Recognition: no theorem link
Dress-ED: Instruction-Guided Editing for Virtual Try-On and Try-Off
Pith reviewed 2026-05-15 00:09 UTC · model grok-4.3
The pith
Dress-ED provides the first large-scale benchmark unifying virtual try-on, virtual try-off and text-guided garment editing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
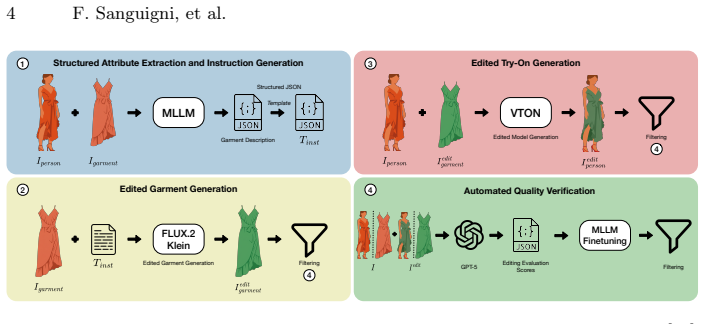
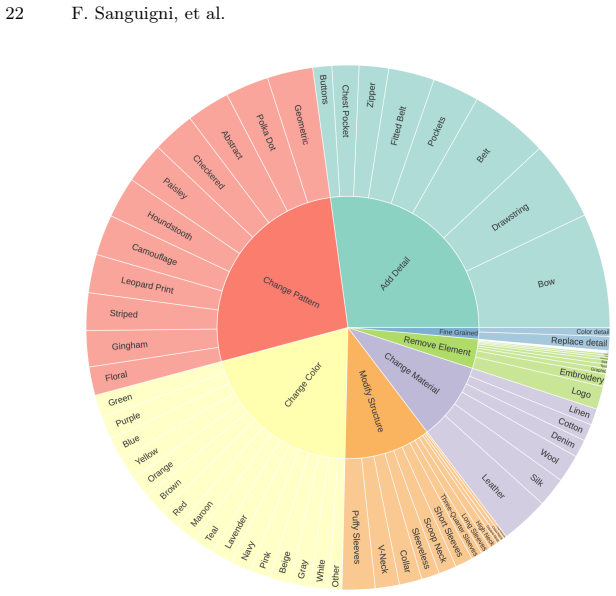
We introduce the Dress Editing Dataset (Dress-ED), the first large-scale benchmark that unifies VTON, VTOFF, and text-guided garment editing within a single framework. Each sample in Dress-ED includes an in-shop garment image, the corresponding person image wearing the garment, their edited counterparts, and a natural-language instruction of the desired modification. Built through a fully automated multimodal pipeline that integrates MLLM-based garment understanding, diffusion-based editing, and LLM-guided verification, Dress-ED comprises over 146k verified quadruplets spanning three garment categories and seven edit types, including both appearance (e.g., color, pattern, material) and the e
What carries the argument
The quadruplet consisting of in-shop garment image, person image, edited counterparts and natural-language instruction, generated by an automated pipeline of MLLM understanding, diffusion editing and LLM verification.
If this is right
- Models trained on the dataset can perform text-guided virtual try-on and virtual try-off in one system.
- The benchmark supports both appearance edits such as color and pattern changes and structural edits such as sleeve length and neckline adjustments.
- A single evaluation set now exists for instruction-driven fashion synthesis tasks that were previously handled separately.
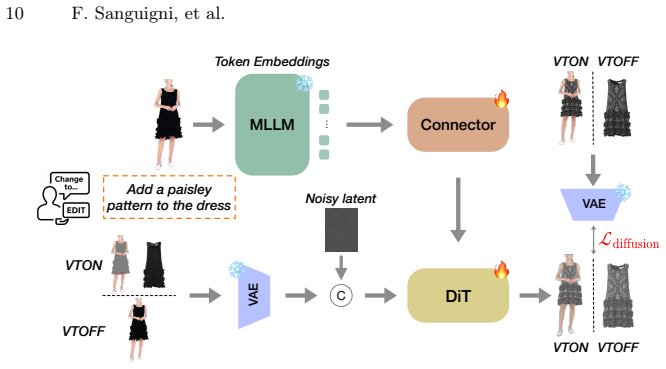
- The proposed multimodal diffusion baseline shows how linguistic instructions and visual garment cues can be jointly processed.
