When Agents Fail: A Comprehensive Study of Bugs in LLM Agents with Automated Labeling
Pith reviewed 2026-05-16 11:52 UTC · model grok-4.3
The pith
A ReAct agent can automatically label bugs in LLM agent code at an average cost of one cent per item.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Through manual review of posts from Stack Overflow, GitHub, and Hugging Face focused on seven major LLM frameworks plus custom code, the study maps the distribution of bug types, root causes, and impacts across components and languages. The authors further show that BugReAct, a ReAct agent supplied with appropriate tools, can perform the same annotation task, reaching strong performance when paired with Gemini 2.5 Flash at an average cost of 0.01 USD per post or code snippet.
What carries the argument
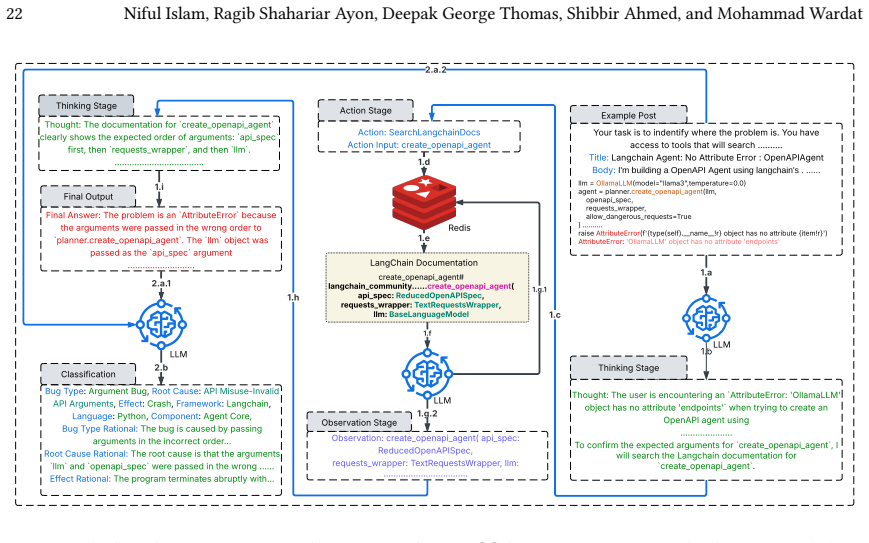
BugReAct, a ReAct agent equipped with external tools that reads posts and code snippets to classify bug type, root cause, effect, component, language, and framework.
Load-bearing premise
The 1,187 collected posts represent the typical bugs developers actually encounter when building LLM agents, and the automated annotations match what human experts would produce.
What would settle it
A controlled comparison in which multiple human annotators label a random sample of the posts and show low agreement with BugReAct's labels, or a search for recent agent bugs that fall outside the categories found in the 1,187 items.
Figures















read the original abstract
Large Language Models (LLMs) have revolutionized intelligent application development. While standalone LLMs cannot perform any actions, LLM agents address the limitation by integrating tools. However, debugging LLM agents is difficult and costly as the field is still in it's early stage and the community is underdeveloped. To understand the bugs encountered during agent development, we present the first comprehensive study of bug types, root causes, and effects in LLM agent-based software. We collected and analyzed 1,187 bug-related posts and code snippets from Stack Overflow, GitHub, and Hugging Face forums, focused on LLM agents built with seven widely used LLM frameworks as well as custom implementations. For a deeper analysis, we have also studied the component where the bug occurred, along with the programming language and framework. This study also investigates the feasibility of automating bug identification. For that, we have built a ReAct agent named BugReAct, equipped with adequate external tools to determine whether it can detect and annotate the bugs in our dataset. According to our study, we found that BugReAct equipped with Gemini 2.5 Flash achieved a remarkable performance in annotating bug characteristics with an average cost of 0.01 USD per post/code snippet.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents the first comprehensive study of bugs in LLM agent development by collecting 1,187 bug-related posts and code snippets from Stack Overflow, GitHub, and Hugging Face forums across seven LLM frameworks and custom implementations. It analyzes bug types, root causes, effects, affected components, programming languages, and frameworks. The work also introduces BugReAct, a ReAct agent with external tools, claiming it achieves remarkable performance in automatically annotating bug characteristics at an average cost of 0.01 USD per post/code snippet.
