Recognition: unknown
DEFault++: Automated Fault Detection, Categorization, and Diagnosis for Transformer Architectures
Pith reviewed 2026-05-07 05:28 UTC · model grok-4.3
The pith
DEFault++ detects whether a fault exists in a transformer model, classifies it into one of 12 specific categories, and identifies its root cause among up to 45 mechanisms by analyzing runtime behaviors through an architecture-derived graph.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DEFault++ operates at three levels by first detecting a fault's presence, then assigning it to one of twelve transformer-specific fault categories that cover attention-internal mechanisms and surrounding components, and finally pinpointing the root cause from as many as forty-five mechanisms. It achieves this through runtime measurements at individual component levels, structured by a Fault Propagation Graph taken from the transformer architecture itself, and applies prototype matching together with supervised contrastive learning to produce an interpretable diagnosis. The system was tested on DEFault-bench, a collection of 3,739 labeled instances generated across seven transformer models, 9
What carries the argument
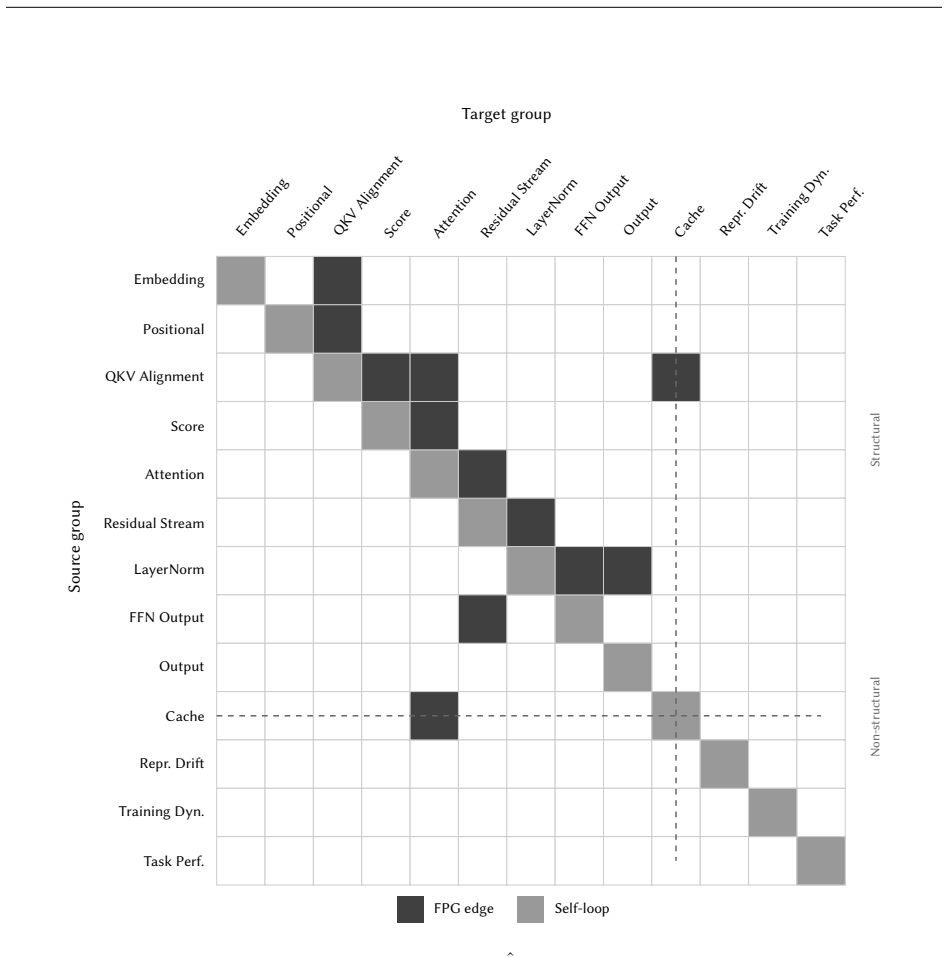
The Fault Propagation Graph derived from the transformer architecture, which organizes measurements of runtime behavior at the level of individual components such as attention heads and projections to reveal how faults affect outputs.
If this is right
- High detection performance above 0.96 AUROC allows reliable identification of faulty transformers before they affect applications.