Where Pith is reading between the lines
- Interactive e-commerce tools could let users describe garment changes in plain language and see results immediately.
- Training on this dataset may improve a model's ability to handle unseen edit instructions if the automated creation process scales cleanly.
- Adding real-world user instructions as a test set would check whether models generalize beyond the generated data.
Load-bearing premise
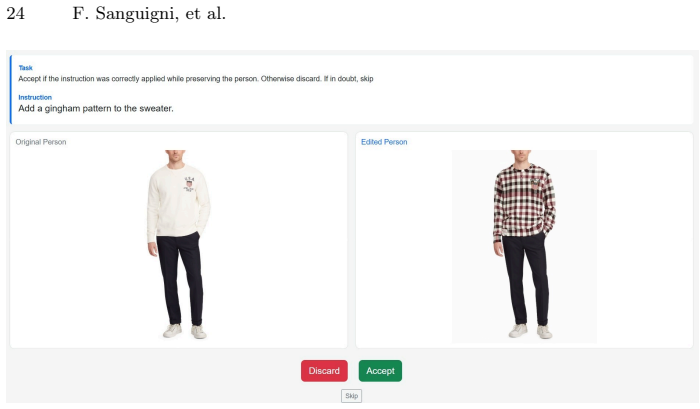
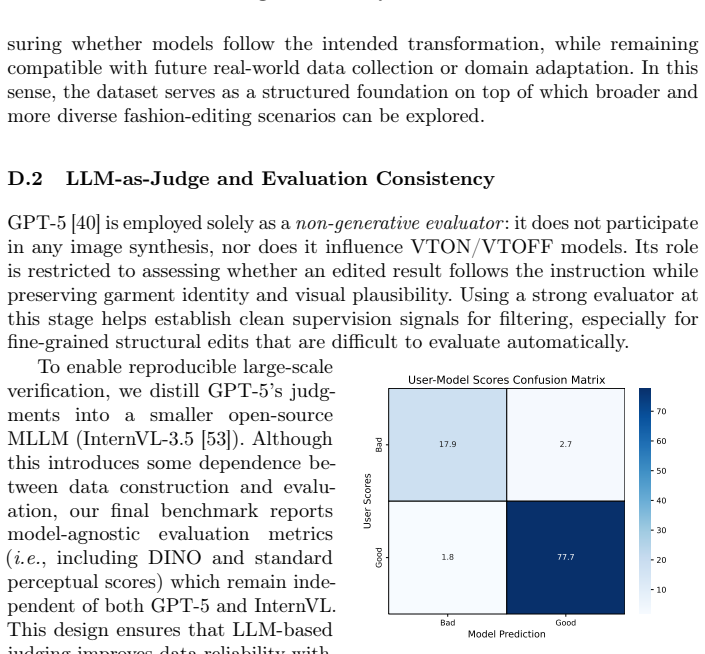
The fully automated multimodal pipeline integrating MLLM-based garment understanding, diffusion-based editing, and LLM-guided verification produces accurate, high-quality data without significant artifacts or verification errors.
What would settle it
A random sample of the released quadruplets in which the edited images fail to match the supplied instructions or contain visible artifacts would falsify the benchmark's claimed reliability.
