Joint Learning of Hierarchical Neural Options and Abstract World Model
Pith reviewed 2026-05-16 08:03 UTC · model grok-4.3
The pith
AgentOWL jointly learns an abstract world model and hierarchical neural options to acquire skills more efficiently than model-free baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose a novel method, which we call AgentOWL, that jointly learns -- in a sample efficient way -- an abstract world model (abstracting across both states and time) and a set of hierarchical neural options. We show, on a subset of Object-Centric Atari games, that our method can learn more skills using less data than baseline methods and possesses learning and generalization capabilities that the baselines do not have.
What carries the argument
The joint optimization of an abstract world model that abstracts across states and time together with hierarchical neural options that represent multi-level skills.
Load-bearing premise
That jointly learning the abstract world model and hierarchical neural options will produce sample-efficient skill acquisition without the abstraction or optimization process introducing biases that undermine the claimed advantages.
What would settle it
A direct comparison on the same subset of object-centric Atari games in which AgentOWL fails to learn more skills with less data or shows no improvement in learning speed and generalization over the model-free baselines would falsify the central claim.
Figures







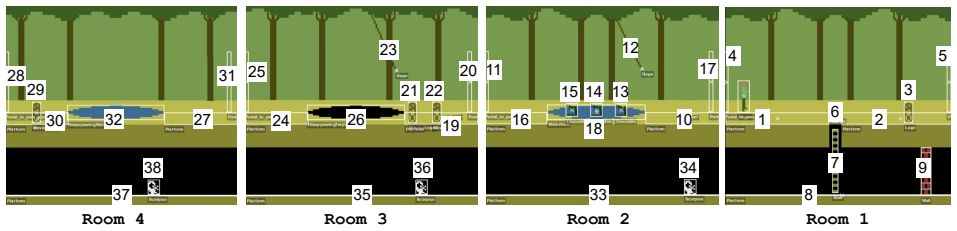

read the original abstract
Building agents that can perform new skills by composing existing skills is a long-standing goal of AI agent research. Towards this end, we investigate how to efficiently acquire a sequence of skills, formalized as hierarchical neural options. However, existing model-free hierarchical reinforcement algorithms need a lot of data. We propose a novel method, which we call AgentOWL (Option and World model Learning Agent), that jointly learns -- in a sample efficient way -- an abstract world model (abstracting across both states and time) and a set of hierarchical neural options. We show, on a subset of Object-Centric Atari games, that our method can learn more skills using less data than baseline methods and possesses learning and generalization capabilities that the baselines do not have.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AgentOWL, a method that jointly learns an abstract world model (abstracting across states and time) and a set of hierarchical neural options in a sample-efficient manner. It evaluates the approach on a subset of Object-Centric Atari games, claiming that the method learns more skills using less data than baselines while exhibiting superior learning and generalization capabilities.
Significance. If the empirical results hold under rigorous controls, the work would advance hierarchical reinforcement learning by showing how joint optimization of world models and options can improve sample efficiency and enable better skill composition and generalization in complex environments.
major comments (1)
- Abstract: The central claims of empirical superiority in skill count, data usage, and generalization are asserted without any reported metrics, baseline details, statistical tests, or experimental controls. This leaves the primary results without verifiable quantitative support and makes it impossible to assess whether the joint learning mechanism delivers the claimed advantages.
minor comments (2)
- The abstract and title use the term 'abstract world model' without a precise definition of the abstraction mechanism (e.g., state abstraction, temporal abstraction, or both) or how it is represented.
- No mention is made of the specific Object-Centric Atari games used or the choice of baselines, which are necessary for reproducibility and fair comparison.
Simulated Author's Rebuttal
Thank you for the detailed review. We have carefully considered the major comment and provide our response below. We agree that revisions to the abstract are necessary to strengthen the presentation of our results.
read point-by-point responses
-
Referee: Abstract: The central claims of empirical superiority in skill count, data usage, and generalization are asserted without any reported metrics, baseline details, statistical tests, or experimental controls. This leaves the primary results without verifiable quantitative support and makes it impossible to assess whether the joint learning mechanism delivers the claimed advantages.