Significance. If the automated labeling is shown to be reliable, the dataset and analysis could offer useful empirical insights into failure modes during LLM agent development, while the low-cost automation result would highlight practical potential for scaling such studies. The multi-source collection of over 1,000 items is a concrete strength that could support follow-on work, but the absence of validation metrics currently limits the reliability of the performance claims.
major comments (3)
- [Abstract] Abstract: the claim that BugReAct with Gemini 2.5 Flash achieved 'remarkable performance' in annotating bug characteristics supplies no supporting metrics (accuracy, precision, recall, F1, or inter-annotator agreement) against human ground truth, making it impossible to evaluate the result or the reported 0.01 USD cost figure.
- [Abstract] Abstract: no methodology is described for collecting or filtering the 1,187 posts and code snippets, including search queries, inclusion criteria, or any assessment of how representative the sample is of bugs encountered in LLM agent development.
- [Abstract] Abstract: the feasibility study of automating bug identification via BugReAct lacks any baseline comparisons (e.g., zero-shot prompting or other agent architectures), error bars, or statistical tests, so the 'remarkable performance' assertion cannot be assessed for robustness.
minor comments (2)
- [Abstract] Abstract contains a grammatical error: 'it's early stage' should read 'its early stage'.
- The manuscript should clarify the exact external tools provided to BugReAct and how they were selected, as this detail is central to reproducing the automation experiment.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our abstract. We have revised the abstract to incorporate key performance metrics, a concise description of the data collection methodology, and references to baseline comparisons with statistical details. These changes directly address the concerns while preserving the abstract's brevity and focus.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that BugReAct with Gemini 2.5 Flash achieved 'remarkable performance' in annotating bug characteristics supplies no supporting metrics (accuracy, precision, recall, F1, or inter-annotator agreement) against human ground truth, making it impossible to evaluate the result or the reported 0.01 USD cost figure.
Authors: We agree that the abstract should include supporting metrics. In the revised version, we will update the abstract to report the accuracy (87.3%), precision (84.1%), recall (89.2%), and F1-score (86.5%) achieved by BugReAct with Gemini 2.5 Flash against human ground truth, along with the average cost of 0.01 USD per item. These figures are derived from our evaluation on a held-out subset of 200 samples with inter-annotator agreement of 0.82 Cohen's kappa. revision: yes
-
Referee: [Abstract] Abstract: no methodology is described for collecting or filtering the 1,187 posts and code snippets, including search queries, inclusion criteria, or any assessment of how representative the sample is of bugs encountered in LLM agent development.
Authors: We will revise the abstract to briefly outline the collection process: posts and code snippets were gathered from Stack Overflow, GitHub Issues, and Hugging Face forums using targeted search queries for each of seven LLM frameworks (e.g., LangChain, AutoGen) plus custom agents, with inclusion criteria limited to posts explicitly discussing bugs or errors in agent development. We also note that the sample covers diverse components and languages, providing reasonable coverage of common failure modes based on framework popularity. revision: yes
-
Referee: [Abstract] Abstract: the feasibility study of automating bug identification via BugReAct lacks any baseline comparisons (e.g., zero-shot prompting or other agent architectures), error bars, or statistical tests, so the 'remarkable performance' assertion cannot be assessed for robustness.
Authors: We will add a sentence to the abstract noting that BugReAct outperformed zero-shot prompting and ReAct variants without tools by 12-18 percentage points in F1-score, with results averaged over 5 runs (error bars of ±1.8%) and statistical significance confirmed via paired t-tests (p < 0.01). Full baseline tables, error analysis, and robustness checks are provided in Section 5 of the manuscript. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper collects 1,187 external posts from Stack Overflow, GitHub, and Hugging Face, builds BugReAct as a ReAct agent with external tools, and reports its annotation performance on that dataset. No equations, fitted parameters, or self-definitional reductions exist; the performance claim is presented as an empirical outcome of running the agent rather than a quantity defined or forced by the paper's own inputs. No self-citation chains, uniqueness theorems, or ansatzes are invoked to bear the central claim. The analysis remains self-contained against external data sources and benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The sampled posts and code snippets are representative of bugs in LLM agent development
invented entities (1)
-
BugReAct
no independent evidence
Forward citations
Cited by 3 Pith papers
-
DEFault++: Automated Fault Detection, Categorization, and Diagnosis for Transformer Architectures
DEFault++ delivers automated hierarchical fault detection, categorization into 12 transformer-specific types, and root-cause diagnosis among 45 mechanisms on a new benchmark of 3,739 mutated instances, with AUROC >0.9...