Figures






read the original abstract
Recent advances in Virtual Try-On (VTON) and Virtual Try-Off (VTOFF) have greatly improved photo-realistic fashion synthesis and garment reconstruction. However, existing datasets remain static, lacking instruction-driven editing for controllable and interactive fashion generation. In this work, we introduce the Dress Editing Dataset (Dress-ED), the first large-scale benchmark that unifies VTON, VTOFF, and text-guided garment editing within a single framework. Each sample in Dress-ED includes an in-shop garment image, the corresponding person image wearing the garment, their edited counterparts, and a natural-language instruction of the desired modification. Built through a fully automated multimodal pipeline that integrates MLLM-based garment understanding, diffusion-based editing, and LLM-guided verification, Dress-ED comprises over 146k verified quadruplets spanning three garment categories and seven edit types, including both appearance (e.g., color, pattern, material) and structural (e.g., sleeve length, neckline) modifications. Based on this benchmark, we further propose a unified multimodal diffusion framework that jointly reasons over linguistic instructions and visual garment cues, serving as a strong baseline for instruction-driven VTON and VTOFF. Dataset and code will be made publicly available. Project page: https://furio1999.github.io/Dress-ED/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Dress Editing Dataset (Dress-ED), the first large-scale benchmark unifying VTON, VTOFF, and text-guided garment editing. Each of the >146k samples consists of an in-shop garment image, corresponding person image, edited counterparts, and a natural-language instruction. The dataset is built via a fully automated multimodal pipeline (MLLM garment understanding + diffusion editing + LLM-guided verification) spanning three garment categories and seven edit types (appearance and structural). A unified multimodal diffusion framework is proposed as a baseline for instruction-driven tasks.
Significance. If the automated pipeline produces high-quality, accurately labeled quadruplets at this scale, Dress-ED would provide the first unified benchmark for controllable, instruction-driven virtual try-on and try-off, enabling progress on interactive multimodal fashion synthesis models.
major comments (1)
- [Abstract and Dataset Construction] Abstract and Dataset Construction: the claim that the 146k quadruplets are 'verified' and high-quality rests entirely on the LLM-guided verification step correctly rejecting low-fidelity edits and instruction mismatches. No quantitative human evaluation (agreement rates, error rates on a sampled subset, or false-positive acceptance of artifacts) is reported to bound the reliability of this automated verification.
minor comments (1)
- [Abstract] The abstract states that dataset and code will be made publicly available but provides no details on release timeline, repository, or licensing.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that quantitative human validation would strengthen the claims about dataset quality and will incorporate the requested evaluation in the revision.
read point-by-point responses
-
Referee: [Abstract and Dataset Construction] Abstract and Dataset Construction: the claim that the 146k quadruplets are 'verified' and high-quality rests entirely on the LLM-guided verification step correctly rejecting low-fidelity edits and instruction mismatches. No quantitative human evaluation (agreement rates, error rates on a sampled subset, or false-positive acceptance of artifacts) is reported to bound the reliability of this automated verification.
