ColorConceptBench: A Benchmark for Probabilistic Color-Concept Understanding in Text-to-Image Models
Pith reviewed 2026-05-16 11:57 UTC · model grok-4.3
The pith
Text-to-image models vary widely in color associations for implicit concepts and show low sensitivity to abstract semantics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ColorConceptBench supplies human-derived probabilistic color distributions for 1,281 implicit concepts and uses them to show that nine current text-to-image models produce color associations that vary substantially across semantic categories and display marked insensitivity to abstract semantics; these shortcomings persist under classifier-free guidance scaling and indicate that models require changes in how they acquire and represent implicit meaning.
What carries the argument
ColorConceptBench, a dataset of 6,584 expert annotations that define probabilistic color distributions as ground truth for implicit concepts.
If this is right
- Model performance varies substantially across semantic categories.
- Models exhibit a significant lack of sensitivity to abstract semantics.
- These limitations persist even when applying classifier-free guidance scaling at inference time.
- Human-like color understanding requires a shift in how models learn and represent implicit semantic meaning.
Where Pith is reading between the lines
- Training data that explicitly pairs implicit concepts with color statistics could reduce the observed gaps.
- Creative tools that generate images from emotional or state-based prompts would gain reliability if models adopted the benchmark's distributions.
- The same evaluation approach could be extended to other implicit attributes such as texture or lighting.
- Architectural differences among the nine models likely influence how well implicit color associations are encoded.
Load-bearing premise
The 6,584 expert annotations accurately capture human probabilistic color-concept associations for the 1,281 implicit concepts and serve as reliable ground truth.
What would settle it
Re-annotating the same 1,281 concepts with a new, larger panel of humans and obtaining substantially different color probability distributions would undermine the benchmark's ground truth.
Figures













read the original abstract
Text-to-image (T2I) models have advanced considerably in generating high-quality images from textual descriptions. However, their ability to associate colors with concepts remains largely constrained to explicit color names or codes, while their capacity to handle \emph{implicit concepts}, such as emotions and visual states, remains underexplored. To address this gap, we introduce ColorConceptBench, an expert-annotated benchmark that systematically evaluates color-concept associations through probabilistic color distributions. ColorConceptBench moves beyond explicit color specifications by examining how models interpret 1,281 implicit color concepts, grounded in 6,584 human annotations. Our evaluation of nine leading T2I models reveals that performance varies substantially across semantic categories, and models exhibit a significant lack of sensitivity to abstract semantics. These limitations persist even when applying classifier-free guidance scaling at inference time, suggesting that achieving human-like color understanding demands a shift in how models learn and represent implicit semantic meaning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ColorConceptBench, an expert-annotated benchmark consisting of 6,584 human annotations over 1,281 implicit color concepts (e.g., emotions and visual states). It evaluates nine leading text-to-image models on their ability to produce images whose color distributions match the human-annotated probabilistic ground truth, reporting substantial performance variation across semantic categories and a lack of sensitivity to abstract semantics that persists under classifier-free guidance scaling.
Significance. If the evaluation protocol and ground-truth annotations prove reliable, the benchmark would provide a useful diagnostic for a previously underexplored limitation in T2I models: their inability to capture probabilistic color associations with implicit rather than explicit concepts. The persistence of the deficit under guidance scaling would strengthen the case that current training regimes do not adequately encode abstract semantic color knowledge.
major comments (2)
- [Benchmark Construction] Benchmark Construction / Annotation Protocol: The claim that the 6,584 expert annotations constitute reliable probabilistic ground truth for 1,281 implicit concepts is load-bearing for all reported performance gaps and the insensitivity conclusion. No inter-annotator agreement statistics, validation against larger crowdsourced studies, or analysis of prompt-phrasing effects are provided, leaving open the possibility that systematic biases in expert selection or aggregation produce the observed model deficiencies.
- [Evaluation] Evaluation Methodology: The central finding of 'significant lack of sensitivity to abstract semantics' is stated without error bars, statistical significance tests, data-split details, or confidence intervals on the per-category scores. Without these, it is impossible to determine whether the reported variation across semantic categories and the null effect of guidance scaling exceed what would be expected from annotation noise alone.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from a concise table summarizing the nine evaluated models, their training data scale, and the exact metric used to compare generated color distributions against the human annotations.