- Macro-F1 scores of 0.85 for categorization and diagnosis support isolating issues to specific internal mechanisms.
- Practitioners using the tool choose correct repair actions at 83.3 percent accuracy compared to 57.1 percent without it.
- Both encoder-only and decoder-only architectures can be diagnosed effectively with the same approach.
Where Pith is reading between the lines
- The technique could be adapted to other types of neural networks by constructing similar propagation graphs from their architectures.
- Future work might combine this diagnosis with automated repair suggestions to further reduce manual debugging effort.
- Collecting more real-world fault data could strengthen the benchmark beyond synthetic mutations.
Load-bearing premise
The kinds of faults produced by the DEForm mutation technique match the faults that actually occur in deployed transformer models.
What would settle it
Injecting specific known faults into a running transformer model and verifying whether DEFault++ correctly detects, categorizes, and diagnoses each one based on the resulting behavior changes.
Figures
















read the original abstract
Transformer models are widely deployed in critical AI applications, yet faults in their attention mechanisms, projections, and other internal components often degrade behavior silently without raising runtime errors. Existing fault diagnosis techniques often target generic deep neural networks and cannot identify which transformer component is responsible for an observed symptom. In this article, we present DEFault++, a hierarchical learning-based diagnostic technique that operates at three level of abstraction: it detects whether a fault is present, classifies it into one of 12 transformer-specific fault categories (covering both attention-internal mechanisms and surrounding architectural components), and identifies the underlying root cause from up to 45 mechanisms. To facilitate both training and evaluation, we construct DEFault-bench, a benchmark of 3,739 labeled instances obtained through systematic mutation testing. These instances are created across seven transformer models and nine downstream tasks using DEForm, a transformer-specific mutation technique we developed for this purpose. DEFault++ measures runtime behavior at the level of individual transformer components. It organizes these measurements through a Fault Propagation Graph (FPG) derived from the transformer architecture. It then produces an interpretable diagnosis using prototype matching combined with supervised contrastive learning. On DEFault-bench, DEFault++ exceeds an AUROC of 0.96 for detection and a Macro-F1 of 0.85 for both categorization and root-cause diagnosis on encoder and decoder architectures. In a developer study with 21 practitioners, the accuracy of choosing correct repair actions increased from 57.1% without support to 83.3% when using DEFault++.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DEFault++, a hierarchical diagnostic system for transformer models that detects the presence of faults, categorizes them into one of 12 transformer-specific categories (covering attention mechanisms and other components), and identifies root causes from up to 45 mechanisms. It collects component-level runtime measurements, organizes them via an architecture-derived Fault Propagation Graph (FPG), and applies prototype matching combined with supervised contrastive learning for interpretable diagnosis. To support this, the authors construct DEFault-bench, a synthetic benchmark of 3,739 labeled instances generated by applying their DEForm mutation operators to seven transformer models across nine downstream tasks. Reported results on this benchmark include AUROC exceeding 0.96 for detection and Macro-F1 exceeding 0.85 for both categorization and root-cause diagnosis on encoder and decoder architectures; a developer study with 21 practitioners shows repair-action accuracy rising from 57.1% without the tool to 83.3% with it.
Significance. If the central claims hold, the work provides a concrete, architecture-aware approach to automated fault diagnosis tailored to transformers, which is valuable given the silent degradation these models can exhibit in deployed systems. Strengths include the explicit reporting of performance numbers on a constructed benchmark, the inclusion of a developer study measuring practical impact on repair decisions, and the use of an FPG plus contrastive learning to produce interpretable outputs rather than black-box predictions. These elements offer a foundation for further research in ML systems reliability. However, the overall significance is limited by the exclusive reliance on synthetic data whose fidelity to real faults remains unverified.
major comments (2)
- [Abstract and benchmark construction section] Abstract and benchmark construction section: The headline performance figures (AUROC > 0.96 detection; Macro-F1 > 0.85 categorization/diagnosis) and the developer-study lift (57.1% → 83.3%) are obtained exclusively on the 3,739 instances produced by DEForm mutations. No external validation set of confirmed real faults (e.g., from Hugging Face issue trackers, production logs, or known numerical/hardware bugs) is used to test whether the 12 categories and 45 root causes produce observable signatures statistically similar to those arising in deployed transformers. Because the practical utility claim rests on this assumption, the absence of such an anchor is load-bearing; if the synthetic distribution differs in activation patterns or component interactions, both the learned prototypes and the reported accuracy gains become benchmark-specific.