Authors: We agree that the absence of quantitative human evaluation leaves the reliability of the LLM-guided verification step insufficiently bounded. In the revised manuscript we will add a dedicated subsection under Dataset Construction that reports a human study on a randomly sampled subset of 1,000 quadruplets. The study will include: (i) agreement rate between the LLM verifier and three independent human annotators, (ii) false-positive rate (human-accepted artifacts that the LLM incorrectly passed), and (iii) error rates stratified by edit type. We will also release the annotation protocol and sampled subset to allow reproducibility. This addition directly addresses the concern and provides empirical bounds on the automated pipeline's quality. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's contribution is empirical: it describes construction of the Dress-ED dataset via an automated pipeline (MLLM garment understanding + diffusion editing + LLM verification) and trains a baseline multimodal diffusion model. No mathematical derivations, equations, fitted parameters, or predictions appear in the provided text. The central claims rest on the pipeline's output of 146k quadruplets rather than any self-referential reduction, self-citation load-bearing premise, or renaming of known results. Any self-citations present are incidental and not required to justify the dataset's existence or the baseline's architecture by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pre-trained multimodal LLMs and diffusion models can reliably understand garments and generate accurate edits for verification
Reference graph
Works this paper leans on
-
[1]
AI, F.: Fashn human parser: Segformer for fashion human parsing (2024)
work page 2024
-
[2]
Avrahami, O., Patashnik, O., Fried, O., Nemchinov, E., Aberman, K., Lischinski, D., Cohen-Or, D.: Stable Flow: Vital Layers for Training-Free Image Editing. In: CVPR (2025)
work page 2025
-
[3]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Bai, S., Zhou, H., Li, Z., Zhou, C., Yang, H.: Single Stage Virtual Try-On Via Deformable Attention Flows. In: ECCV (2022)
work page 2022
-
[5]
Baldrati, A., Morelli, D., Cartella, G., Cornia, M., Bertini, M., Cucchiara, R.: Multimodal Garment Designer: Human-Centric Latent Diffusion Models for Fashion Image Editing. In: ICCV (2023)
work page 2023
-
[6]
Bińkowski, M., Sutherland, D.J., Arbel, M., Gretton, A.: Demystifying MMD GANs. arXiv preprint arXiv:1801.01401 (2018)
work page internal anchor Pith review arXiv 2018
-
[7]
Brooks, T., Holynski, A., Efros, A.A.: Instructpix2pix: Learning to follow image editing instructions. In: CVPR (2023)
work page 2023
-
[8]
Chen, C.Y., Chen, Y.C., Shuai, H.H., Cheng, W.H.: Size Does Matter: Size-aware Virtual Try-on via Clothing-oriented Transformation Try-on Network. In: ICCV (2023)
work page 2023
-
[9]
Choi, S., Park, S., Lee, M., Choo, J.: VITON-HD: High-Resolution Virtual Try-On via Misalignment-Aware Normalization. In: CVPR (2021)
work page 2021
-
[10]
Chong, Z., Dong, X., Li, H., Zhang, S., Zhang, W., Zhang, X., Zhao, H., Jiang, D., Liang, X.: CatVTON: Concatenation Is All You Need for Virtual Try-On with Diffusion Models. In: ICLR (2025)
work page 2025
-
[11]
Cui, A., Mahajan, J., Shah, V., Gomathinayagam, P., Liu, C., Lazebnik, S.: Street TryOn: Learning In-the-Wild Virtual Try-On from Unpaired Person Images. In: WACV (2024)
work page 2024
-
[12]
Cui, A., McKee, D., Lazebnik, S.: Dressing in Order: Recurrent Person Image Generation for Pose Transfer, Virtual Try-On and Outfit Editing. In: ICCV (2021)
work page 2021
-
[13]
Ding, K., Ma, K., Wang, S., Simoncelli, E.P.: Image Quality Assessment: Unifying Structure and Texture Similarity. IEEE Trans. PAMI44(5), 2567–2581 (2020)
work page 2020
-
[14]
