Multilingual Language Models Encode Script Over Linguistic Structure
Pith reviewed 2026-05-10 18:58 UTC · model grok-4.3
The pith
Multilingual language models organize their internal representations around surface script and orthography rather than abstract linguistic structure.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
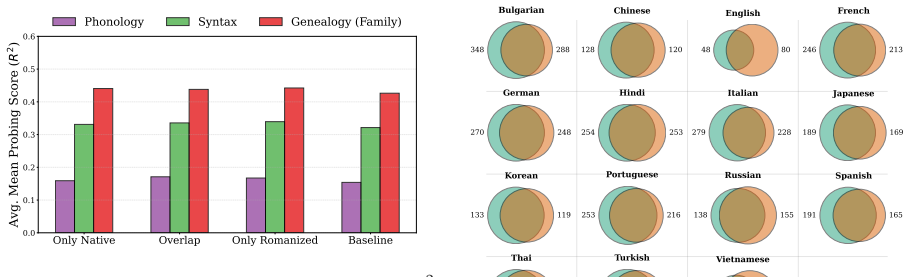
Multilingual LMs organize representations around surface form, with linguistic abstraction emerging gradually without collapsing into a unified interlingua. Language-associated units are strongly conditioned on orthography: romanization induces near-disjoint representations that align with neither native-script inputs nor English, while word-order shuffling has limited effect on unit identity. Probing shows typological structure becomes increasingly accessible in deeper layers, while causal interventions indicate generation is most sensitive to units invariant to surface-form perturbations.
What carries the argument
The Language Activation Probability Entropy (LAPE) metric that scores how selectively units activate for particular languages, together with sparse autoencoder decompositions that isolate distinct activation patterns.
Load-bearing premise
The LAPE metric and sparse autoencoder decompositions accurately isolate orthographic effects from linguistic structure without introducing analysis artifacts, and the chosen perturbations separate surface form from deeper linguistic properties.
What would settle it
Finding that romanized inputs activate the same units as native-script versions or that word-order shuffling substantially alters unit identities would falsify the claim that surface form dominates representation organization.
Figures


























read the original abstract
Multilingual language models (LMs) organize representations for typologically and orthographically diverse languages into a shared parameter space, yet the nature of this internal organization remains elusive. In this work, we investigate which linguistic properties - abstract language identity or surface-form cues - shape multilingual representations. To do so, we analyze language-associated units across different model families and scales using the Language Activation Probability Entropy (LAPE) metric, and further decompose activations with Sparse Autoencoders. We find that these units are strongly conditioned on orthography: romanization induces near-disjoint representations that align with neither native-script inputs nor English, while word-order shuffling has limited effect on unit identity. Probing shows that typological structure becomes increasingly accessible in deeper layers, while causal interventions indicate that generation is most sensitive to units that are invariant to surface-form perturbations rather than to units identified by typological alignment alone. Overall, our results suggest that multilingual LMs organize representations around surface form, with linguistic abstraction emerging gradually without collapsing into a unified interlingua.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that multilingual language models organize internal representations primarily around surface-form cues such as orthography and script rather than abstract linguistic structure or a unified interlingua. Using the Language Activation Probability Entropy (LAPE) metric to identify language-associated units, sparse autoencoder decompositions, probing for typological features, and causal interventions, the authors show that romanization produces near-disjoint representations aligning with neither native-script nor English inputs, while word-order shuffling has limited effect. Typological structure becomes more accessible in deeper layers, and generation is most sensitive to surface-invariant units.
Significance. If the results hold after addressing potential confounds, this would meaningfully advance understanding of multilingual representation geometry by demonstrating that surface form dominates over linguistic abstraction. The multi-method design (LAPE, SAEs, probing, interventions) across model families and scales, combined with falsifiable perturbation tests, provides a solid empirical foundation and credit for using defined metrics rather than purely correlational analysis.
major comments (3)
- [§4] §4 (Romanization and word-order perturbation results): The central claim that language-associated units (via LAPE) are conditioned on orthography rests on romanization producing disjoint representations. However, since multilingual LMs use BPE-style subword tokenizers, romanization alters token boundaries and vocabulary overlap independently of script. Without controls comparing to tokenization-preserving script changes or tokenizer-matched baselines, this risks confounding orthographic encoding with tokenizer artifacts, weakening the evidence that representations organize around surface form over linguistic structure.