- [Fault Propagation Graph description (likely §3)] Fault Propagation Graph description (likely §3): The FPG is derived statically from the transformer architecture to route measurements into prototype matching. No empirical analysis is provided on whether this graph captures the actual causal paths taken by real faults (especially data-dependent or hardware-induced bugs) to the monitored outputs. This is load-bearing for the diagnosis claims because the routing directly determines which component-level features reach the contrastive learner; an incomplete graph would systematically misattribute root causes even if detection succeeds.
minor comments (3)
- [Abstract] The abstract states 'three level of abstraction' (should be 'levels').
- [Evaluation section] No details are given on statistical significance testing, confidence intervals, or cross-validation strategy for the Macro-F1 and AUROC numbers, nor on potential biases in how DEForm mutations are sampled across the seven models.
- [Developer study section] The developer study reports accuracy percentages but does not describe the exact protocol (e.g., how faults were presented, time limits, or whether participants had access to source code), making it difficult to assess the magnitude of the 26.2-point lift.
Simulated Author's Rebuttal
We thank the referee for their thorough and constructive review. We appreciate the recognition of the strengths in our hierarchical diagnostic approach, the Fault Propagation Graph, and the developer study. We address each major comment below with clarifications and proposed revisions. While we defend the controlled nature of our synthetic benchmark, we agree that additional discussion of its relation to real faults is warranted.
read point-by-point responses
-
Referee: [Abstract and benchmark construction section] Abstract and benchmark construction section: The headline performance figures (AUROC > 0.96 detection; Macro-F1 > 0.85 categorization/diagnosis) and the developer-study lift (57.1% → 83.3%) are obtained exclusively on the 3,739 instances produced by DEForm mutations. No external validation set of confirmed real faults (e.g., from Hugging Face issue trackers, production logs, or known numerical/hardware bugs) is used to test whether the 12 categories and 45 root causes produce observable signatures statistically similar to those arising in deployed transformers. Because the practical utility claim rests on this assumption, the absence of such an anchor is load-bearing; if the synthetic distribution differs in activation patterns or component interactions, both the learned prototypes and the reported accuracy gains become benchmark-specific.
Authors: We agree that all reported results, including the AUROC and Macro-F1 scores as well as the developer-study improvement, are obtained on the synthetic DEFault-bench generated by DEForm mutations. This design enables precise labeling, reproducibility, and coverage across seven models and nine tasks, which is difficult to achieve with real faults due to the absence of ground-truth root-cause annotations in public issue trackers or logs. The DEForm operators are derived from documented transformer failure modes in the literature (e.g., attention head corruption, projection matrix errors, and activation anomalies) to produce component-level signatures. The developer study further shows that practitioners benefit from the tool's outputs even on these cases. We will revise the manuscript by adding a dedicated limitations subsection that explicitly discusses potential differences in activation patterns and propagation between synthetic and real faults, along with suggestions for future curation of real-world validation sets. This clarifies the scope of our claims without altering the core experimental results. revision: partial
-
Referee: [Fault Propagation Graph description (likely §3)] Fault Propagation Graph description (likely §3): The FPG is derived statically from the transformer architecture to route measurements into prototype matching. No empirical analysis is provided on whether this graph captures the actual causal paths taken by real faults (especially data-dependent or hardware-induced bugs) to the monitored outputs. This is load-bearing for the diagnosis claims because the routing directly determines which component-level features reach the contrastive learner; an incomplete graph would systematically misattribute root causes even if detection succeeds.