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling Rectified Flow Transformers for High-Resolution Image Synthesis. In: ICML (2024)
work page 2024
-
[15]
Fele, B., Lampe, A., Peer, P., Struc, V.: C-VTON: Context-Driven Image-Based Virtual Try-On Network. In: WACV (2022)
work page 2022
-
[16]
Fu, T.J., Hu, W., Du, X., Wang, W.Y., Yang, Y., Gan, Z.: Guiding Instruction-based Image Editing via Multimodal Large Language Models. In: ICLR (2024)
work page 2024
-
[17]
Garibi, D., Patashnik, O., Voynov, A., Averbuch-Elor, H., Cohen-Or, D.: ReNoise: Real Image Inversion Through Iterative Noising. In: ECCV (2024)
work page 2024
-
[18]
Ge, Y., Zhang, R., Wang, X., Tang, X., Luo, P.: DeepFashion2: A Versatile Bench- mark for Detection, Pose Estimation, Segmentation and Re-Identification of Cloth- ing Images. In: CVPR (2019) 16 F. Sanguigni, et al
work page 2019
-
[19]
Girella, F., Talon, D., Liu, Z., Ruan, Z., Wang, Y., Cristani, M.: LOTS of Fashion! Multi-Conditioning for Image Generation via Sketch-Text Pairing. In: ICCV (2025)
work page 2025
-
[20]
Guo, H., Zeng, B., Song, Y., Zhang, W., Zhang, C., Liu, J.: Any2AnyTryon: Leveraging Adaptive Position Embeddings for Versatile Virtual Clothing Tasks. In: ICCV (2025)
work page 2025
-
[21]
Han, X., Wu, Z., Wu, Z., Yu, R., Davis, L.S.: VITON: An Image-Based Virtual Try-On Network. In: CVPR (2018)
work page 2018
-
[22]
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: LoRA: Low-Rank Adaptation of Large Language Models. In: ICLR (2022)
work page 2022
-
[23]
Huang, S., Li, H., Zheng, C., Ge, M., Gao, W., Wang, L., Liu, L.: Text-Driven Fashion Image Editing with Compositional Concept Learning and Counterfactual Abduction. In: CVPR (2025)
work page 2025
-
[24]
Hui, M., Yang, S., Zhao, B., Shi, Y., Wang, H., Wang, P., Zhou, Y., Xie, C.: HQ-Edit: A High-Quality Dataset for Instruction-based Image Editing. In: ICLR (2025)
work page 2025
-
[25]
Jiang, B., Hu, X., Luo, D., He, Q., Xu, C., Peng, J., Zhang, J., Wang, C., Wu, Y., Fu, Y.: FitDiT: Advancing the Authentic Garment Details for High-fidelity Virtual Try-on. In: CVPR (2025)
work page 2025
-
[26]
arXiv preprint arXiv:2504.13109 (2025)
Jiao, G., Huang, B., Wang, K.C., Liao, R.: UniEdit-Flow: Unleashing Inversion and Editing in the Era of Flow Models. arXiv preprint arXiv:2504.13109 (2025)
-
[27]
Khirodkar, R., Bagautdinov, T., Martinez, J., Zhaoen, S., James, A., Selednik, P., Anderson, S., Saito, S.: Sapiens: Foundation for human vision models. In: ECCV (2024)
work page 2024
-
[28]
Kim, J., Gu, G., Park, M., Park, S., Choo, J.: StableVITON: Learning Semantic Correspondence with Latent Diffusion Model for Virtual Try-On. In: CVPR (2024)
work page 2024
-
[29]
Labs, B.F.: FLUX.2: Frontier Visual Intelligence.https://bfl.ai/blog/flux-2 (2025)
work page 2025
-
[30]
arXiv preprint arXiv:2508.04825 (2025)
Lee, S., Kwak, J.g.: Voost: A Unified and Scalable Diffusion Transformer for Bidirectional Virtual Try-On and Try-Off. arXiv preprint arXiv:2508.04825 (2025)
-
[31]
arXiv preprint arXiv:2306.02928 (2023)
Lepage, S., Mary, J., Picard, D.: LRVS-Fashion: Extending Visual Search with Referring Instructions. arXiv preprint arXiv:2306.02928 (2023)
-
[32]
Li, Q., Qiu, S., Han, J., Xu, X., Seyfioglu, M.S., Koo, K.K., Bouyarmane, K.: DiT-VTON: Diffusion Transformer Framework for Unified Multi-Category Virtual Try-On and Virtual Try-All with Integrated Image Editing. In: CVPR Workshops (2025)
work page 2025
-
[33]
Li, Y., Zhou, H., Shang, W., Lin, R., Chen, X., Ni, B.: Anyfit: Controllable virtual try-on for any combination of attire across any scenario. In: NeurIPS (2024)
work page 2024
-
[34]