Authors: We thank the referee for this observation. While the manuscript body provides detailed results including quantitative metrics on skill learning, data efficiency, baseline comparisons, and generalization on Object-Centric Atari games, along with experimental controls, we agree that the abstract should include more specific support for the claims to be self-contained. In the revised version, we will update the abstract to report key metrics, such as the number of skills learned, reductions in data usage, and generalization performance, and reference the statistical tests and controls employed. This will make the empirical superiority claims verifiable from the abstract. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes an empirical method (AgentOWL) for jointly learning hierarchical neural options and an abstract world model, with performance claims resting on experiments in Object-Centric Atari games. No equations, parameter-fitting steps presented as predictions, self-definitional constructs, or load-bearing self-citation chains appear in the abstract or high-level description. The joint-learning mechanism is offered as an independent algorithmic contribution whose advantages are evaluated externally against baselines, rendering the derivation self-contained.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a novel method, which we call AgentOWL ... that jointly learns ... an abstract world model (abstracting across both states and time) and a set of hierarchical neural options.
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
po(f′|s) using PoE-World ... each expert is a short symbolic program ... pθ(s′|s,a)=∏j p(s′j|s,a)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
PMLR, 2021b. Ball, P. J., Bauer, J., Belletti, F., Brownfield, B., Ephrat, A., Fruchter, S., Gupta, A., Holsheimer, K., Holynski, A., Hron, J., et al. Genie 3: A new frontier for world models. Google DeepMind Blog, pp. 253–279, 2025. Bellemare, M. G., Naddaf, Y ., Veness, J., and Bowling, M. The arcade learning environment: An evaluation plat- form for ge...
-
[2]
PMLR, 2016. Hafner, D., Lee, K.-H., Fischer, I., and Abbeel, P. Deep hierarchical planning from pixels.Advances in Neural Information Processing Systems, 35:26091–26104, 2022. Harutyunyan, A., Dabney, W., Borsa, D., Heess, N., Munos, R., and Precup, D. The termination critic.arXiv preprint arXiv:1902.09996, 2019. Heess, N., Wayne, G., Tassa, Y ., Lillicra...
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[3]
AnyObjTypeTouching: The player object touches a platform object
-
[4]
SpecificObjTouching: The player object touches the platform object located at (x=8, y=125)
-
[5]
SpecificObjTouching: ... Now, I want you to list 4 possible features of the input list of objects has that allows us to achieve the goal of ’{goal}’. Input list of objects: {input} Please follow these rules for your output:
-
[7]
Make the features diverse
-
[8]
Do use interactions (what the player is touching), as they usually make good features
-
[9]
Each rule should of type ’AnyObjTypeTouching’ or ’SpecificObjTouching’ Table 6.Prompt for LLM to propose preconditions for games where the agent controls only the Player object: Montezuma’s Revenge and Pitfall. 21 Joint Learning of Hierarchical Neural Options and Abstract World Model I’ll give you an input list of objects. I want you to list 4 possible fe...
-
[10]
RoomNumberExist: An object with type ’roomnumber_+0’ exists
-
[11]
Input list of objects: {input} Please follow these rules for your output:
ObjTouchingAndRoomNumberExist: The car object touches the platform object and an object with type ’roomnumber_+0’ exists Now, I want you to list 2 possible features of the input list of objects has that allows us to achieve the goal of ’{goal}’. Input list of objects: {input} Please follow these rules for your output:
-
[12]
Do not explain -- simply list each feature
-
[13]
Each rule should of type ’RoomNumberExist’ or ’ObjTouchingAndRoomNumberExist’
-
[14]
Make sure to mention the roomnumber in the feature, e.g., ’an object with type ’roomnumber_+0’ exists’ Table 7.Prompt for LLM to propose preconditions for games where the agent controls several objects: Private Eye (the agent controls Player and Car object) 22
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.