- [§3.2 and §5] §3.2 and §5 (LAPE metric and SAE decompositions): The assumption that LAPE and SAE features cleanly isolate orthographic effects from analysis artifacts is load-bearing for the claim of script-over-linguistic organization. The manuscript provides limited validation (e.g., no hyperparameter ablations for SAEs or checks that LAPE units are not proxying token identity), so it remains possible that the observed conditioning reflects tokenizer behavior rather than model-internal script encoding.
- [§6] §6 (Causal interventions): The finding that generation is most sensitive to surface-invariant units (rather than typologically aligned ones) requires more detail on intervention implementation, baseline comparisons, and statistical tests. Without these, it is unclear whether the differential sensitivity securely supports the gradual-emergence conclusion over alternative explanations.
minor comments (3)
- [§3] The LAPE definition and computation details (e.g., exact probability estimation across languages) could be expanded in §3 for reproducibility.
- [Figures] Figures showing representation overlaps or LAPE distributions would benefit from explicit legends, error bars, and statistical annotations.
- [Related Work] Add discussion of related work on tokenization effects in multilingual models to better contextualize the romanization results.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify potential confounds and strengthen the empirical claims. We address each major point below. Where revisions are needed, we have incorporated additional controls, ablations, and details into the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (Romanization and word-order perturbation results): The central claim that language-associated units (via LAPE) are conditioned on orthography rests on romanization producing disjoint representations. However, since multilingual LMs use BPE-style subword tokenizers, romanization alters token boundaries and vocabulary overlap independently of script. Without controls comparing to tokenization-preserving script changes or tokenizer-matched baselines, this risks confounding orthographic encoding with tokenizer artifacts, weakening the evidence that representations organize around surface form over linguistic structure.
Authors: We agree that tokenizer effects are an important consideration. Our word-order shuffling experiments hold tokenization fixed while disrupting linguistic structure and produce only limited changes to LAPE units, indicating that the romanization effect is not reducible to token-boundary shifts alone. We also compare romanized inputs against English (same script family, different language) and observe disjoint units. In the revision we add an explicit tokenizer-matched baseline (using a fixed BPE vocabulary across scripts where feasible) and a transliteration control that minimizes token-boundary changes. These additions reinforce that orthography shapes unit identity beyond tokenizer artifacts. revision: yes
-
Referee: [§3.2 and §5] §3.2 and §5 (LAPE metric and SAE decompositions): The assumption that LAPE and SAE features cleanly isolate orthographic effects from analysis artifacts is load-bearing for the claim of script-over-linguistic organization. The manuscript provides limited validation (e.g., no hyperparameter ablations for SAEs or checks that LAPE units are not proxying token identity), so it remains possible that the observed conditioning reflects tokenizer behavior rather than model-internal script encoding.
Authors: We acknowledge the need for stronger validation. LAPE is defined on activation probabilities across languages and therefore does not directly encode token identity; however, we will add explicit checks showing that the same LAPE units remain stable under different tokenizations of the same script. For SAEs we will include hyperparameter ablations (dictionary size, sparsity coefficient) and report reconstruction fidelity across settings. These additions will be placed in §3.2 and §5 to demonstrate that the observed script conditioning is not an artifact of the analysis pipeline. revision: yes
-
Referee: [§6] §6 (Causal interventions): The finding that generation is most sensitive to surface-invariant units (rather than typologically aligned ones) requires more detail on intervention implementation, baseline comparisons, and statistical tests. Without these, it is unclear whether the differential sensitivity securely supports the gradual-emergence conclusion over alternative explanations.
