Dynamics-Aligned Shared Hypernetworks for Contextual RL under Discontinuous Shifts
Pith reviewed 2026-05-16 07:06 UTC · model grok-4.3
The pith
A hypernetwork trained solely on dynamics prediction generates shared adapter weights that enable zero-shot policy generalization under discontinuous context shifts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By training a hypernetwork exclusively through dynamics prediction and using its generated weights as shared adapters for the policy and action-value function, the framework imparts an inductive bias matched to discontinuous context-to-dynamics shifts. Input/output normalization and random input masking further stabilize context inference and promote concentrated representations. This construction is supported by expressivity separation results for hypernetwork modulation and variance decomposition bounds that quantify improved learning under non-overlapping contexts.
What carries the argument
The dynamics-aligned shared hypernetwork that generates adapter weights from inferred context to modulate policy and value functions simultaneously.
If this is right
- Zero-shot generalization succeeds on held-out tasks in the Actuator Inversion Benchmark.
- The method outperforms domain randomization by 58.1% and standard context-aware baselines by 11.5% on average.
- Theoretical results establish expressivity separation and reduced policy-gradient variance through within-mode compression.
- Normalization and masking stabilize context inference for directionally concentrated representations.
Where Pith is reading between the lines
- This shared dynamics alignment could extend to other RL domains involving latent variables or non-stationary environments.
- Similar hypernetwork modulation might improve transfer in multi-task reinforcement learning without requiring explicit task identifiers.
- Evaluating the approach on real robotic systems with variable actuator behaviors would test its practical applicability beyond simulation.
Load-bearing premise
A hypernetwork trained solely via dynamics prediction will impart an inductive bias sufficient for the policy and action-value function to handle discontinuous context-to-dynamics shifts on unseen contexts.
What would settle it
Performance on a newly constructed benchmark containing more extreme or previously unseen discontinuous shifts would falsify the claim if DMA*-SH shows no advantage over non-shared baselines or fails to achieve zero-shot transfer.
Figures

























read the original abstract
Zero-shot generalization in contextual reinforcement learning remains a core challenge, particularly when the context is latent and must be inferred from data. A canonical failure mode arises when latent context discontinuously changes how actions affect the environment, requiring incompatible control responses across contexts. We propose DMA*-SH, a framework where a single hypernetwork, trained solely via dynamics prediction, generates a small set of adapter weights shared across the dynamics model, policy, and action-value function. This shared modulation imparts an inductive bias matched to discontinuous context-to-dynamics shifts, while input/output normalization and random input masking stabilize context inference, promoting directionally concentrated representations. We provide theoretical support via expressivity separation results for hypernetwork modulation, and a variance decomposition with policy-gradient variance bounds that formalize how within-mode compression improves learning under non-overlapping contexts. For evaluation, we introduce the Actuator Inversion Benchmark (AIB), a suite of environments designed to isolate challenging context-to-dynamics interactions, including actuator inversion, actuator permutations, and weakly non-overlapping continuous dynamics. On AIB's held-out tasks, DMA*-SH achieves zero-shot generalization, outperforming domain randomization by 58.1% and surpassing a standard context-aware baseline by 11.5% on average.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DMA*-SH, a shared hypernetwork framework for contextual RL under discontinuous shifts. A single hypernetwork is trained exclusively via dynamics prediction to generate a small set of adapter weights that are shared across the dynamics model, policy, and action-value function. Input/output normalization and random input masking are used to stabilize context inference. Theoretical support is provided via expressivity separation results for hypernetwork modulation and a variance decomposition with policy-gradient variance bounds. The authors introduce the Actuator Inversion Benchmark (AIB) and report that DMA*-SH achieves zero-shot generalization on held-out AIB tasks, outperforming domain randomization by 58.1% and a standard context-aware baseline by 11.5% on average.