Liu, J., He, Z., Wang, G., Li, G., Lin, L.: One Model For All: Partial Diffusion for Unified Try-On and Try-Off in Any Pose. arXiv preprint arXiv:2508.04559 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Step1X-Edit: A Practical Framework for General Image Editing
Liu, S., Han, Y., Xing, P., Yin, F., Wang, R., Cheng, W., Liao, J., Wang, Y., Fu, H., Han, C., Li, G., Peng, Y., Sun, Q., Wu, J., Cai, Y., Ge, Z., Ming, R., Xia, L., Zeng, X., Zhu, Y., Jiao, B., Zhang, X., Yu, G., Jiang, D.: Step1x-edit: A practical framework for general image editing. arXiv preprint arXiv:2504.17761 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Lobba, D., Sanguigni, F., Ren, B., Cornia, M., Cucchiara, R., Sebe, N.: Inverse Virtual Try-On: Generating Multi-Category Product-Style Images from Clothed Individuals. In: ICLR (2026)
work page 2026
-
[37]
Loshchilov, I., Hutter, F.: Decoupled Weight Decay Regularization. In: ICLR (2019)
work page 2019
-
[38]
In: ACM Multimedia (2023) Dress-ED: Instruction-Guided Editing for Virtual Try-On and Try-Off 17
Morelli, D., Baldrati, A., Cartella, G., Cornia, M., Bertini, M., Cucchiara, R.: LaDI-VTON: Latent Diffusion Textual-Inversion Enhanced Virtual Try-On. In: ACM Multimedia (2023) Dress-ED: Instruction-Guided Editing for Virtual Try-On and Try-Off 17
work page 2023
-
[39]
Morelli, D., Matteo, F., Marcella, C., Federico, L., Fabio, C., Rita, C.: Dress Code: High-Resolution Multi-Category Virtual Try-On. In: ECCV (2022)
work page 2022
-
[40]
OpenAI: Introducing GPT-5 (2025)
work page 2025
-
[41]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: DINOv2: Learning Robust Visual Features without Supervision. arXiv preprint arXiv:2304.07193 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Parmar, G., Zhang, R., Zhu, J.Y.: On Aliased Resizing and Surprising Subtleties in GAN Evaluation. In: CVPR (2022)
work page 2022
-
[43]
Patel, M., Wen, S., Metaxas, D.N., Yang, Y.: Steering Rectified Flow Models in the Vector Field for Controlled Image Generation. In: ICCV (2025)
work page 2025
-
[44]
Pathiraja, B., Patel, M., Singh, S., Yang, Y., Baral, C.: Refedit: A benchmark and method for improving instruction-based image editing model on referring expressions. In: ICCV (2025)
work page 2025
-
[45]
Peebles, W., Xie, S.: Scalable Diffusion Models with Transformers. In: ICCV (2023)
work page 2023
-
[46]
Rajbhandari, S., Rasley, J., Ruwase, O., He, Y.: ZeRO: Memory Optimizations Toward Training Trillion Parameter Models. In: SC (2021)
work page 2021
-
[47]
Ren, B., Tang, H., Meng, F., Runwei, D., Torr, P.H., Sebe, N.: Cloth Interactive Transformer for Virtual Try-On. ACM TOMM20(4), 1–20 (2023)
work page 2023
-
[48]
Rout, L., Chen, Y., Ruiz, N., Caramanis, C., Shakkottai, S., Chu, W.S.: Semantic Image Inversion and Editing using Rectified Stochastic Differential Equations. In: ICLR (2025)
work page 2025
-
[49]
Sheynin, S., Polyak, A., Singer, U., Kirstain, Y., Zohar, A., Ashual, O., Parikh, D., Taigman, Y.: Emu edit: Precise image editing via recognition and generation tasks. In: CVPR (2025)
work page 2025
-
[50]
Velioglu, R., Bevandic, P., Chan, R., Hammer, B.: TryOffDiff: Virtual-Try-Off via High-Fidelity Garment Reconstruction using Diffusion Models. In: BMVC (2024)
work page 2024
-
[51]
Velioglu, R., Bevandic, P., Chan, R., Hammer, B.: MGT: Extending Virtual Try-Off to Multi-Garment Scenarios. In: ICCV Workshops (2025)
work page 2025
-
[52]
Wang, B., Zheng, H., Liang, X., Chen, Y., Lin, L., Yang, M.: Toward Characteristic- Preserving Image-based Virtual Try-On Network. In: ECCV (2018)
work page 2018
-
[53]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Wang, W., Gao, Z., Gu, L., Pu, H., Cui, L., Wei, X., Liu, Z., Jing, L., Ye, S., Shao, J., et al.: InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency. arXiv preprint arXiv:2508.18265 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE Trans. Image Processing13(4), 600–612 (2004)
