VDCook:DIY video data cook your MLLMs
Pith reviewed 2026-05-15 16:49 UTC · model grok-4.3
The pith
VDCook automatically builds and continuously updates specialized video datasets for multimodal models from natural language queries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
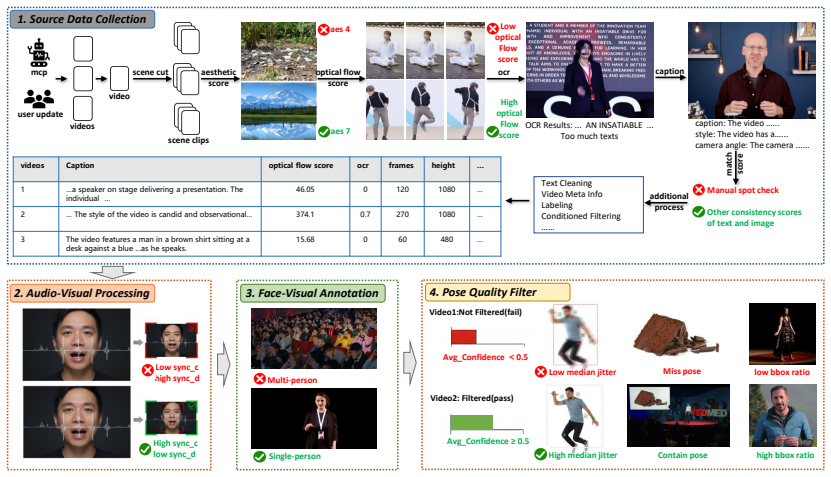
VDCook establishes a self-evolving video data operating system in which users issue natural language queries and adjustable parameters, after which the platform performs query optimization, concurrently executes real video retrieval and controlled synthesis modules, and outputs complete in-domain data packages equipped with provenance, metadata annotations, and reproducible notebooks, thereby transforming static datasets into dynamically evolving ecosystems via MCP-driven automated ingestion.
What carries the argument
MCP-based automated data ingestion mechanism that orchestrates concurrent real-video retrieval and controlled synthesis modules.
If this is right
- Datasets receive continuous updates and domain expansion through automated ingestion rather than periodic manual reconstruction.
- Multi-dimensional metadata annotations support flexible later-stage data cooking and indexing.
- Each generated package includes reproducible notebooks that enable exact recreation of the data construction process.
- The platform supports community contributions under a governance model for shared ecosystem growth.
Where Pith is reading between the lines
- Integration of VDCook outputs into existing MLLM fine-tuning pipelines could shorten the time from domain identification to usable training data.
- Similar automated ingestion patterns might extend to other modalities such as audio or sensor streams where provenance tracking is required.
- Long-term maintenance costs would shift from data collection labor to oversight of the ingestion parameters and quality thresholds.
- Open-ecosystem growth depends on adoption incentives that encourage users to contribute new ingestion rules or verified data packages.
Load-bearing premise
The automated retrieval and synthesis modules can reliably generate high-quality, in-domain video data without substantial manual curation or quality loss.
What would settle it
A controlled experiment measuring downstream MLLM accuracy on domain-specific video tasks when trained on VDCook-generated packages versus matched manually curated datasets of identical scale.
Figures













read the original abstract
We introduce VDCook: a self-evolving video data operating system, a configurable video data construction platform for researchers and vertical domain teams. Users initiate data requests via natural language queries and adjustable parameters (scale, retrieval-synthesis ratio, quality threshold). The system automatically performs query optimization, concurrently running real video retrieval and controlled synthesis modules. It ultimately generates in-domain data packages with complete provenance and metadata, along with reproducible Notebooks. Unlike traditional static, one-time-built datasets, VDCook enables continuous updates and domain expansion through its automated data ingestion mechanism based on MCP (Model Context Protocol)\cite{mcp2024anthropic}, transforming datasets into dynamically evolving open ecosystems. The system also provides multi-dimensional metadata annotation (scene segmentation, motion scoring, OCR ratio, automatic captioning, etc.), laying the foundation for flexible subsequent data `cooking' and indexing\cite{vlogger}. This platform aims to significantly lower the barrier to constructing specialized video training datasets through infrastructure-level solutions, while supporting community contributions and a governance-enabled data expansion paradigm. \textbf{Project demo:} https://screenapp.io/app/v/WP0SvffgsH
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VDCook, a self-evolving video data operating system and configurable platform for constructing video datasets for MLLMs. Users initiate requests via natural language queries with adjustable parameters for scale, retrieval-synthesis ratio, and quality threshold. The system performs automated query optimization, concurrent real video retrieval and controlled synthesis, generating in-domain data packages with complete provenance, multi-dimensional metadata (such as scene segmentation, motion scoring, OCR ratio, and automatic captioning), and reproducible notebooks. It claims to enable continuous updates and domain expansion through MCP-based automated data ingestion, transforming static datasets into dynamically evolving open ecosystems while supporting community contributions and governance.