Significance. If the central claim holds, the work would be significant for contextual RL because it offers a dynamics-aligned inductive bias that enables zero-shot transfer across non-overlapping context-to-dynamics mappings without requiring policy-specific supervision. The introduction of AIB as a targeted benchmark for actuator inversion and permutation shifts is a useful contribution, and the combination of expressivity separation with variance bounds provides a formal lens on why within-mode compression can reduce policy-gradient variance under discontinuous shifts.
major comments (2)
- [theoretical support section (expressivity separation and variance decomposition)] The central claim that dynamics-only hypernetwork training suffices to produce policy and Q-function adapters for zero-shot control on unseen discontinuous shifts is not fully supported by the provided theoretical results. The expressivity separation establishes representational capacity but does not address whether gradient descent on the dynamics loss recovers the specific modulation required for optimal control; this gap directly affects the zero-shot generalization claim on AIB held-out tasks.
- [variance decomposition with policy-gradient variance bounds] The variance decomposition and policy-gradient variance bounds assume that within-mode compression improves learning under non-overlapping contexts, yet the manuscript does not demonstrate that the hypernetwork-generated adapters remain aligned with the optimal policy when context must be inferred from partial observations on held-out AIB tasks. This assumption is load-bearing for the reported 58.1% and 11.5% gains.
minor comments (2)
- [method description] The description of random input masking and normalization could be clarified with a precise algorithmic statement or pseudocode to allow reproduction of the context-inference stabilization.
- [evaluation section] AIB environment details (state/action dimensions, exact definitions of actuator inversion and permutation modes, and how held-out tasks are sampled) should be expanded in the main text or appendix to facilitate independent verification of the discontinuous-shift isolation.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our work. We provide point-by-point responses to the major comments below. Our responses focus on clarifying the scope of the theoretical results and highlighting the supporting empirical evidence from the Actuator Inversion Benchmark.
read point-by-point responses
-
Referee: [theoretical support section (expressivity separation and variance decomposition)] The central claim that dynamics-only hypernetwork training suffices to produce policy and Q-function adapters for zero-shot control on unseen discontinuous shifts is not fully supported by the provided theoretical results. The expressivity separation establishes representational capacity but does not address whether gradient descent on the dynamics loss recovers the specific modulation required for optimal control; this gap directly affects the zero-shot generalization claim on AIB held-out tasks.
Authors: The referee correctly notes that our expressivity separation result establishes that hypernetworks can represent the required modulations but does not guarantee that training on dynamics prediction via gradient descent will find the specific parameters needed for optimal control. We do not claim such a guarantee in the manuscript; the theoretical section focuses on separation of expressivity and variance reduction under within-mode compression. The zero-shot generalization claim is substantiated by the experimental results on held-out AIB tasks, where the method achieves substantial improvements without policy-specific supervision. We believe this empirical validation is sufficient for the contribution, and no changes are required to the theoretical claims as they are accurately stated. revision: no
-
Referee: [variance decomposition with policy-gradient variance bounds] The variance decomposition and policy-gradient variance bounds assume that within-mode compression improves learning under non-overlapping contexts, yet the manuscript does not demonstrate that the hypernetwork-generated adapters remain aligned with the optimal policy when context must be inferred from partial observations on held-out AIB tasks. This assumption is load-bearing for the reported 58.1% and 11.5% gains.
Authors: Regarding the variance decomposition, the bounds are derived to show how within-mode compression can reduce policy gradient variance in non-overlapping contexts. While the manuscript does not include a separate analysis proving adapter alignment under partial observations, the AIB benchmark is specifically designed to test this scenario, and the performance gains (58.1% over domain randomization and 11.5% over context-aware baseline) provide evidence that the adapters are aligned sufficiently for effective zero-shot control. The context inference is stabilized by the proposed normalization and masking techniques. We can revise the manuscript to include a short paragraph discussing the reliance on empirical validation for this aspect. revision: partial
- The theoretical analysis does not include a proof that gradient descent on the dynamics loss recovers the optimal control adapters for unseen shifts.
