter S Park, Preni Golazizian, Ali Omrani, and Morteza De- hghani. 2024. Perils and opportunities in using larg...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Psychological steering in llms: An evalua- tion of effectiveness and trustworthiness.Preprint, arXiv:2510.04484. Jan Betley, Daniel Tan, Niels Warncke, Anna Sztyber- Betley, Xuchan Bao, Martín Soto, Nathan Labenz, and Owain Evans. 2025. Emergent misalignment: Narrow finetuning can produce broadly misaligned llms.Preprint, arXiv:2502.17424. Joseph Bloom, C...
-
[3]
Moral foundations theory: The pragmatic va- lidity of moral pluralism. InAdvances in experi- mental social psychology, volume 47, pages 55–130. Elsevier. Jesse Graham, Brian A Nosek, Jonathan Haidt, Ravi Iyer, Spassena Koleva, and Peter H Ditto. 2011. Map- ping the moral domain.Journal of personality and social psychology, 101(2):366. Aaron Grattafiori, A...
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[4]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language under- standing.arXiv preprint arXiv:2009.03300. Joseph Henrich, Steven J Heine, and Ara Norenzayan
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[5]
The weirdest people in the world?Behavioral and brain sciences, 33(2-3):61–83. Joe Hoover, Mohammad Atari, Aida Mostafazadeh Da- vani, Brendan Kennedy, Gwenyth Portillo-Wightman, Leigh Yeh, and Morteza Dehghani. 2021. Investi- gating the role of group-based morality in extreme behavioral expressions of prejudice.Nature Commu- nications, 12(1):4585. Joe Ho...
work page 2021
-
[6]
Jianchao Ji, Yutong Chen, Mingyu Jin, Wujiang Xu, Wenyue Hua, and Yongfeng Zhang
Moral foundations elicit shared and dissocia- ble cortical activation modulated by political ideol- ogy.Nature Human Behaviour, 7(12):2182–2198. Jianchao Ji, Yutong Chen, Mingyu Jin, Wujiang Xu, Wenyue Hua, and Yongfeng Zhang. 2025. Moral- bench: Moral evaluation of llms.ACM SIGKDD Explorations Newsletter, 27(1):62–71. Behnam Karami, Fatemeh Zandi, and Ja...
work page 2025
-
[7]
Emergent moral representations in large lan- guage models aligns with human conceptual, neural, and behavioral moral structure.Research Square Preprint. Adam Karvonen. 2024. An intuitive explanation of sparse autoencoders for llm interpretability. Brendan Kennedy, Mohammad Atari, Aida Mostafazadeh Davani, Joe Hoover, Ali Omrani, Jesse Graham, and Morteza Dehghani
work page 2024
-
[8]
Moral concerns are differentially observable in language.Cognition, 212:104696. Ari Khoudary, Eleanor Hanna, Kevin O’Neill, Vi- jeth Iyengar, Scott Clifford, Roberto Cabeza, Felipe De Brigard, and Walter Sinnott-Armstrong. 2022. A functional neuroimaging investigation of moral foun- dations theory.Social Neuroscience, 17(6):491–507. Been Kim, Martin Watte...
work page 2022
-
[9]
Dictionary learning. GitHub repository. https://github.com/saprmarks/dictionary_ learning. Meta. 2024. meta-llama/llama-3.1-8b-instruct. https://huggingface.co/meta-llama/Llama-3. 1-8B-Instruct. Hugging Face model. Accessed: 2025-12-31. 11 Richard Ngo, Lawrence Chan, and Sören Mindermann
work page 2024
-
[10]
The alignment problem from a deep learning perspective. InThe Twelfth International Conference on Learning Representations. José Luiz Nunes, Guilherme F. C. F. Almeida, Marcelo de Araujo, and Simone D. J. Barbosa. 2024. Are large language models moral hypocrites? a study based on moral foundations.arXiv preprint arXiv:2409.01955. Dino Pedreschi, Fosca Gia...
-
[11]
Neutral Description First:Describe the dom- inant pattern (topic, style, rhetorical function, or social behavior) neutrally
-
[12]
Otherwise, output mft_alignment="none"
Conservative MFT Mapping:Map to a Moral Foundations Theory categoryonly if strongly supported. Otherwise, output mft_alignment="none". Do not force moral- ity; many features are not moral
-
[13]
Format:Provide a short label (5–10 words) and a 1–2 sentence description
-
[14]
Citations:Cite evidence_ids (indices of snippets) that justify your decision. Moral Foundations Theory (MFT) definitions: • Care/harm:dislike others’ suffering; kind- ness, gentleness, nurturance vs cruelty, vio- lence. • Fairness/cheating:justice, rights, autonomy vs fraud, exploitation, cheating. • Loyalty/betrayal:group allegiance, patrio- tism, self-s...
work page 2020
-
[15]
Form:Each item must be a single sentence (≤25 words), plain language, observational tone
-
[16]
Content Constraints:Emotional harm only; no physical harm, threats, authority roles, or in-group/out-group dynamics
-
[17]
Social Context:Use strangers or minimal rela- tionships; avoid family, close friends, or hierar- chical roles
- [18]
-
[19]
Child labor has no place in the production of
Subjects:Use generic actors (man, woman, boy, girl, person, teen); avoid names and pro- tected attributes as targets. Diversity Requirement (Coverage Grid):Gener- ate exactly120 itemsorganized as10 themes × 12 items, covering distinct everyday contexts (e.g., public transit, workplaces without hierarchy, online spaces, social mixers). Output Format:Return...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.