Significance. If the system's reliability is demonstrated, VDCook could substantially lower the barrier for researchers and vertical domain teams to build and maintain specialized video training datasets for multimodal models. The emphasis on provenance, metadata, and reproducibility could enhance data quality and facilitate ongoing community-driven expansion, representing a potentially useful infrastructure contribution in the field of data-centric AI.
major comments (2)
- [Abstract] Abstract: The assertion that VDCook 'enables continuous updates and domain expansion' and transforms datasets into 'dynamically evolving open ecosystems' is not supported by any quantitative results, ablation studies, quality metrics, or comparisons to existing data construction pipelines.
- [Abstract] Abstract: The description of the concurrent retrieval and controlled synthesis modules combined with MCP-based ingestion does not include any evidence or evaluation showing that they reliably produce high-quality, in-domain video data without substantial manual curation or quality degradation.
minor comments (2)
- The citations for MCP and vlogger are referenced but no reference list or full bibliographic details are provided in the manuscript.
- The project demo link is mentioned, but the paper does not elaborate on the specific demonstrations or results shown in the demo.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the current manuscript would benefit from additional empirical support and will revise to address the points raised.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that VDCook 'enables continuous updates and domain expansion' and transforms datasets into 'dynamically evolving open ecosystems' is not supported by any quantitative results, ablation studies, quality metrics, or comparisons to existing data construction pipelines.
Authors: We acknowledge that the manuscript currently supports these claims primarily through the system design, the MCP-based ingestion mechanism, and the live demo rather than through quantitative benchmarks. In the revision we will add a new evaluation section reporting preliminary metrics from the deployed system, including data freshness over multiple ingestion cycles, measured domain expansion (e.g., new scene categories added), and direct comparisons against static dataset construction baselines. Ablation results on the contribution of the automated ingestion component will also be included. revision: yes
-
Referee: [Abstract] Abstract: The description of the concurrent retrieval and controlled synthesis modules combined with MCP-based ingestion does not include any evidence or evaluation showing that they reliably produce high-quality, in-domain video data without substantial manual curation or quality degradation.
Authors: The referee correctly notes the absence of explicit quality evaluations. We will revise the manuscript to report concrete metrics collected from the VDCook demo, such as in-domain relevance scores, motion and scene quality distributions, and the fraction of outputs requiring manual review. We will also document the effect of the configurable quality threshold on curation effort and any observed cases of quality degradation, thereby providing the requested evidence while transparently discussing remaining limitations. revision: yes
Circularity Check
No significant circularity; architectural description relies on external MCP citation without self-referential reductions or fitted predictions
full rationale
The paper presents VDCook as a configurable platform for video data construction using natural-language queries, concurrent retrieval/synthesis modules, and MCP-based ingestion for continuous updates. No equations, parameters, or predictions appear that reduce by construction to inputs. Citations to MCP (Anthropic) and Vlogger are external and not self-citations by the single author. The central claim of transforming static datasets into evolving ecosystems is an architectural assertion, not a mathematical derivation that loops back on itself. The system is self-contained against external benchmarks with no load-bearing self-citation chains or ansatz smuggling.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Automated retrieval combined with controlled synthesis produces usable in-domain video data at scale.
- domain assumption MCP enables reliable automated data ingestion for self-evolving datasets.