Authors: We agree that additional methodological detail is warranted. In the revised §6 we expand the intervention protocol to specify exactly how units are masked or activated (including the precise activation threshold and layer range), add baseline comparisons (random unit interventions and typological-unit controls), and report statistical tests (paired t-tests with effect sizes and p-values) on the generation-sensitivity differences. These clarifications will better isolate the contribution of surface-invariant units and support the gradual-emergence interpretation. revision: yes
Circularity Check
No circularity: empirical measurements and interventions form an independent chain
full rationale
The paper defines LAPE as a metric on activation probabilities, applies it to locate language-associated units, then measures the effects of explicit perturbations (romanization, word-order shuffle) and SAE decompositions on those units. Probing and causal interventions are performed on the resulting representations. None of these steps reduce a claimed result to a fitted parameter or self-referential definition; the conclusions follow from observed differences between conditions rather than from any equation or prior self-citation that encodes the target finding by construction. The analysis is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LAPE metric accurately reflects language-specific unit activation without metric-specific artifacts
- domain assumption Sparse autoencoders decompose activations into interpretable units
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Language-associated units are strongly conditioned on orthography: romanization induces near-disjoint representations... while word-order shuffling has limited effect on unit identity.
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Typological structure becomes increasingly accessible in deeper layers... causal interventions indicate that generation is most sensitive to units that are invariant to surface-form perturbations
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Sparse autoencoders can capture language-specific concepts across diverse languages, 2025
Sparse autoencoders can capture language- specific concepts across diverse languages.Preprint, arXiv:2507.11230. Mikel Artetxe, Sebastian Ruder, and Dani Yogatama
-
[2]
On the cross-lingual transferability of mono- lingual representations. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4623–4637, Online. Association for Computational Linguistics. David Bau, Bolei Zhou, Aditya Khosla, Aude Oliva, and Antonio Torralba. 2017. Network dissection: Quanti- fying interpretabilit...
work page 2017
-
[3]
Albert Costa and Núria Sebastián-Gallés
Identifying bilingual semantic neural represen- tations across languages.Brain Lang, 120(3):282– 289. Albert Costa and Núria Sebastián-Gallés. 2014. How does the bilingual experience sculpt the brain?Nat Rev Neurosci, 15(5):336–345. D. Crystal. 2003.English as a Global Language. Canto (Cambridge University Press). Cambridge University Press. Boyi Deng, Yu...
work page 2014
-
[4]
The llama 3 herd of models.Preprint, arXiv:2407.21783. Daniil Gurgurov, Katharina Trinley, Yusser Al Ghussin, Tanja Baeumel, Josef Van Genabith, and Simon Os- termann. 2025. Language arithmetics: Towards sys- tematic language neuron identification and manip- ulation. InProceedings of the 14th International Joint Conference on Natural Language Processing a...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
InFindings of the Associ- ation for Computational Linguistics: EMNLP 2020, pages 1663–1674, Online
On the language neutrality of pre-trained mul- tilingual representations. InFindings of the Associ- ation for Computational Linguistics: EMNLP 2020, pages 1663–1674, Online. Association for Computa- tional Linguistics. Jindˇrich Libovický, Rudolf Rosa, and Alexander Fraser
work page 2020
-
[6]
How language-neutral is multilingual bert? Preprint, arXiv:1911.03310. Tom Lieberum, Senthooran Rajamanoharan, Arthur Conmy, Lewis Smith, Nicolas Sonnerat, Vikrant Varma, Janos Kramar, Anca Dragan, Rohin Shah, and Neel Nanda. 2024. Gemma scope: Open sparse autoencoders everywhere all at once on gemma 2. InProceedings of the 7th BlackboxNLP Workshop: Analy...
-
[7]
Samuel Marks, Can Rager, Eric J Michaud, Yonatan Be- linkov, David Bau, and Aaron Mueller
Understanding Language. Samuel Marks, Can Rager, Eric J Michaud, Yonatan Be- linkov, David Bau, and Aaron Mueller. 2025. Sparse feature circuits: Discovering and editing interpretable causal graphs in language models. InThe Thirteenth International Conference on Learning Representa- tions. Jérôme Michaud. 2024. A complex systems perspective on language ev...
work page 2025
-
[8]
Telmo Pires, Eva Schlinger, and Dan Garrette
Scaling neural machine translation to 200 lan- guages.Nature, 630(8018):841–846. Telmo Pires, Eva Schlinger, and Dan Garrette. 2019. How multilingual is multilingual BERT? InProceed- ings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4996–5001, Flo- rence, Italy. Association for Computational Linguis- tics. Inaya Rahma...