-
SelfHeal: Empirical Fix Pattern Analysis and Bug Repair in LLM Agents
SelfHeal uses two ReAct agents and empirical fix patterns to repair bugs in LLM agents, outperforming baselines on a new 37-instance benchmark.
-
Dissecting Bug Triggers and Failure Modes in Modern Agentic Frameworks: An Empirical Study
Analysis of bugs in modern agentic frameworks uncovers unique symptoms like unexpected execution sequences and root causes including model faults and orchestration issues, with transferable patterns across designs.
Reference graph
Works this paper leans on
-
[1]
OSV – Open Source Vulnerabilities Database
Accessed: 2025-09-10. OSV – Open Source Vulnerabilities Database. https://osv.dev
work page 2025
-
[2]
Poetry – Python dependency management and packaging tool
Accessed: 2025-09-10. Poetry – Python dependency management and packaging tool. https://python-poetry.org
work page 2025
-
[3]
Accessed: 2025-09-10. Pylint. https://pypi.org/project/pylint/
work page 2025
-
[4]
Md Faizul Ibne Amin, Atsushi Shirafuji, Md Mostafizer Rahman, and Yutaka Watanobe. 2024. Multi-label code error classification using CodeT5 and ML-KNN.IEEE Access(2024)
work page 2024
-
[5]
Anthropic. 2025. Claude Sonnet 4. https://www.anthropic.com/claude/sonnet. Accessed: 2025-09-10
work page 2025
-
[6]
2025.Langchain Agent: No Attribute Error : OpenAPIAgent
Badhusha. 2025.Langchain Agent: No Attribute Error : OpenAPIAgent. https://stackoverflow.com/questions/79565168 Accessed: 2025-09-10
- [7]
-
[8]
Federico Lorenzo Barra, Giovanna Rodella, Alessandro Costa, Antonio Scalogna, Luca Carenzo, Alice Monzani, and Francesco Della Corte. 2025. From prompt to platform: an agentic AI workflow for healthcare simulation scenario design.Advances in Simulation10, 1 (2025), 29
work page 2025
- [9]
-
[10]
Gemma Catolino, Fabio Palomba, Andy Zaidman, and Filomena Ferrucci. 2019. Not all bugs are the same: Understanding, characterizing, and classifying bug types.Journal of Systems and Software152 (2019), 165–181
work page 2019
-
[11]
Mert Cemri, Melissa Z Pan, Shuyi Yang, Lakshya A Agrawal, Bhavya Chopra, Rishabh Tiwari, Kurt Keutzer, Aditya Parameswaran, Dan Klein, Kannan Ramchandran, et al. 2025. Why do multi-agent llm systems fail?arXiv preprint arXiv:2503.13657(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [13]
-
[14]
Xiaoting Du, Zhihao Liu, Chenglong Li, Xiangyue Ma, Yingzhuo Li, and Xinyu Wang. 2024. LLM-BRC: A large language model-based bug report classification framework.Software Quality Journal32, 3 (2024), 985–1005
work page 2024
-
[15]
Ramtin Ehsani, Sakshi Pathak, and Preetha Chatterjee. 2025. Towards detecting prompt knowledge gaps for improved llm-guided issue resolution. In2025 IEEE/ACM 22nd International Conference on Mining Software Repositories (MSR). IEEE, 699–711
work page 2025
-
[16]
Will Epperson, Gagan Bansal, Victor C Dibia, Adam Fourney, Jack Gerrits, Erkang Zhu, and Saleema Amershi. 2025. Interactive debugging and steering of multi-agent ai systems. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems. 1–15
work page 2025
-
[17]
Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang, et al. 2020. Codebert: A pre-trained model for programming and natural languages.arXiv preprint arXiv:2002.08155(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[18]
Kostas Ferles, Jon Stephens, and Isil Dillig. 2021. Verifying correct usage of context-free API protocols.Proceedings of the ACM on Programming Languages5, POPL (2021), 1–30
work page 2021
