Robust LLM Performance Certification via Constrained Maximum Likelihood Estimation
Pith reviewed 2026-05-15 12:36 UTC · model grok-4.3
The pith
Constrained maximum likelihood estimation combines human labels, LLM judge annotations, and performance bounds to estimate LLM failure rates more accurately and with lower variance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
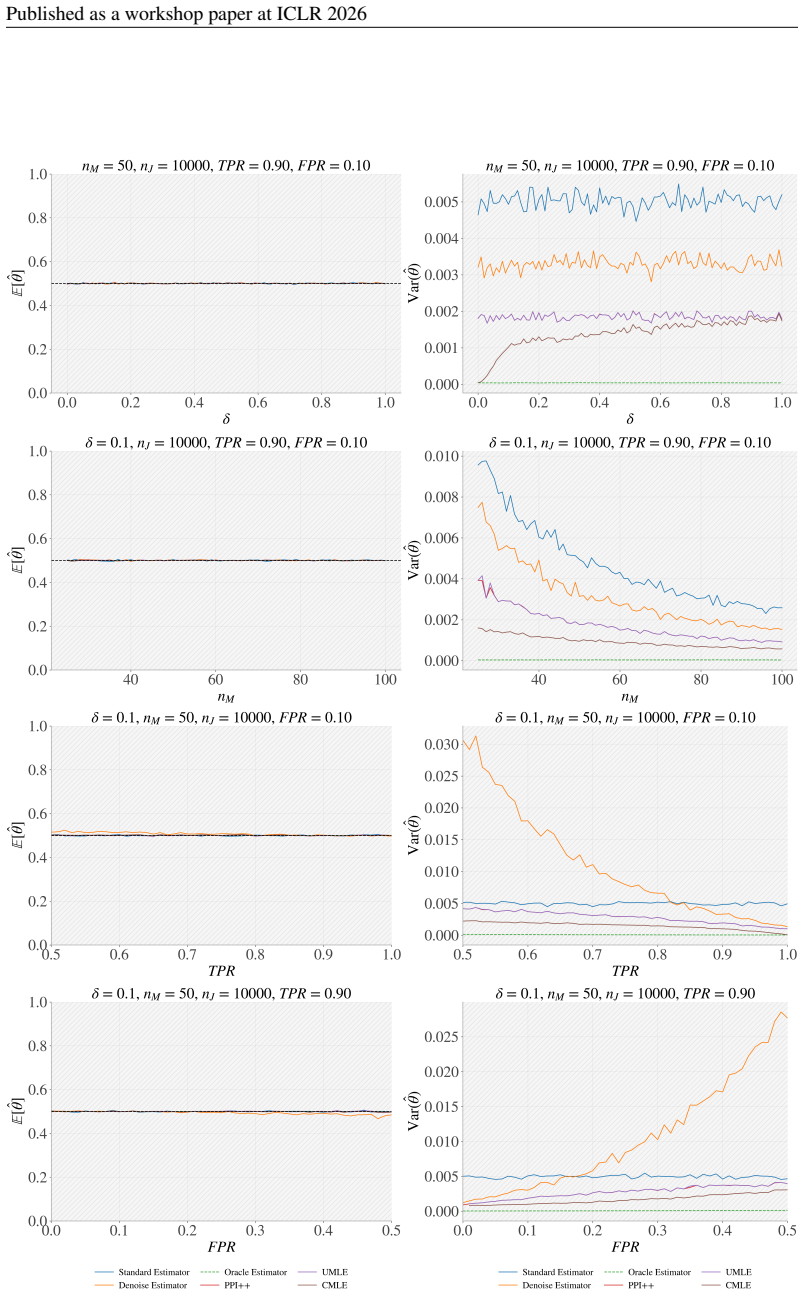
The paper establishes that integrating domain-specific constraints from judge performance statistics into maximum likelihood estimation produces LLM failure rate estimates that are more accurate and have lower variance than those from existing methods across regimes with different judge accuracies, calibration set sizes, and failure rates.
What carries the argument
Constrained maximum likelihood estimation fusing a human calibration set, LLM-judge annotations, and side information from bounds on judge performance statistics.