Authors: The FPG is constructed statically from the transformer's computational dependencies to route component measurements to the appropriate prototypes, reflecting how faults in upstream elements (such as attention or feed-forward layers) affect downstream outputs. This architecture-derived structure supports interpretability and is validated indirectly through ablations showing higher diagnosis performance with the FPG versus flat feature aggregation. We acknowledge the lack of direct empirical analysis on causal paths for real faults, particularly data-dependent or hardware-induced ones, as such labeled instances are scarce. Our benchmark mutations include numerical instabilities and component-specific errors that approximate these cases. In the revision, we will expand the FPG section with additional justification of its static assumptions, a sensitivity analysis across fault types, and explicit discussion of scenarios where propagation may deviate (e.g., certain hardware bugs). This strengthens the methodological transparency while retaining the graph's benefits for routing and diagnosis. revision: partial
Circularity Check
No circularity: empirical results on held-out synthetic benchmark with independent labels
full rationale
The paper's core claims rest on standard supervised evaluation of a prototype-matching + contrastive model trained on DEForm-generated mutations and tested on held-out instances from the same generator. Ground-truth labels are produced by the mutation process itself and are independent of the diagnostic model's parameters or the FPG routing. No equation, prototype, or learned representation is defined in terms of the target diagnosis; the FPG is a static graph derived from architecture topology, not from observed fault effects. Performance numbers (AUROC, Macro-F1) are computed directly against these external labels rather than being recovered from fitted inputs. Self-citations, if present, are not load-bearing for the reported metrics. The absence of real-world fault validation is a generalizability issue, not a circularity in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Faults in transformer components can be simulated through systematic mutation testing.
- domain assumption The Fault Propagation Graph derived from the transformer architecture accurately models how faults affect observable runtime behavior.
invented entities (2)
-
DEForm
no independent evidence
-
Fault Propagation Graph (FPG)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization.arXiv preprint arXiv:1607.06450,
work page internal anchor Pith review arXiv
-
[2]
Gpt-neo: Large scale autoregressive language modeling with mesh-tensorflow
Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, ConnorLeahy, KyleMcDonell, JasonPhang, SamuelPittman, JonathanTow, BenWang, and Samuel Weinbach. Gpt-neo: Large scale autoregressive language modeling with mesh-tensorflow. arXiv preprint arXiv:2104.00006,
-
[3]
doi: 10.1016/S0031-3203(96)00142-2. Mateusz Buda, Atsuto Maki, and Maciej A. Mazurowski. A systematic study of the class imbalance problem in convolutional neural networks.Neural networks, 106:249–259,
-
[4]
Cuda: Compiling and optimizing for a gpu platform.Procedia Computer Science, 9:1910–1919,
Gautam Chakrabarti, Vinod Grover, Bastiaan Aarts, Xiangyun Kong, Manjunath Kudlur, Yuan Lin, Jaydeep Marathe, Mike Murphy, and Jian-Zhong Wang. Cuda: Compiling and optimizing for a gpu platform.Procedia Computer Science, 9:1910–1919,
1910
-
[5]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavar- i...
work page internal anchor Pith review arXiv
-
[6]
What does bert look at? an analysis of bert’s attention
Kevin Clark, Urvashi Khandelwal, Omer Levy, and Christopher D Manning. What does bert look at? an analysis of bert’s attention. InProceedings of the 2019 ACL Workshop BlackboxNLP, pp. 276–286,
2019
-
[7]
58 Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
arXiv:2504.02211v2. 58 Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness. InAdvances in Neural Information Process- ing Systems, volume 35, pp. 16344–16359,
-
[8]
Bert: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, pp. 4171–4186,
2019
-
[9]
How contextual are contextualized word representations? Comparing the geometry of BERT, ELMo, and GPT-2 embeddings
Kawin Ethayarajh. How contextual are contextualized word representations? Comparing the geometry of BERT, ELMo, and GPT-2 embeddings. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 55–65,
2019
-
[10]
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M. Dai, Anja Hauth, Katie Millican, David Silver, Melvin Johnson, Ioannis Antonoglou, Julian Schrittwieser, Amelia Glaese, Jilin Chen, Emily Pitler, Timothy Lilli- crap, Angeliki Lazaridou, Orhan Firat, James Molloy, Michael Isard, Paul R. ...