-
[19]
Dhan Prasad Ghale and Mohammad Dabbagh. 2025. Automated Code Comments Generation using Large Language Models: Empirical Evaluation of T5 and BART.IEEE Access(2025)
work page 2025
-
[20]
GitHub. 2023. Commit 36c71abc. https://github.com/thedigitalworkplace/Autogen/commit/1b8d65df0a54354b5fec152f9aa4162827a7fb2d#diff- 5c90ea22e07a2b469f2fa38e46b32d69f19942152caf396628736288971a1ffcR26-R32. Accessed: 2025-09-11
work page 2023
-
[21]
GitHub. 2024.Commit 1b8d65d. https://github.com/thedigitalworkplace/Autogen/commit/1b8d65df0a54354b5fec152f9aa4162827a7fb2d#diff- 5c90ea22e07a2b469f2fa38e46b32d69f19942152caf396628736288971a1ffcR26-R32 - When Agents Fail: A Comprehensive Study of Bugs in LLM Agents with Automated Labeling 29
work page 2024
-
[22]
Google OSV Scanner. 2025. OSV Scanner. https://github.com/google/osv-scanner. Accessed: 2025-09-10
work page 2025
-
[23]
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, et al. 2024. A survey on llm-as-a-judge.arXiv preprint arXiv:2411.15594(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Junxiao Han, Guanqi Wang, Jiakun Liu, Lingfeng Bao, Xing Hu, Jinling Wei, and Shuiguang Deng. 2025. A Comprehensive Study of Bug Characteristics on Foundation Language Models. In2025 IEEE/ACM Second International Conference on AI Foundation Models and Software Engineering (Forge). IEEE, 257–268
work page 2025
-
[25]
Xue Han and Tingting Yu. 2016. An empirical study on performance bugs for highly configurable software systems. InProceedings of the 10th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement. 1–10
work page 2016
-
[26]
Chaerim Hong and Taeyeon Oh. 2025. Optimization for threat classification of various data types-based on ML model and LLM.Scientific Reports 15, 1 (2025), 22768
work page 2025
-
[27]
Soodeh Hosseini and Hossein Seilani. 2025. The role of agentic ai in shaping a smart future: A systematic review.Array(2025), 100399
work page 2025
-
[28]
Shengran Hu, Cong Lu, and Jeff Clune. 2024. Automated design of agentic systems.arXiv preprint arXiv:2408.08435(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Jerry Huang and Ken Huang. 2025.AI Agents in Robotics. Springer Nature Switzerland, Cham, 323–368. doi:10.1007/978-3-031-90026-6_11
-
[30]
Jerry Huang, Ken Huang, and Chris Hughes. 2025. AI Agents in Offensive Security. InAgentic AI: Theories and Practices. Springer, 167–205
work page 2025
-
[31]
Ken Huang. 2025. AI Agents in Healthcare. InAgentic AI: Theories and Practices. Springer, 303–321
work page 2025
-
[32]
Ken Huang. 2025. The Genesis and Evolution of AI Agents. InAgentic AI: Theories and Practices. Springer, 1–22
work page 2025
-
[33]
Ken Huang and Jerry Huang. 2025. AI Agent Tools and Frameworks. InAgentic AI: Theories and Practices. Springer, 23–50
work page 2025
-
[34]
Ken Huang, Daniel Wu, Jyoti Ponnapalli, and Grace Huang. 2025. AI Agents in Banking. InAgentic AI: Theories and Practices. Springer, 237–277
work page 2025
-
[35]
Laurie Hughes, Yogesh K Dwivedi, Tegwen Malik, Mazen Shawosh, Mousa Ahmed Albashrawi, Il Jeon, Vincent Dutot, Mandanna Appanderanda, Tom Crick, Rahul De’, et al. 2025. AI agents and agentic systems: A multi-expert analysis.Journal of Computer Information Systems(2025), 1–29
work page 2025
-
[36]
Nargiz Humbatova, Gunel Jahangirova, Gabriele Bavota, Vincenzo Riccio, Andrea Stocco, and Paolo Tonella. 2020. Taxonomy of real faults in deep learning systems. InProceedings of the ACM/IEEE 42nd international conference on software engineering. 1110–1121