work page 2019
-
[9]
Unveiling the influence of amplifying language-specific neurons. InProceedings of the 14th International Joint Conference on Natural Lan- guage Processing and the 4th Conference of the Asia- Pacific Chapter of the Association for Computational Linguistics, pages 919–968, Mumbai, India. The Asian Federation of Natural Language Processing and The Associatio...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[10]
In Socially Responsible Language Modelling Research
Low-resource languages jailbreak GPT-4. In Socially Responsible Language Modelling Research. Appendix Contents Below we provide an overview of the appendix. These sections are intended to support the core claims by providing methodological details and extended scaling results. • Appendix A: Frequently Asked Questions (FAQs).Addresses common questions rega...
-
[11]
Do language-associated units imply the exis- tence of a universal interlingua?No. While language-associated units are clearly identifi- able and can influence model behavior, our re- sults show that they are predominantly sensitive to surface-form cues such as script and token distribution
-
[12]
Is the observed script sensitivity simply an ar- tifact of tokenization?Tokenization necessar- ily introduces distinct input embeddings across scripts, but our analysis goes beyond early-layer effects. We observe that alignment remains low even in intermediate layers, indicating that script sensitivity is not merely a tokenizer artifact but reflects persi...
-
[13]
Why use 1B and 2B models for the main ex- position?We center our primary exposition on Llama-3.2-1B and Gemma-2-2B to enable extensive, computationally intensive represen- tational sweeps and causal interventions across many layers and languages. However, to ensure our findings are not artifacts of limited capac- ity, we explicitly validate our core exper...
-
[14]
As detailed in our scaling analysis, we validate our findings on Llama-3-8B and Gemma-2-9B
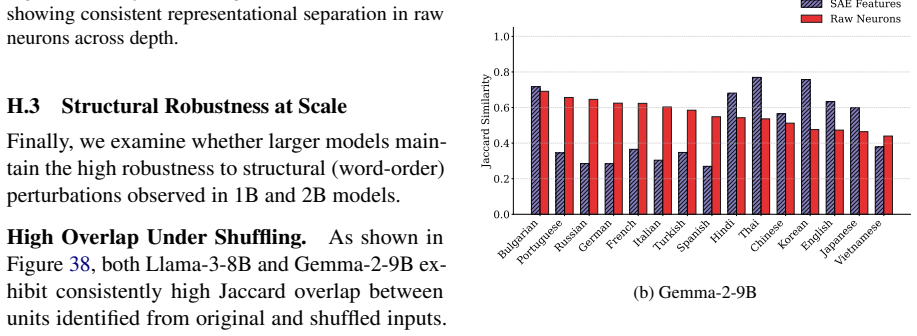
Do these findings generalize to larger mod- els?Yes. As detailed in our scaling analysis, we validate our findings on Llama-3-8B and Gemma-2-9B. We observe that representational fragmentation under script variation, as well as robustness under structural perturbation, per- sist at these larger scales. Crucially, this frag- mentation remains even though th...
-
[15]
Does strong probing performance imply func- tional importance?No. Probing reveals that typological properties become increasingly lin- early accessible in deeper layers, but causal interventions show that functional importance aligns with invariance to surface perturbations. This reinforces the view that linear decodability does not imply causal control
-
[16]
Why analyze both raw neurons and SAE fea- tures?Raw neurons directly govern model behavior, while SAE features provide an inter- pretable decomposition of these activations. An- alyzing both allows us to separate functional relevance from interpretability and avoid over- attributing abstract meaning to sparse features alone
-
[17]
यह एक बहुत ही простой , सस्ती , और ﻗﺎﺑﻞ اﻋﺘﻤﺎد اﺑﺖ कार है ,
What is the main takeaway for interpret- inglanguage-associated neurons?Language- associated units exist and matter, but they pri- marily reflect surface-form processing rather than abstract language identity. B Extended Related Work B.1 Language-Associated Units and Multilingual Representations Understanding how multilingual LMs encode lan- guage identit...
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.