Recognition: no theorem link
UnWeaving the knots of GraphRAG -- turns out VectorRAG is almost enough
Pith reviewed 2026-05-16 06:55 UTC · model grok-4.3
The pith
Entity decomposition of documents into cross-chunk links simplifies GraphRAG to near VectorRAG performance while preserving source fidelity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
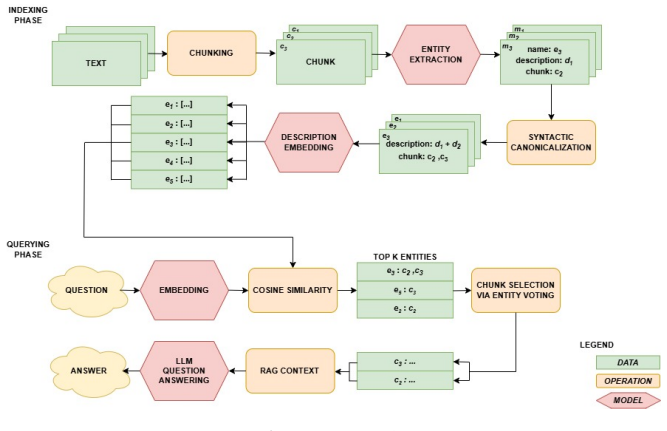
UnWeaver disentangles document contents into entities that span multiple chunks via LLM extraction. These entities serve as an intermediate layer that recovers the original source chunks during retrieval, thereby preserving fidelity to the raw text. The central claim is that this entity-based decomposition yields a more distilled representation of the original information and reduces noise in both the indexing and generation stages, making the approach simpler than full GraphRAG yet more capable than standard chunk-based VectorRAG for multi-hop questions.
What carries the argument
LLM-driven entity extraction that treats entities as bridges across chunks, enabling retrieval of original text without constructing a full knowledge graph or community hierarchy.
If this is right
- Retrieval remains tied to original source chunks, avoiding the information loss that occurs when answers are generated solely from graph summaries.
- Indexing complexity drops because full graph construction and community detection are skipped in favor of per-entity extraction.
- Noise in generation decreases because retrieved content is filtered through entity matches rather than whole-chunk vectors.
- Multi-hop questions can be handled by traversing entity co-occurrences without needing explicit relation edges or heuristics.
Where Pith is reading between the lines
- If entity linking alone captures most multi-hop structure, many existing vector indexes could be retrofitted with lightweight entity layers instead of rebuilt as graphs.
- The same decomposition might apply to domains outside RAG, such as summarization pipelines that need to track repeated entities across long documents.
- Verification steps on extracted entities could be added as a low-cost safeguard, turning the weakest assumption into a measurable accuracy target.
Load-bearing premise
An LLM can extract entities from chunks reliably enough that errors or hallucinations do not systematically degrade later retrieval and generation steps.
What would settle it
A controlled comparison on multi-hop question datasets where UnWeaver's entity extraction step is replaced by perfect oracle entities; if performance does not improve markedly over standard VectorRAG, the distillation benefit would be falsified.
Figures
read the original abstract
One of the key problems in Retrieval-augmented generation (RAG) systems is that chunk-based retrieval pipelines represent the source chunks as atomic objects, mixing the information contained within such a chunk into a single vector. These vector representations are then fundamentally treated as isolated, independent and self-sufficient, with no attempt to represent possible relations between them. Such an approach has no dedicated mechanisms for handling multi-hop questions. Graph-based RAG systems aimed to ameliorate this problem by modeling information as knowledge-graphs, with entities represented by nodes being connected by robust relations, and forming hierarchical communities. This approach however suffers from its own issues with some of them being: orders of magnitude increased componential complexity in order to create graph-based indices, and reliance on heuristics for performing retrieval. We propose UnWeaver, a novel RAG framework simplifying the idea of GraphRAG. UnWeaver disentangles the contents of the documents into entities which can occur across multiple chunks using an LLM. In the retrieval process entities are used as an intermediate way of recovering original text chunks hence preserving fidelity to the source material. We argue that entity-based decomposition yields a more distilled representation of original information, and additionally serves to reduce noise in the indexing, and generation process.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes UnWeaver, a simplified RAG framework that uses an LLM to extract entities spanning multiple chunks from source documents. These entities act as intermediaries to retrieve the original text chunks at query time, aiming to reduce the complexity of GraphRAG while providing a more distilled representation that reduces noise in indexing and generation and better supports multi-hop questions than standard VectorRAG.
Significance. If empirically validated, the approach could offer a practical middle ground between lightweight VectorRAG and heavyweight GraphRAG pipelines by leveraging entity-mediated retrieval to improve fidelity and noise characteristics without requiring full knowledge-graph construction or community detection.
major comments (2)
- [Abstract] Abstract: the design and intended benefits are stated, but the manuscript supplies no quantitative results, ablation studies, retrieval metrics, or error analysis to verify whether entity-based decomposition actually reduces noise or improves multi-hop performance over VectorRAG.
- [Abstract] Abstract: the central claim that entity extraction yields a distilled representation and reduces noise rests on the untested premise that LLM entity extraction across chunks is reliable and does not introduce systematic hallucinations or omissions; no extraction-precision benchmarks, hallucination rates, or end-to-end comparisons are referenced.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the opportunity to clarify the contributions of UnWeaver. We address each major comment below and commit to strengthening the empirical grounding of the work.
read point-by-point responses
-
Referee: [Abstract] Abstract: the design and intended benefits are stated, but the manuscript supplies no quantitative results, ablation studies, retrieval metrics, or error analysis to verify whether entity-based decomposition actually reduces noise or improves multi-hop performance over VectorRAG.