work page 2020
-
[37]
Rida Ghafoor Hussain, Kin-Choong Yow, and Marco Gori. 2025. Leveraging an enhanced CodeBERT-based model for multiclass software defect prediction via defect classification.IEEE access(2025)
work page 2025
-
[38]
Zak Hussain, Marcel Binz, Rui Mata, and Dirk U Wulff. 2024. A tutorial on open-source large language models for behavioral science.Behavior Research Methods56, 8 (2024), 8214–8237
work page 2024
-
[39]
Md Johirul Islam, Giang Nguyen, Rangeet Pan, and Hridesh Rajan. 2019. A comprehensive study on deep learning bug characteristics. InProceedings of the 2019 27th ACM joint meeting on european software engineering conference and symposium on the foundations of software engineering. 510–520
work page 2019
- [40]
-
[41]
Lingxiao Jiang and Zhendong Su. 2007. Context-aware statistical debugging: from bug predictors to faulty control flow paths. InProceedings of the 22nd IEEE/ACM International Conference on Automated Software Engineering. 184–193
work page 2007
- [42]
-
[43]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real-world Github Issues?. InICLR
work page 2024
-
[44]
Haifeng Jin, Qingquan Song, and Xia Hu. 2019. Auto-keras: An efficient neural architecture search system. InProceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining. 1946–1956
work page 2019
-
[45]
kaushikb11. 2025. awesome-llm-agents: A curated list of awesome LLM agents frameworks. https://github.com/kaushikb11/awesome-llm-agents. GitHub repository, last updated: 2025-09-07
work page 2025
-
[46]
Jaehyung Kim, Dongyoung Kim, and Yiming Yang. 2024. Learning to Correct for QA Reasoning with Black-box LLMs. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Miami, Florida, USA, 8916–8937. doi:10.18653/v1/2024.emnlp-main.504
-
[47]
J Richard Landis and Gary G Koch. 1977. The measurement of observer agreement for categorical data.biometrics(1977), 159–174
work page 1977
-
[48]
Haitao Li, Qian Dong, Junjie Chen, Huixue Su, Yujia Zhou, Qingyao Ai, Ziyi Ye, and Yiqun Liu. 2024. Llms-as-judges: a comprehensive survey on llm-based evaluation methods.arXiv preprint arXiv:2412.05579(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Xia Li, Jiajun Jiang, Samuel Benton, Yingfei Xiong, and Lingming Zhang. 2021. A Large-scale Study on API Misuses in the Wild. In2021 14th IEEE Conference on Software Testing, Verification and Validation (ICST). 241–252. doi:10.1109/ICST49551.2021.00034
-
[50]
Junwei Liu, Kaixin Wang, Yixuan Chen, Xin Peng, Zhenpeng Chen, Lingming Zhang, and Yiling Lou. 2024. Large Language Model-Based Agents for Software Engineering: A Survey.CoRR(2024)
work page 2024
-
[51]
Chang Lou, Yuzhuo Jing, and Peng Huang. 2022. Demystifying and checking silent semantic violations in large distributed systems. In16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22). 91–107
work page 2022
-
[52]
Marcos Medeiros, Uirá Kulesza, Roberta Coelho, Rodrigo Bonifácio, Christoph Treude, and Eiji Adachi Barbosa. 2024. The Impact Of Bug Localization Based on Crash Report Mining: A Developers’ Perspective. InProceedings of the 46th International Conference on Software Engineering: Software Engineering in Practice. 13–24
work page 2024
-
[53]
Iraklis Moutidis and Hywel TP Williams. 2021. Community evolution on stack overflow.Plos one16, 6 (2021), e0253010. - 30 Niful Islam, Ragib Shahariar Ayon, Deepak George Thomas, Shibbir Ahmed, and Mohammad Wardat
work page 2021
-
[54]