work page internal anchor Pith review arXiv
-
[11]
OpenWebText corpus, 2019.http://Skylion007.github.io /OpenWebTextCorpus
Aaron Gokaslan and Vanya Cohen. OpenWebText corpus, 2019.http://Skylion007.github.io /OpenWebTextCorpus. Phillip Good.Permutation, Parametric, and Bootstrap Tests of Hypotheses. Springer, 3rd edition,
2019
-
[12]
When Agents Fail: A Comprehensive Study of Bugs in LLM Agents with Automated Labeling
Niful Islam, Ragib Shahriar Ayon, Deepak George Thomas, Shibbir Ahmed, and Mohammad War- dat. When agents fail: A comprehensive study of bugs in llm agents with automated labeling. arXiv preprint arXiv:2601.15232,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
64 Sigma Jahan, Saurabh Singh Rajput, Tushar Sharma, and Mohammad Masudur Rahman
Available at:https://github.com/sigmaJahan/DEFaultPlusPlus. 64 Sigma Jahan, Saurabh Singh Rajput, Tushar Sharma, and Mohammad Masudur Rahman. Taxon- omy of faults in attention-based neural networks, 2025a. URLhttps://arxiv.org/abs/2508 .04925. Sigma Jahan, Mehil B Shah, Parvez Mahbub, and Mohammad Masudur Rahman. Improved Detection and Diagnosis of Faults...
-
[14]
Automatically finding bugs in a classifier: A systematic approach.arXiv preprint arXiv:2003.02907,
Erik Jones, Robin Jain, and Percy Liang. Automatically finding bugs in a classifier: A systematic approach.arXiv preprint arXiv:2003.02907,
-
[15]
Qimai Li, Zhichao Han, and Xiao-Ming Wu
doi: 10.1145/3729355. Qimai Li, Zhichao Han, and Xiao-Ming Wu. Deeper insights into graph convolutional networks for semi-supervised learning. InProceedings of the AAAI Conference on Artificial Intelligence, pp. 3538–3545,
-
[16]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Joshi Mandar, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach.arXiv preprint arXiv:1907.11692,
work page internal anchor Pith review arXiv 1907
-
[17]
Deepmutation: Mutation testing of deep learning systems
Lei Ma, Fuyuan Zhang, Jiyuan Sun, Minhui Xue, Bo Li, Felix Juefei-Xu, Chao Xie, Li Li, Yang Liu, Jianjun Zhao, and Yadong Wang. Deepmutation: Mutation testing of deep learning systems. In Proceedings of the IEEE International Symposium on Software Reliability Engineering (ISSRE), pp. 100–111. IEEE, 2018a. Shiqing Ma, Yingqi Liu, Wen-Chuan Lee, Xiangyu Zha...
2020
-
[18]
URLhttps://doi.org/ 10.1109/DSN-W50199.2020.00014
doi: 10.1109/DSN-W50199.2020.00014. URLhttps://doi.org/ 10.1109/DSN-W50199.2020.00014. Ruchira Manke, Mohammad Wardat, Foutse Khomh, and Hridesh Rajan. Mock deep testing: Toward separate development of data and models for deep learning. InProceedings of the IEEE/ACM 47th International Conference on Software Engineering, ICSE ’25, pp. 2970–2982. IEEE Press,
-
[19]
64 Sigma Jahan, Saurabh Singh Rajput, Tushar Sharma, and Mohammad Masudur Rahman
ISBN 9798331505691. doi: 10.1109/ICSE55347.2025.00220. URL https://doi.org/10.1109/ICSE55347.2025.00220. Mitchell P. Marcus, Beatrice Santorini, and Mary Ann Marcinkiewicz. Building a large annotated corpus of English: The Penn Treebank.Computational Linguistics, 19(2):313–330,
-
[20]
An Empirical Model of Large-Batch Training
Sam McCandlish, Jared Kaplan, Dario Amodei, and OpenAI Dota Team. An empirical model of large-batch training.arXiv preprint arXiv:1812.06162,
-
[21]
Pointer Sentinel Mixture Models
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models.arXiv preprint arXiv:1609.07843,
work page internal anchor Pith review arXiv
-
[22]
Mohammad Mehdi Morovati, Amin Nikanjam, and Foutse Khomh
Blog post. Mohammad Mehdi Morovati, Amin Nikanjam, and Foutse Khomh. Fault localization in deep learning-based software: A system-level approach.arXiv preprint arXiv:2411.08172,
-
[23]
Ramaravind K
URLhttps://openreview.net/forum?id=nzpLWnVAyah. Ramaravind K. Mothilal, Amit Sharma, and Chenhao Tan. DiCE: Diverse counterfactual expla- nations for machine learning classifiers. InProceedings of the 2020 Conference on Fairness, Ac- countability, and Transparency (FAT*), pp. 607–617. ACM,