Reference graph
Works this paper leans on
-
[1]
Model context protocol (mcp).https://modelcontextprotocol.io, 2024
Anthropic. Model context protocol (mcp).https://modelcontextprotocol.io, 2024. Accessed: 2024-12-20
work page 2024
-
[2]
Frozen in time: A joint video and image encoder for end-to-end retrieval
Max Bain, Arsha Nagrani, G¨ ul Varol, and Andrew Zisserman. Frozen in time: A joint video and image encoder for end-to-end retrieval. InIEEE International Conference on Computer Vision (ICCV), 2021
work page 2021
-
[3]
Lumiere: A space-time diffusion model for video generation
Omer Bar-Tal, Hila Chefer, Omer Tov, Charles Herrmann, Roni Paiss, Shiran Zada, Ariel Ephrat, Junhwa Hur, Guanghui Liu, Amit Raj, et al. Lumiere: A space-time diffusion model for video generation. InSIGGRAPH Asia 2024 Conference Papers, pages 1–11, 2024
work page 2024
-
[4]
Activ- itynet: A large-scale video benchmark for human activity understanding
Fabian Caba Heilbron, Victor Escorcia, Bernard Ghanem, and Juan Carlos Niebles. Activ- itynet: A large-scale video benchmark for human activity understanding. InProceedings of the ieee conference on computer vision and pattern recognition, pages 961–970, 2015
work page 2015
-
[5]
Pyscenedetect.Last accessed, 2020
Brandon Castellano. Pyscenedetect.Last accessed, 2020
work page 2020
-
[6]
Coherent online video style transfer
Dongdong Chen, Jing Liao, Lu Yuan, Nenghai Yu, and Gang Hua. Coherent online video style transfer. InProceedings of the IEEE international conference on computer vision, pages 1105–1114, 2017
work page 2017
-
[7]
Panda-70m: Captioning 70m videos with multiple cross-modality teachers
Tsai-Shien Chen, Aliaksandr Siarohin, Willi Menapace, Ekaterina Deyneka, Hsiang-wei Chao, Byung Eun Jeon, Yuwei Fang, Hsin-Ying Lee, Jian Ren, Ming-Hsuan Yang, et al. Panda-70m: Captioning 70m videos with multiple cross-modality teachers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13320– 13331, 2024
work page 2024
-
[8]
Two-frame motion estimation based on polynomial expansion
Gunnar Farneb¨ ack. Two-frame motion estimation based on polynomial expansion. In Scandinavian Conference on Image Analysis, pages 363–370. Springer, 2003
work page 2003
-
[9]
Vbench: Comprehensive benchmark suite for video generative models
Zanyi Huang et al. Vbench: Comprehensive benchmark suite for video generative models. InCVPR, 2024
work page 2024
-
[10]
Xuan Ju, Yiming Gao, Zhaoyang Zhang, Ziyang Yuan, Xintao Wang, Ailing Zeng, Yu Xiong, Qiang Xu, and Ying Shan. Miradata: A large-scale video dataset with long durations and structured captions.Advances in Neural Information Processing Systems, 37:48955–48970, 2024
work page 2024
-
[11]
The Kinetics Human Action Video Dataset
Will Kay et al. The kinetics human action video dataset.arXiv preprint arXiv:1705.06950, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[12]
Mvbench: A comprehensive multi-modal video understanding bench- mark
Kunchang Li et al. Mvbench: A comprehensive multi-modal video understanding bench- mark. InCVPR, 2024
work page 2024
-
[13]
An iterative image registration technique with an application to stereo vision
Bruce D Lucas and Takeo Kanade. An iterative image registration technique with an application to stereo vision. InProceedings of the 7th International Joint Conference on Artificial Intelligence (IJCAI), pages 674–679, 1981. 15
work page 1981
-
[14]
Video-chatgpt: Towards detailed video understanding via large language models
Muhammad Maaz et al. Video-chatgpt: Towards detailed video understanding via large language models. InACL, 2024
work page 2024
-
[15]
Howto100m: Learning a text-video embedding by watching hundred million narrated video clips