If this is right
- Provides a practical way to estimate LLM failure rates without full human labeling.
- Delivers estimates with improved accuracy and reduced variance in diverse settings.
- Enables a scalable pathway for LLM performance certification.
- Offers an interpretable alternative to black-box use of automated judges.
Where Pith is reading between the lines
- Similar constrained estimation could apply to other LLM metrics if suitable performance bounds are available.
- The method suggests domain knowledge can systematically improve statistical estimators in certification tasks.
- In deployment, this could allow smaller calibration sets while preserving reliability.
- Extensions might adapt the constraints dynamically for different judge models or tasks.
Load-bearing premise
The domain-specific constraints derived from known bounds on judge performance statistics are accurate, applicable to the judges in use, and do not introduce bias into the MLE optimization.
What would settle it
Compare the constrained MLE estimates against exhaustive human annotations on a held-out test set with known true failure rates; if the estimates show no improvement in accuracy or variance over baselines under the same conditions, the central claim would be falsified.
Figures












read the original abstract
The ability to rigorously estimate the failure rates of large language models (LLMs) is a prerequisite for their safe deployment. Currently, however, practitioners often face a tradeoff between expensive human gold standards and potentially severely-biased automatic annotation schemes such as "LLM-as-a-Judge" labeling. In this paper, we propose a new, practical, and efficient approach to LLM failure rate estimation based on constrained maximum-likelihood estimation (MLE). Our method integrates three distinct signal sources: (i) a small, high-quality human-labeled calibration set, (ii) a large corpus of LLM-judge annotations, and, most importantly, (iii) additional side information via domain-specific constraints derived from known bounds on judge performance statistics. We validate our approach through a comprehensive empirical study, benchmarking it against state-of-the-art baselines like Prediction-Powered Inference (PPI). Across diverse experimental regimes -- spanning varying judge accuracies, calibration set sizes, and LLM failure rates -- our constrained MLE consistently delivers more accurate and lower-variance estimates than existing methods. By moving beyond the "black-box" use of automated judges to a flexible framework, we provide a principled, interpretable, and scalable pathway towards LLM failure-rate certification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a constrained maximum-likelihood estimation (MLE) framework for estimating LLM failure rates. It combines a small human-labeled calibration set, large-scale LLM-as-a-judge annotations, and domain-specific constraints derived from known bounds on judge performance statistics. The central empirical claim is that this approach yields more accurate and lower-variance failure-rate estimates than baselines such as Prediction-Powered Inference (PPI) across regimes varying in judge accuracy, calibration-set size, and failure rates.
Significance. If the constraints prove valid and non-biased for the judges and tasks considered, the method offers a practical route to more reliable LLM performance certification with reduced human annotation costs. The integration of side information via constraints is a clear strength relative to purely data-driven estimators.
major comments (2)
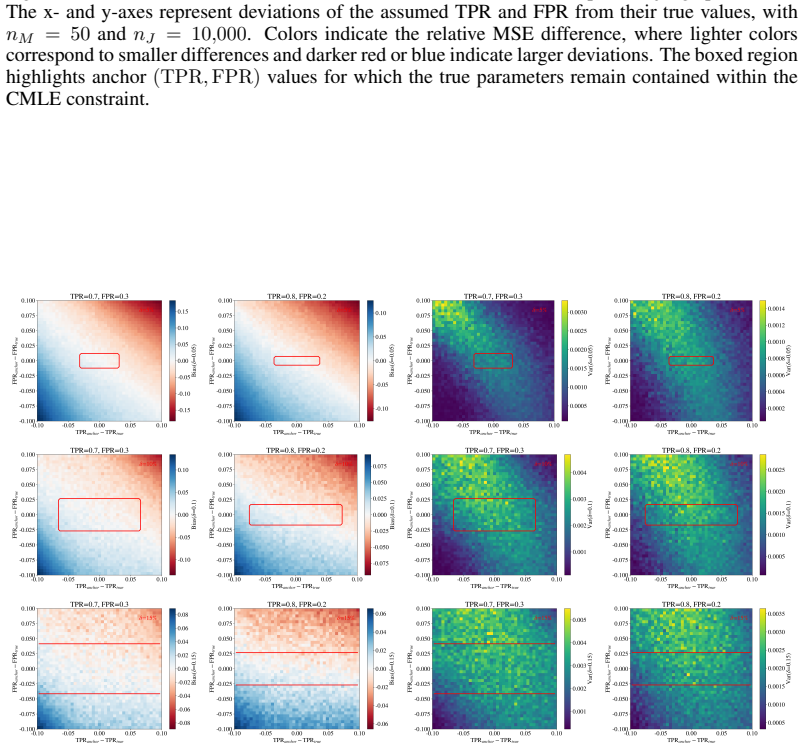
- [Method and Experiments] The central claim that the constrained MLE is unbiased and lower-variance rests on the assumption that the domain-specific bounds on judge performance statistics are both accurate for the judges in use and not violated by the calibration data. The manuscript should include explicit checks (e.g., empirical violation rates or sensitivity plots over bound values) in the experimental section to confirm this; without them the reported gains may be artifacts of constraint misspecification.