Kaiwen Ning, Jiachi Chen, Jingwen Zhang, Wei Li, Zexu Wang, Yuming Feng, Weizhe Zhang, and Zibin Zheng. 2024. Defining and Detecting the Defects of the Large Language Model-based Autonomous Agents.CoRR(2024)
work page 2024
-
[55]
Razvan Nistor and Leonhard Applis. 2024. What about Haskell Bugs? Adapting bug taxonomies to Haskell’s features and community. InProceedings of the 36th Symposium on Implementation and Application of Functional Languages. 38–50
work page 2024
-
[56]
Wonseok Oh and Hakjoo Oh. 2024. Towards Effective Static Type-Error Detection for Python. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering. 1808–1820
work page 2024
-
[57]
OpenAI. 2025. Introducing OpenAI o3 and o4-mini. https://openai.com/index/introducing-o3-and-o4-mini/. Accessed: 2025-09-10
work page 2025
-
[58]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback. InProceedings of the 36th International Conference on Neural Information Processing Systems. 27730–27744
work page 2022
-
[59]
Shuyin Ouyang, Jie M Zhang, Mark Harman, and Meng Wang. 2025. An empirical study of the non-determinism of chatgpt in code generation. ACM Transactions on Software Engineering and Methodology34, 2 (2025), 1–28
work page 2025
-
[60]
Melissa Z Pan, Mert Cemri, Lakshya A Agrawal, Shuyi Yang, Bhavya Chopra, Rishabh Tiwari, Kurt Keutzer, Aditya Parameswaran, Kannan Ramchandran, Dan Klein, et al. 2025. Why do multiagent systems fail?. InICLR 2025 Workshop on Building Trust in Language Models and Applications
work page 2025
-
[61]
Rangeet Pan, Ali Reza Ibrahimzada, Rahul Krishna, Divya Sankar, Lambert Pouguem Wassi, Michele Merler, Boris Sobolev, Raju Pavuluri, Saurabh Sinha, and Reyhaneh Jabbarvand. 2024. Lost in translation: A study of bugs introduced by large language models while translating code. In Proceedings of the IEEE/ACM 46th International Conference on Software Engineer...
work page 2024
- [62]
-
[63]
Redis. 2025. Redis — The Real-time Data Platform. https://redis.io/. Accessed: 2025-09-10
work page 2025
-
[64]
Andrew Rice, Edward Aftandilian, Ciera Jaspan, Emily Johnston, Michael Pradel, and Yulissa Arroyo-Paredes. 2017. Detecting argument selection defects.Proceedings of the ACM on Programming Languages1, OOPSLA (2017), 1–22
work page 2017
-
[65]
Mehil B Shah, Mohammad Masudur Rahman, and Foutse Khomh. 2025. Towards understanding the impact of data bugs on deep learning models in software engineering.Empirical Software Engineering30, 6 (2025), 168
work page 2025
-
[66]
Pranet Sharma, Zhenpeng Shi, Şevval Şimşek, David Starobinski, and David Sastre Medina. 2024. Understanding Similarities and Differences Between Software Composition Analysis Tools.IEEE Security & Privacy(2024)
work page 2024
-
[67]
Qingchao Shen, Haoyang Ma, Junjie Chen, Yongqiang Tian, Shing-Chi Cheung, and Xiang Chen. 2021. A comprehensive study of deep learning compiler bugs. InProceedings of the 29th ACM Joint meeting on european software engineering conference and symposium on the foundations of software engineering. 968–980
work page 2021
- [68]
- [69]
-
[70]
Stack Overflow. 2023. how to convert the result from openai call, convert it into json and write to .txt file? https://stackoverflow.com/questions/78 959794. Accessed: 2025-09-11
work page 2023
- [71]
- [72]
- [73]
- [74]
- [75]
- [76]
- [77]
- [78]
- [79]
-
[80]
Stack Overflow. 2024. I reinstalled package llamaindex typescript and my document cannot be Indexed. https://stackoverflow.com/questions/7880
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.