2020
-
[24]
Gireen Naidu, Tranos Zuva, and Elias Mmbongeni Sibanda
doi: 10.1145/3351095.3372850. Gireen Naidu, Tranos Zuva, and Elias Mmbongeni Sibanda. A review of evaluation metrics in machine learning algorithms. InComputer science on-line conference, pp. 15–25. Springer,
-
[25]
OpenAI. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review arXiv
-
[26]
The LAMBADA dataset: Word prediction requiring broad discourse context
Denis Paperno, German Kruszewski, Angeliki Lazaridou, Quan Ngoc Pham, Raffaella Bernardi, Sandro Pezzelle, Marco Baroni, Gemma Boleda, and Roberto Fernández. The LAMBADA dataset: Word prediction requiring broad discourse context. InProceedings of ACL 2016,
2016
-
[27]
Ketai Qiu, Niccolò Puccinelli, Matteo Ciniselli, and Luca Di Grazia
doi: 10.1109/TSE.2025.3 543187. Ketai Qiu, Niccolò Puccinelli, Matteo Ciniselli, and Luca Di Grazia. From today’s code to tomor- row’s symphony: The ai transformation of developer’s routine by 2030.ACM Transactions on Software Engineering and Methodology, 34(5),
-
[28]
ISSN 1049-331X. doi: 10.1145/3709353. Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. OpenAI blog,
-
[29]
A multi-agent approach to fault localization via graph-based retrieval and reflexion,
Md Nakhla Rafi, Dong Jae Kim, Tse-Hsun Chen, and Shaowei Wang. A multi-agent approach to fault localization via graph-based retrieval and reflexion.arXiv preprint arXiv:2409.13642,
-
[30]
An Overview of Multi-Task Learning in Deep Neural Networks
Sebastian Ruder. An overview of multi-task learning in deep neural networks.arXiv preprint arXiv:1706.05098,
work page internal anchor Pith review arXiv
-
[31]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. Distilbert, a distilled version of BERT: Smaller, faster, cheaper and lighter.arXiv preprint arXiv:1910.01108,
work page internal anchor Pith review arXiv 1910
-
[32]
Adam Stein, Arthur Wayne, Aaditya Naik, Mayur Naik, and Eric Wong. Where’s the bug? atten- tion probing for scalable fault localization.arXiv preprint arXiv:2502.13966,
-
[33]
URLhttps://www.sciencedirect.com/science/article/abs/ pii/S0950584922002385
doi: 10.1016/j.infsof.2022.107129. URLhttps://www.sciencedirect.com/science/article/abs/ pii/S0950584922002385. Also available as arXiv:2208.06018 [cs.SE]. Yuchi Tian, Kexin Pei, Suman Jana, and Baishakhi Ray. DeepTest: Automated testing of deep- neural-network-driven autonomous cars. InProceedings of the 40th International Conference on Software Engineer...
-
[34]
ACM. doi: 10.1145/31 80155.3180220. Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems, pp. 5998–6008,
-
[35]
Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. GLUE: A multi-task benchmark and analysis platform for natural language understanding. In Proceedings of ICLR 2019,
2019
-
[36]
Deepseer: Interactive rnn explanation and debugging via state abstraction
Zhijie Wang, Yuheng Huang, Da Song, Lei Ma, and Tianyi Zhang. Deepseer: Interactive rnn explanation and debugging via state abstraction. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems (CHI ’23). ACM,
2023
-
[37]
68 Mohammad Wardat, Wei Le, and Hridesh Rajan
doi: 10.1145/3544548.3580852. 68 Mohammad Wardat, Wei Le, and Hridesh Rajan. Deeplocalize: Fault localization for deep neural networks. InProceedings of the IEEE/ACM International Conference on Software Engineering (ICSE), pp. 251–262. IEEE,
-
[38]
Mohammad Wardat, Breno Dantas Cruz, Wei Le, and Hridesh Rajan. An effective data-driven approach for localizing deep learning faults.arXiv preprint arXiv:2307.08947,
-
[39]
Atpatch: Debugging transformers via hot-fixing over-attention.arXiv preprint arXiv:2601.21695,
Shihao Weng, Yang Feng, Jincheng Li, Yining Yin, Xiaofei Xie, and Jia Liu. Atpatch: Debugging transformers via hot-fixing over-attention.arXiv preprint arXiv:2601.21695,
- [40]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.