Circularity Check
No load-bearing circularity in derivation chain
full rationale
The central proposal trains a hypernetwork solely on dynamics prediction to produce shared adapters for policy and value functions; this is an explicit design choice whose generalization to held-out AIB tasks is evaluated empirically rather than derived tautologically from the training objective. Expressivity separation results and variance decomposition bounds are invoked as independent theoretical support without reduction to self-citations or fitted parameters renamed as predictions. No self-definitional loops, ansatz smuggling via prior work, or uniqueness theorems imported from the same authors appear in the provided text. The performance claims (58.1% and 11.5% gains) are presented as measured outcomes on external benchmarks, not forced by construction from the inputs.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
hypernetwork hη(zt) generates adapter weights ω shared across dynamics model, policy, and Q-function; trained solely via reconstruction loss Lϕ,θ,η = ||δŝt+1 − δst+1||²
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
multiplicative adapters realize bilinear interactions W(ω)x with ω=hη(z); separation from concatenation ReLU MLPs (Theorem A.1)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
The binary modeSis decision-critical (wrong sign can catastrophically flip the control law)
-
[2]
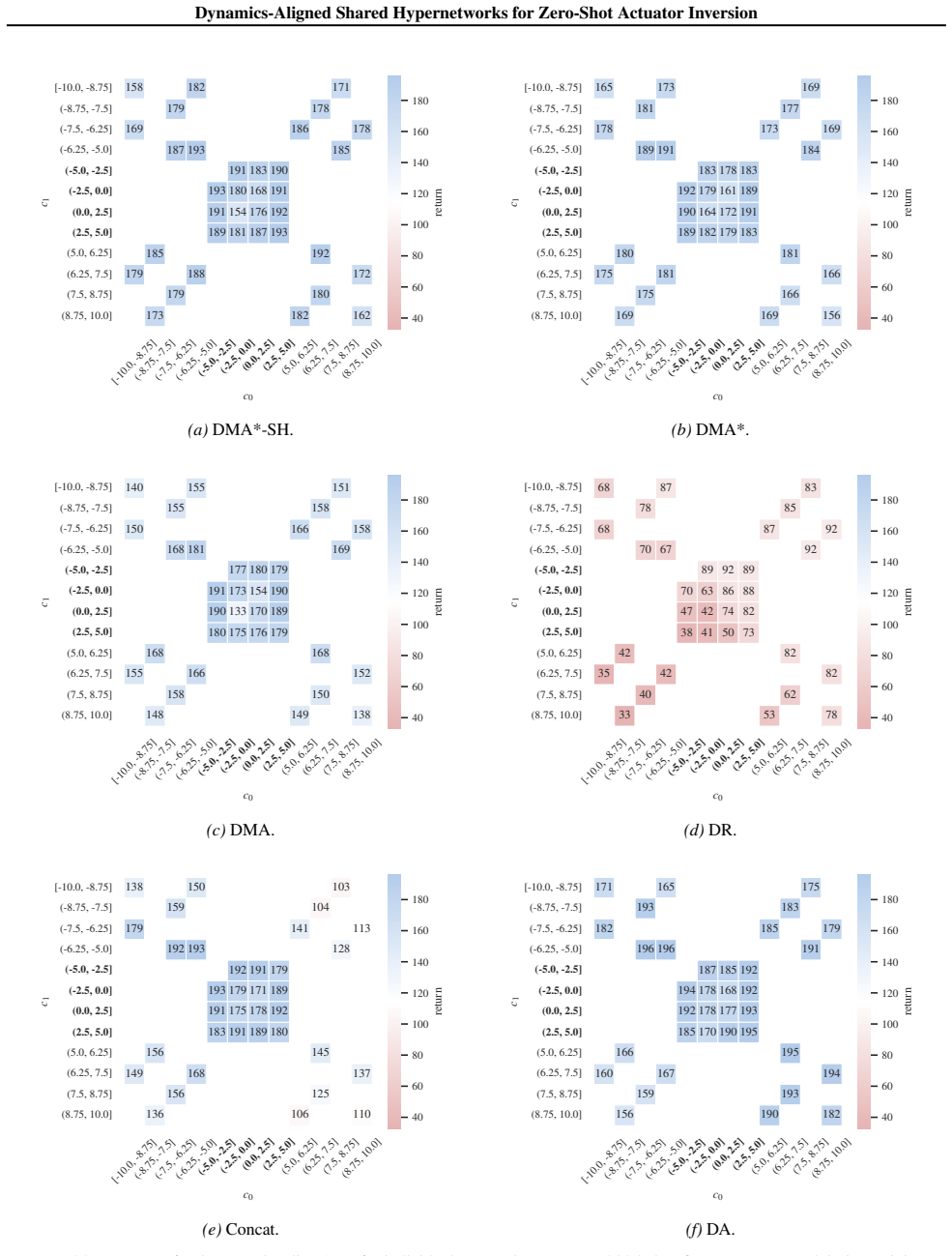
The continuous coordinate U (e.g., mass) may be weakly relevant or even largely irrelevantwithin each modeover the benchmark range, especially if robust control can handle that variation. Intuitively, one might expect that embeddings capturing more information about the full context(S, U) would yield better RL performance. Proposition A.14 shows this intu...