Antoine Miech, Dimitri Zhukov, Jean-Baptiste Alayrac, Makarand Tapaswi, Ivan Laptev, and Josef Sivic. Howto100m: Learning a text-video embedding by watching hundred million narrated video clips. InProceedings of the IEEE/CVF international conference on computer vision, pages 2630–2640, 2019
work page 2019
-
[16]
A survey of ocr evaluation tools and metrics
Clemens Neudecker, Konstantin Baierer, Mike Gerber, Christian Clausner, Apostolos An- tonacopoulos, and Stefan Pletschacher. A survey of ocr evaluation tools and metrics. In Proceedings of the 6th International Workshop on Historical Document Imaging and Pro- cessing, pages 13–18, 2021
work page 2021
-
[17]
Ariel Shaulov, Itay Hazan, Lior Wolf, and Hila Chefer. Flowmo: Variance-based flow guidance for coherent motion in video generation.arXiv preprint arXiv:2506.01144, 2025
-
[18]
VidGen-1M: A large-scale dataset for text-to-video generation
Zhiyu Tan, Xiaomeng Yang, Luozheng Qin, and Hao Li. Vidgen-1m: A large-scale dataset for text-to-video generation.arXiv preprint arXiv:2408.02629, 2024
-
[19]
Linrui Tian, Qi Wang, Bang Zhang, and Liefeng Bo. Emo: Emote portrait alive generating expressive portrait videos with audio2video diffusion model under weak conditions. In European Conference on Computer Vision, pages 244–260. Springer, 2024
work page 2024
-
[20]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
V-express: Conditional dropout for progressive training of portrait video generation,
Cong Wang, Kuan Tian, Jun Zhang, Yonghang Guan, Feng Luo, Fei Shen, Zhiwei Jiang, Qing Gu, Xiao Han, and Wei Yang. V-express: Conditional dropout for progressive training of portrait video generation.arXiv preprint arXiv:2406.02511, 2024
-
[22]
Qiuheng Wang, Yukai Shi, Jiarong Ou, Rui Chen, Ke Lin, Jiahao Wang, Boyuan Jiang, Haotian Yang, Mingwu Zheng, Xin Tao, et al. Koala-36m: A large-scale video dataset improving consistency between fine-grained conditions and video content. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 8428–8437, 2025
work page 2025
-
[23]
Styleheat: One-shot high-resolution editable talking face generation via pre-trained stylegan
Fei Yin, Yong Zhang, Xiaodong Cun, Mingdeng Cao, Yanbo Fan, Xuan Wang, Qingyan Bai, Baoyuan Wu, Jue Wang, and Yujiu Yang. Styleheat: One-shot high-resolution editable talking face generation via pre-trained stylegan. InEuropean conference on computer vision, pages 85–101. Springer, 2022
work page 2022
-
[24]
Celebv-text: A large-scale facial text-video dataset
Jianhui Yu, Hao Zhu, Liming Jiang, Chen Change Loy, Weidong Cai, and Wayne Wu. Celebv-text: A large-scale facial text-video dataset. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14805–14814, 2023
work page 2023
-
[25]
Jiajing Zhang, Yongwei Miao, Junsong Zhang, and Jinhui Yu. Inkthetics: a comprehen- sive computational model for aesthetic evaluation of chinese ink paintings.IEEE Access, 8:225857–225871, 2020
work page 2020
-
[26]
Open-Sora: Democratizing Efficient Video Production for All
Zangwei Zheng, Xiangyu Peng, Tianji Yang, Chenhui Shen, Shenggui Li, Hongxin Liu, Yukun Zhou, Tianyi Li, and Yang You. Open-sora: Democratizing efficient video produc- tion for all.arXiv preprint arXiv:2412.20404, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Aven-Le Zhou. Negative shanshui: Real-time interactive ink painting synthesis.arXiv preprint arXiv:2508.16612, 2025. 16
-
[28]
Vlogger: Make your dream a vlog
Shaobin Zhuang, Kunchang Li, Xinyuan Chen, Yaohui Wang, Ziwei Liu, Yu Qiao, and Yali Wang. Vlogger: Make your dream a vlog. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8806–8817, 2024. 17
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.