Authors: We acknowledge that the submitted manuscript presents the UnWeaver framework conceptually and does not yet contain quantitative experiments, ablation studies, or retrieval metrics. This is a fair observation. In the revised version we will add a dedicated experimental section that reports standard retrieval metrics (recall@K, nDCG), multi-hop QA accuracy on established benchmarks, direct comparisons against VectorRAG and GraphRAG baselines, and an error analysis quantifying noise reduction attributable to entity-mediated retrieval. revision: yes
-
Referee: [Abstract] Abstract: the central claim that entity extraction yields a distilled representation and reduces noise rests on the untested premise that LLM entity extraction across chunks is reliable and does not introduce systematic hallucinations or omissions; no extraction-precision benchmarks, hallucination rates, or end-to-end comparisons are referenced.
Authors: We agree that the reliability of cross-chunk LLM entity extraction is a foundational assumption that must be validated. The revised manuscript will include dedicated extraction-quality experiments: precision/recall/F1 against human-annotated entity spans, measured hallucination and omission rates, and an ablation that isolates the effect of extraction errors on downstream retrieval fidelity and generation quality. revision: yes
Circularity Check
No significant circularity: framework proposal is self-contained argument without self-referential reduction
full rationale
The paper proposes UnWeaver as a simplification of GraphRAG that uses LLM entity extraction to create an intermediate representation for chunk retrieval. The central claim that entity-based decomposition yields a more distilled representation and reduces noise is presented as a direct design argument in the abstract and introduction, with no equations, fitted parameters renamed as predictions, or load-bearing self-citations that reduce the result to its own inputs by construction. No uniqueness theorems, ansatzes smuggled via prior work, or renaming of known results appear in the provided text. The assumption about LLM extraction reliability is stated explicitly as a premise rather than derived circularly from the system's outputs, leaving the derivation chain independent of self-reference.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM-based entity extraction across chunks is accurate and does not introduce systematic hallucinations or omissions
invented entities (1)
-
UnWeaver framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Adi Ben-Israel and Thomas NE Greville.Gener- alized inverses: theory and applications. Springer, 2003
work page 2003
-
[2]
Cambridge university press, 2018
Stephen Boyd and Lieven Vandenberghe.Intro- duction to applied linear algebra: vectors, ma- trices, and least squares. Cambridge university press, 2018
work page 2018
-
[3]
ZuzannaDubanowska, MaciejŻelaszczyk, Michał Brzozowski, Paolo Mandica, and Michal P. Kar- powicz. Representation-based broad hallucina- tion detectors fail to generalize out of distribution. InEMNLP 2025. ACL, August 2025
work page 2025
-
[4]
From local to global: A graph rag approach to query-focused summariza- tion, 2025
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. From local to global: A graph rag approach to query-focused summariza- tion, 2025. URLhttps://arxiv.org/abs/2404. 16130
work page 2025
-
[5]
Ragas: Automated Evaluation of Retrieval Augmented Generation
Shahul Es, Jithin James, Luis Espinosa-Anke, and Steven Schockaert. Ragas: Automated eval- uation of retrieval augmented generation, 2025. URLhttps://arxiv.org/abs/2309.15217
work page internal anchor Pith review arXiv 2025
-
[6]
Robert Friel, Masha Belyi, and Atindriyo Sanyal. Ragbench: Explainable benchmark for retrieval- augmented generation systems, 2025. URL https://arxiv.org/abs/2407.11005
-
[7]
Haoyu Han, Yu Wang, Harry Shomer, Kai Guo, Jiayuan Ding, Yongjia Lei, Mahantesh Halap- panavar, Ryan A. Rossi, Subhabrata Mukherjee, Xianfeng Tang, Qi He, Zhigang Hua, Bo Long, Tong Zhao, Neil Shah, Amin Javari, Yinglong Xia, and Jiliang Tang. Retrieval-augmented generation with graphs (graphrag), 2025. URL https://arxiv.org/abs/2501.00309
-
[8]
Sufficient context: A new lens on retrieval augmented generation systems, 2025
Hailey Joren, Jianyi Zhang, Chun-Sung Ferng, Da-Cheng Juan, Ankur Taly, and Cyrus Rashtchian. Sufficient context: A new lens on retrieval augmented generation systems, 2025. URLhttps://arxiv.org/abs/2411.06037
- [9]
- [10]
- [11]
- [12]
- [13]
-
[14]
Frank P Kelly, Aman K Maulloo, and David Kim Hong Tan. Rate control for communication networks: shadow prices, proportional fairness and stability.Journal of the Operational Research society, 49(3):237–252, 1998
work page 1998
-
[15]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Patrick Lewis, Ethan Perez, Aleksandra Pik- tus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive nlp tasks, 2021. URL https://arxiv.org/abs/2005.11401
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[16]
Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher D. Manning. Raptor: Recursive abstractive pro- cessing for tree-organized retrieval, 2024. URL https://arxiv.org/abs/2401.18059. 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Retrieval augmentation reduces hallucination in conversation, 2021
Kurt Shuster, Spencer Poff, Moya Chen, Douwe Kiela, and Jason Weston. Retrieval augmentation reduces hallucination in conversation, 2021. URL https://arxiv.org/abs/2104.07567. 8 A Mathematics of UnWeaver and Beyond LetT= [T 1|···|TK]be a document decomposed intoK chunks by a tokenizer. From each chunki = 1,...,K an LLM extracts a list ofn names of entitie...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.