-
[3]
The policy-gradient variance upper bound improves despite lower Informativeness:If the policy-gradient estimator computed with eZsatisfies the same assumptions of Theorem A.13 with the same constantsV 0 andL m, then tr(Cov(G eZ))≤V 0 +L 2 m tr(Cov(eZ))< V 0 +L 2 m tr(Cov(Z)), whenever the inequality in Part 2 is strict. Thus, a representation can beless i...
-
[4]
IfI(Z;U|S) = 0, thenTerm 2 = 0
-
[5]
The converse does not hold:Term 2 = 0does not implyI(Z;U|S) = 0. Proof. Part 1.By definition, I(Z;U|S) = 0 if and only if Z⊥U|S , meaning p(Z|S=s, U=u) =p(Z|S=s) for all s, u. This implies ¯z(s, u) =E[Z|S=s, U=u] =E[Z|S=s] =µ s for all u. Since ¯z(s, u) =µs is constant in u, we haveCov U|S=s (¯z(s, U)) = 0for eachs. Averaging overSand taking 1 dz tr(·)yie...
work page 2000
-
[6]
Rapid mode acquisition. I(Z;S) increases quickly and enters a near-saturated regime (relative to H(S) ) early in optimization, indicating rapid acquisition of mode information. In Cartpole and Reacher, I(Z;S) approaches values close toln 2, whereas in DI the attained level is lower but still substantial
-
[7]
Slower within-mode refinement. I(Z;U|S) increases more gradually and typically continues to rise after I(Z;S) has effectively plateaued. The eventual level of I(Z;U|S) is task-dependent, with Reacher exhibiting markedly larger within-mode information than DI or Cartpole, consistent with arm-length scaling being more consequential for Reacher’s kinematics/...
-
[8]
The accompanying behavior ofVariability(M)and returns is environment-specific
Regime changes aligned with mode saturation.Visible kinks (regime changes) occur around the time I(Z;S) enters its near-saturated regime. The accompanying behavior ofVariability(M)and returns is environment-specific. 0.6 0.8 I(Z;S,U) DI 0.6 0.9 Cartpole 0.6 1.2 Reacher (H) 0.57 0.60 I(Z;S) 0.56 0.64 0.650 0.675 0.1 0.2 I(Z;U|S) 0.15 0.30 0.3 0.6 10−2 6 × ...
work page 2008
-
[9]
Mean policy hypernetwork sensitivity (η-space): E∥∇ηLπ∥ (DMA*-SH) and E∥∇ηπ Lπ∥ (DMA*-H). Across environ- ments, the DMA*-SH curve remains substantially larger than DMA*-H, indicating a persistent hypothetical tendency of the policy objective to reshape the shared hypernetwork mapping if such updates were enabled. This is consistent with the actor and cri...