work page 2004
-
[55]
Wei, C., Xiong, Z., Ren, W., Du, X., Zhang, G., Chen, W.: OmniEdit: Building Image Editing Generalist Models Through Specialist Supervision. In: ICLR (2025)
work page 2025
-
[56]
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., Yin, S.m., Bai, S., Xu, X., Chen, Y., et al.: Qwen-image technical report. arXiv preprint arXiv:2508.02324 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
arXiv preprint arXiv:2412.08573 (2024)
Xarchakos, I., Koukopoulos, T.: TryOffAnyone: Tiled Cloth Generation from a Dressed Person. arXiv preprint arXiv:2412.08573 (2024)
-
[58]
Xie, Z., Huang, Z., Dong, X., Zhao, F., Dong, H., Zhang, X., Zhu, F., Liang, X.: GP-VTON: Towards General Purpose Virtual Try-on via Collaborative Local-Flow Global-Parsing Learning. In: CVPR (2023)
work page 2023
-
[59]
Xie, Z., Li, H., Ding, H., Li, M., Cao, Y.: HieraFashDiff: Hierarchical Fashion Design with Multi-stage Diffusion Models. In: AAAI (2024)
work page 2024
-
[60]
Yan, K., Gao, T., Zhang, H., Xie, C.: Linking garment with person via semantically associated landmarks for virtual try-on. In: CVPR (2023) 18 F. Sanguigni, et al
work page 2023
-
[61]
Yang,L.,Zeng,B.,Liu,J.,Li,H.,Xu,M.,Zhang,W.,Yan,S.:EditWorld:Simulating World Dynamics for Instruction-Following Image Editing. In: ACM Multimedia (2024)
work page 2024
-
[62]
Yang, S., Hui, M., Zhao, B., Zhou, Y., Ruiz, N., Xie, C.: Complex-Edit: CoT-Like Instruction Generation for Complexity-Controllable Image Editing Benchmark. arXiv preprint arXiv:2504.13143 (2025)
-
[63]
Ye, Y., He, X., Li, Z., Lin, B., Yuan, S., Yan, Z., Hou, B., Yuan, L.: Imgedit: A unified image editing dataset and benchmark. In: NeurIPS (2025)
work page 2025
-
[64]
Yin, D., Guo, J., Lu, H., Wu, F., Lu, D.: EditGarment: An Instruction-Based Garment Editing Dataset Constructed with Automated MLLM Synthesis and Semantic-Aware Evaluation. In: ACM Multimedia (2025)
work page 2025
-
[65]
Yu, Q., Chow, W., Yue, Z., Pan, K., Wu, Y., Wan, X., Li, J., Tang, S., Zhang, H., Zhuang, Y.: Anyedit: Mastering unified high-quality image editing for any idea. In: CVPR (2025)
work page 2025
-
[66]
Zhang, K., Mo, L., Chen, W., Sun, H., Su, Y.: Magicbrush: A manually annotated dataset for instruction-guided image editing. In: NeurIPS (2023)
work page 2023
-
[67]
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: CVPR (2018)
work page 2018
-
[68]
Zhang, S., Yang, X., Feng, Y., Qin, C., Chen, C.C., Yu, N., Chen, Z., Wang, H., Savarese, S., Ermon, S., et al.: HIVE: Harnessing Human Feedback for Instructional Visual Editing. In: CVPR (2024)
work page 2024
-
[69]
Zhao, H., Ma, X.S., Chen, L., Si, S., Wu, R., An, K., Yu, P., Zhang, M., Li, Q., Chang, B.: Ultraedit: Instruction-based fine-grained image editing at scale. In: NeurIPS (2024)
work page 2024
-
[70]
Zhou, Z., Liu, S., Han, X., Liu, H., Ng, K.W., Xie, T., Cong, Y., Li, H., Xu, M., Pérez-Rúa, J.M., Patel, A., Xiang, T., Shi, M., He, S.: Learning Flow Fields in Attention for Controllable Person Image Generation. In: CVPR (2025)
work page 2025
-
[71]
Zhu, L., Li, Y., Liu, N., Peng, H., Yang, D., Kemelmacher-Shlizerman, I.: M&m vto: Multi-garment virtual try-on and editing. In: CVPR (2024)
work page 2024
-
[72]
Change the color of the garment to[Target Color]
Zhu, L., Yang, D., Zhu, T., Reda, F., Chan, W., Saharia, C., Norouzi, M., Kemelmacher-Shlizerman, I.: TryOnDiffusion: A Tale of Two UNets. In: CVPR (2023) Dress-ED: Instruction-Guided Editing for Virtual Try-On and Try-Off 19 A Additional Implementation Details Training Configuration.During training, we employ DeepSpeed [46] for mem- ory optimization and ...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.