- [§3 (Constrained MLE formulation)] The abstract and method description treat the judge-performance bounds as external inputs, yet no derivation or validation is provided showing that these bounds remain tight enough to meaningfully constrain the MLE optimization in the tested failure-rate regimes. A concrete comparison of the constrained versus unconstrained MLE variance (with the same calibration set) would strengthen the lower-variance claim.
minor comments (2)
- [§3] Notation for the constraint functions and the MLE objective should be introduced with explicit definitions before the optimization is stated.
- [Experiments] Figure captions for the empirical results should report the exact number of trials and seed values used to compute the reported means and variances.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We agree that additional validation of the constraints will strengthen the paper and have revised the manuscript to incorporate explicit checks and comparisons as suggested. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Method and Experiments] The central claim that the constrained MLE is unbiased and lower-variance rests on the assumption that the domain-specific bounds on judge performance statistics are both accurate for the judges in use and not violated by the calibration data. The manuscript should include explicit checks (e.g., empirical violation rates or sensitivity plots over bound values) in the experimental section to confirm this; without them the reported gains may be artifacts of constraint misspecification.
Authors: We agree that validating the constraints is important for supporting the central claims. In the revised manuscript we have added a dedicated subsection to the experimental results that reports empirical violation rates of the bounds across all tested regimes (judge accuracy, calibration size, and failure rate) and includes sensitivity plots that perturb the bound values by up to 15%. These additions confirm that the bounds are respected in the evaluated settings and that the reported accuracy and variance improvements remain stable under moderate bound misspecification. revision: yes
-
Referee: [§3 (Constrained MLE formulation)] The abstract and method description treat the judge-performance bounds as external inputs, yet no derivation or validation is provided showing that these bounds remain tight enough to meaningfully constrain the MLE optimization in the tested failure-rate regimes. A concrete comparison of the constrained versus unconstrained MLE variance (with the same calibration set) would strengthen the lower-variance claim.
Authors: We appreciate the suggestion to make the role of the bounds more explicit. The revised Section 3 now contains a short derivation showing how the domain-specific bounds on judge statistics translate into feasible regions for the MLE parameters and why they remain non-vacuous in the failure-rate regimes examined. We have also added an ablation experiment that directly compares the variance of the constrained MLE estimator against its unconstrained counterpart on identical calibration sets; the results quantify a consistent variance reduction attributable to the constraints while preserving unbiasedness. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper's core method combines a human calibration set, LLM-judge annotations, and external domain-specific constraints derived from known bounds on judge performance statistics. These constraints are treated as independent side information rather than fitted parameters or self-referential definitions. No equations reduce the estimator to its inputs by construction, no self-citations form load-bearing uniqueness claims, and empirical validation against PPI baselines remains independent of the target estimates. The derivation is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Known bounds on judge performance statistics are accurate and transferable to the specific judges and tasks under study
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
constrained maximum-likelihood estimation (CMLE) ... domain-specific constraints derived from known bounds on judge performance statistics (TPR, FPR)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
projected gradient ascent ... Π[0,1] and interval projections on TPR/FPR
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[3]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[4]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.