- [Methods] Notation for the probabilistic color distributions (e.g., how the 6,584 annotations are aggregated into per-concept histograms) should be defined explicitly with an equation in the methods section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point-by-point below and will revise the manuscript to strengthen the presentation of annotation reliability and statistical analysis.
read point-by-point responses
-
Referee: [Benchmark Construction] Benchmark Construction / Annotation Protocol: The claim that the 6,584 expert annotations constitute reliable probabilistic ground truth for 1,281 implicit concepts is load-bearing for all reported performance gaps and the insensitivity conclusion. No inter-annotator agreement statistics, validation against larger crowdsourced studies, or analysis of prompt-phrasing effects are provided, leaving open the possibility that systematic biases in expert selection or aggregation produce the observed model deficiencies.
Authors: We agree that demonstrating annotation reliability is essential. In the revised manuscript we will add inter-annotator agreement statistics (Fleiss' kappa and Krippendorff's alpha) computed on the subset of concepts annotated by multiple experts. We will also report an analysis of prompt-phrasing sensitivity by re-evaluating a random sample of concepts with paraphrased prompts. A full-scale crowdsourced validation study lies outside the scope of the current revision, but we will explicitly discuss the choice of expert annotators, potential selection biases, and this as a limitation of the benchmark. revision: partial
-
Referee: [Evaluation] Evaluation Methodology: The central finding of 'significant lack of sensitivity to abstract semantics' is stated without error bars, statistical significance tests, data-split details, or confidence intervals on the per-category scores. Without these, it is impossible to determine whether the reported variation across semantic categories and the null effect of guidance scaling exceed what would be expected from annotation noise alone.
Authors: We accept this criticism and will substantially expand the evaluation section. The revision will include (i) error bars (standard deviation across concepts and bootstrap confidence intervals) on all per-category and guidance-scaling plots, (ii) statistical significance tests (ANOVA for category differences and paired t-tests for guidance scaling), (iii) explicit description of the evaluation splits and aggregation procedure, and (iv) a short analysis comparing observed differences against simulated annotation noise. These additions will allow readers to assess whether the reported insensitivity exceeds what annotation variability alone would produce. revision: yes
Circularity Check
No circularity: benchmark uses external human annotations as independent ground truth
full rationale
The paper's derivation chain consists of collecting 6,584 expert annotations to define probabilistic color distributions for 1,281 implicit concepts, then directly comparing T2I model outputs against these fixed external distributions. No parameters are fitted to model predictions, no self-citations bear load on the central claims, and no ansatz or uniqueness result is smuggled in. The reported performance gaps and insensitivity findings are empirical comparisons to an independently sourced ground truth rather than reductions by construction to the paper's own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert human annotations provide reliable probabilistic ground truth for color-concept associations.
Reference graph
Works this paper leans on
-
[1]
The earth mover’s distance as a metric for image retrieval.International Journal of Computer Vision, 40(2):99–121. Ahnaf Mozib Samin, M. Firoz Ahmed, and Md Mush- taq Shahriyar Rafee. 2025. ColorFoil: Investigating color blindness in large vision and language models. InProceedings of the North American Chapter of the Association for Computational Linguist...
-
[2]
Clex: a lexicon for exploring color, concept and emotion associations in language. InProceed- ings of the Conference of the European Chapter of the Association for Computational Linguistics, pages 306–314. Anna Wierzbicka. 1990. The meaning of color terms: semantics, culture, and cognition.Cognitive Linguis- tics, pages 99–150. Chenfei Wu, Jiahao Li, Jing...
work page internal anchor Pith review Pith/arXiv arXiv 1990
-
[3]
The colors should reflect realis- tic associations rather than cartoonish or childlike styles
Color Selection Guidelines.Annotators were asked to use the most common colors associated with each concept according to their own memory and understanding. The colors should reflect realis- tic associations rather than cartoonish or childlike styles
-
[4]
Task-specific color association.Colors must be applied strictly according to the given concept. Annotators should focus on the concept-relevant parts of the image, leaving unrelated areas uncol- ored. For example,for the concept “grassland”, only the grass should be colored; mountains, sky, and other elements should remain blank. For the concept “coffee”,...