-
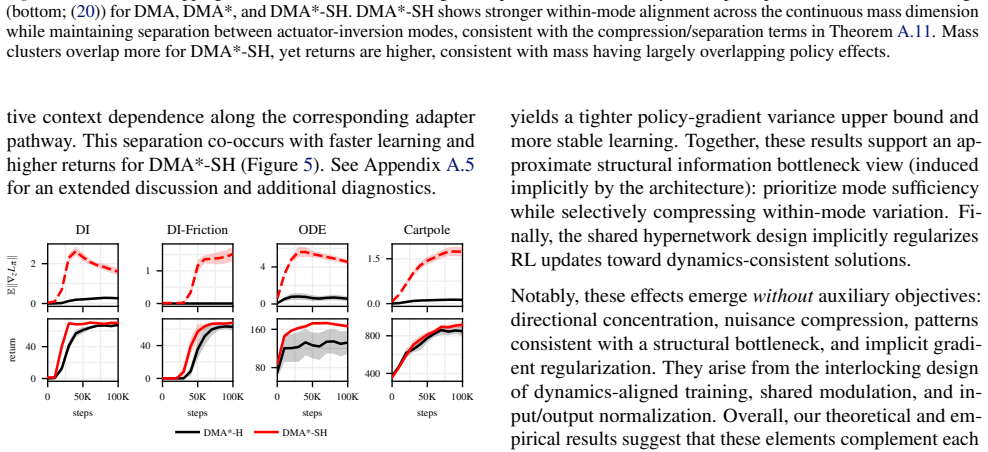
[10]
Mean policy context sensitivity (z-space): E∥∇zLπ∥. DMA*-SH exhibits consistently larger values than DMA*-H, indicating stronger dependence of the policy objective on the inferred context through the adapter pathway. In DMA*-H, the smaller values are consistent with weaker effective context utilization along this route
-
[11]
Variance of policy gradients w.r.t. context (z-space): Var∥∇zLπ∥. Unlike the mean sensitivity, which captures persistent dependence on the adapter pathway, the relative ordering varies across environments, suggesting that the variance is influenced by environment-specific nonstationarity and mode-switching
-
[12]
Variance of policy base-parameter gradient norms (ξ-space): Var∥∇ξLπ∥. DMA*-SH typically shows slightly lower variance than DMA*-H, consistent with a modestly more stable optimization signal for the policy base parameters under shared adapters
-
[13]
This measures variance of the dynamics- driven learning signal entering the context encoder
Variance of context-encoder gradients under dynamics (ϕ-space): Var∥∇ϕLd∥. This measures variance of the dynamics- driven learning signal entering the context encoder. Values are small in magnitude, but DMA*-SH often shows slightly lower variance than DMA*-H
-
[14]
embedding ( z-space): Var∥∇zLd∥
Variance of dynamics gradients w.r.t. embedding ( z-space): Var∥∇zLd∥. This measures variance of the dynamics objective’s sensitivity to the inferred embedding inRdz. Magnitudes are small, so this metric serves mainly as a weak supporting diagnostic
-
[15]
Dynamics–policy alignment (η-space): cos(∇ηLd,∇ ηLπ) (DMA*-SH) and a heuristic analogue in DMA*-H comparing ηf and ηπ. In DMA*-SH, this cosine tracks whether the (hypothetical) reward-driven direction in the sharedη coordinates tends to align with or oppose the dynamics-driven direction. In DMA*-H, the corresponding cosine is a heuristic as it compares di...
-
[16]
Policy–critic alignment (η-space): cos(∇ηLπ,∇ ηLQ) (DMA*-SH) and a heuristic analogue in DMA*-H comparing ηπ and ηQ. In DMA*-SH, this cosine summarizes whether actor and critic objectives would push the shared hypernetwork parameters in similar directions under the hypothetical update. In DMA*-H, the corresponding cosine is a heuristic as it compares diff...
-
[17]
DMA*-SH attains faster learning and higher returns than DMA*-H across the considered environments
Returns. DMA*-SH attains faster learning and higher returns than DMA*-H across the considered environments. This performance gap co-occurs with the separation in E∥∇ηLπ∥ and E∥∇zLπ∥, consistent with stronger and more persistent context dependence through the shared adapter pathway. Overall, the most consistent separation is in the mean context-sensitivity...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.