-
[5]
Reference examples.Example images were provided to help annotators understand the target coloring goals
-
[6]
Consent Form.All annotators were required to read and sign an informed consent form before beginning the experiment, ensuring that participa- tion was voluntary and ethically compliant
-
[7]
Pre-experiment practice.Before beginning the main annotation task, each annotator completed a small pre-experiment of three images. These ini- tial annotations were manually reviewed to ensure compliance with the instructions before proceeding to the formal experiment. Payment.We pay each participant $15 for their time and effort. B.4 Quality Control. To ...
-
[8]
Qualitative Review and Iterative Verification. We first conducted a manual review process to iden- tify annotations that may deviate from common- sense or domain-consistent interpretations of the corresponding concepts. All colorized results were examined by domain experts with experience in visual semantics and design. For annotations considered potentia...
-
[9]
Quantitative Consistency Check.To guaran- tee high-quality ground truth, each concept was in- dependently annotated by five professional design- ers who underwent specific training for this task. Specifically, for each concept c, we extracted the color distributions in the UW71 space from the five annotated images, denoted as {p1, . . . , p5}. We then com...
-
[10]
Expert Verification for High-Variance Con- cepts.Recognizing that abstract or complex con- cepts may naturally exhibit higher variance (e.g., ‘rotten apple’and‘lonely cabin’), we perform a targeted review on the “long-tail” data. We iden- tify the top 10% of concepts with the highest aver- age EMD scores, indicating the lowest agreement. To distinguish be...
-
[11]
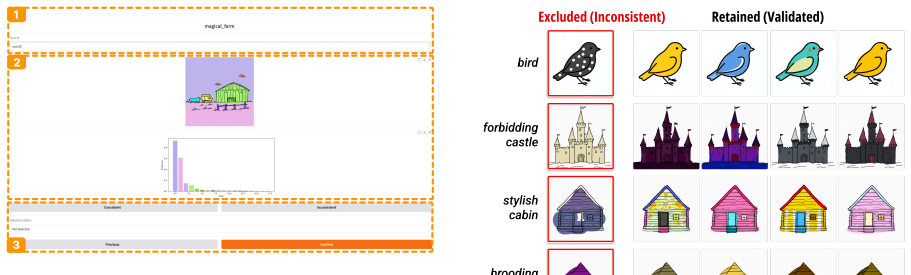
Inter-Expert Agreement Analysis.To quan- tify inter-expert agreement during the binary valida- tion process, we further analyze the distribution of expert votes across all reviewed images. Each im- age is independently evaluated by three experts and labeled as either Consistent or Inconsistent with respect to the semantic meaning of the concept. As shown ...
-
[12]
Visual Style.We explorenatural photoandcli- part cartoonas two common domains. This choice enables us to evaluate if the model captures the colors of concepts universally, or if its performance is biased towards a specific visual style
-
[13]
Classifier-Free Guidance (CFG).We focus on the CFG scale, a hyperparameter that con- trols the trade-off between alignment to the text prompt and image diversity. To investigate whether the guidance scale influences the model’s color- concept association or the diversity of color selec- tion, we evaluate the model across 7 distinct guid- ance scales. This...
-
[14]
A [Style] of a [Adjective] [Object], centered composition
Sampling Strategy.For each unique combi- nation of concept, style, and guidance scale, we generate 5 independent samples at a resolution of 1024×1024 with 50 inference steps, using distinct random seeds. C.2 Prompt Templates We utilize standardized prompt templates to trigger concept generation across different styles: • Implicit Association (Ours):“A [St...
work page 2024
-
[15]
We calculate the CIEDE2000 distance be- tween the dominant colors of different images, clustering images into the same visual group if their dominant colors are perceptually similar (∆E00 ≤12)
-
[16]
Within each group, we aggregate pixels and quantize them using8×8×8RGB bins
-
[17]
selecting the model whose color distribution best matches the human ground-truth
The top 20 colors undergo a final merging process where color centers indistinguishable Original OriginalSegmentation Segmentation Clipart Natural Image dreamy castle brooding grassland butterfly fresh banana frozen waterfall ancient cabin elephant blackberry Figure 12: Color grounding using SAM. Method Style Clipart Natural Flux 0.665 0.683 OmniGen2 0.90...
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.