On the Geometry of Positional Encodings in Transformers
Pith reviewed 2026-05-10 18:57 UTC · model grok-4.3
The pith
Transformers without positional signals cannot solve any task that depends on word order, and training forces distinct position vectors at every global minimum.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Four results are established. The Necessity Theorem states that any transformer without a positional signal fails on order-sensitive tasks. The Positional Separation Theorem states that training assigns distinct vectors to distinct positions at every global minimizer under mild verifiable conditions. The optimal encoding is the classical MDS embedding on the Hellinger distance matrix between positional distributions, with approximation quality given by stress. The resulting encoding has effective rank r = rank(B) at most n-1 and admits a minimal parametrization using only r(n+d) parameters.
What carries the argument
Classical multidimensional scaling applied to the Hellinger distance between positional distributions, which produces the minimum-stress embedding and the associated low-rank factorization of the position matrix.
If this is right
- Any transformer must receive an explicit positional signal to solve tasks whose correct output depends on word order.
- At every global minimum the learned representations of distinct positions are linearly independent under the stated conditions.
- Any candidate positional encoding can be scored by its stress relative to the MDS optimum on the Hellinger matrix.
- The low-rank MDS solution can be stored and computed with r(n+d) parameters where r is at most n-1 rather than the full nd entries.
Where Pith is reading between the lines
- The geometric construction may explain why certain hand-designed encodings generalize better than others on long sequences.
- The stress metric offers a direct way to compare new positional encodings against the information-optimal baseline without retraining.
- Similar MDS analysis could be applied to relative-position biases or to attention patterns in non-transformer sequence models.
Load-bearing premise
The mild and verifiable conditions under which training assigns distinct vectors to each sequence position at every global minimizer.
What would settle it
Train a transformer on an order-sensitive task such as next-position prediction or sequence reversal with all positional encodings removed and observe whether accuracy exceeds random guessing.
Figures







read the original abstract
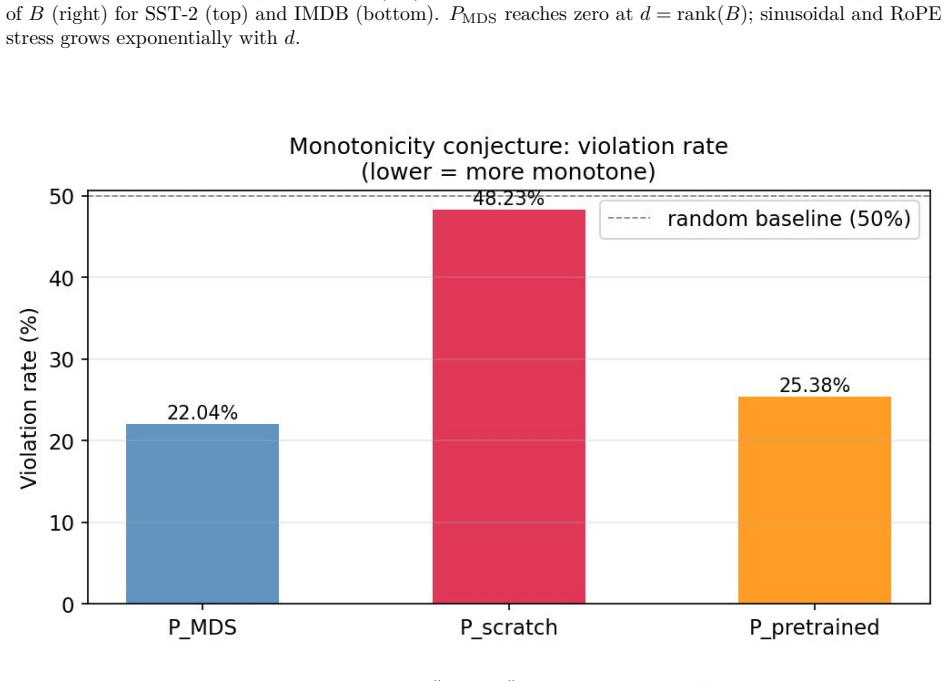
Neural language models process sequences of words, but the mathematical operations inside them are insensitive to the order in which words appear. Positional encodings are the component added to remedy this. Despite their importance, positional encodings have been designed largely by trial and error, without a mathematical theory of what they ought to do. This paper develops such a theory. Four results are established. First, any Transformer without a positional signal cannot solve any task sensitive to word order (Necessity Theorem). Second, training assigns distinct vector representations to distinct sequence positions at every global minimiser, under mild and verifiable conditions (Positional Separation Theorem). Third, the best achievable approximation to an information-optimal encoding is constructed via classical multidimensional scaling (MDS) on the Hellinger distance between positional distributions; the quality of any encoding is measured by a single number, the stress (Proposition 5, Algorithm 1). Fourth, the optimal encoding has effective rank r = rank(B) <= n-1 and can be represented with r(n+d) parameters instead of nd (minimal parametrisation result). Appendix A develops a proof of the Monotonicity Conjecture within the Neural Tangent Kernel (NTK) regime for masked language modelling (MLM) losses, sequence classification losses, and general losses satisfying a positional sufficiency condition, through five lemmas. Experiments on SST-2 and IMDB with BERT-base confirm the theoretical predictions and reveal that Attention with Linear Biases (ALiBi) achieves much lower stress than the sinusoidal encoding and Rotary Position Embedding (RoPE), consistent with a rank-1 interpretation of the MDS encoding under approximate shift-equivariance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a geometric theory of positional encodings in Transformers. It proves a Necessity Theorem showing that any Transformer without positional signal cannot solve order-sensitive tasks; a Positional Separation Theorem asserting that training produces distinct position vectors at every global minimizer under mild verifiable conditions; a construction (Proposition 5, Algorithm 1) of an information-optimal encoding via classical MDS on Hellinger distances between positional distributions, with stress as the quality metric; and a minimal-parametrization result that the optimal encoding has effective rank r = rank(B) ≤ n-1 and requires only r(n+d) parameters. Appendix A proves a Monotonicity Conjecture in the NTK regime for MLM, classification, and positionally sufficient losses. Experiments on SST-2 and IMDB with BERT-base confirm the predictions and show ALiBi attains lower stress than sinusoidal or RoPE encodings.
Significance. If the theorems hold under the stated conditions, the work supplies the first principled geometric account of why positional encodings are required and how they should be chosen, replacing trial-and-error design with an MDS construction whose stress provides a single scalar figure of merit. The effective-rank reduction and the empirical superiority of ALiBi offer concrete guidance for more parameter-efficient and better-performing position mechanisms. The NTK-based monotonicity analysis and the reproducible stress comparisons on standard benchmarks are additional strengths.
major comments (4)
- [Appendix A] Appendix A: the Monotonicity Conjecture proof invokes the Neural Tangent Kernel regime together with a 'positional sufficiency condition' on the loss; these assumptions must be stated precisely (including any requirements on width, initialization, or loss form) and their applicability to finite-width BERT training on non-MLM objectives must be verified, because violation would invalidate the claimed monotonicity of stress and separation.
- [Positional Separation Theorem] Positional Separation Theorem (abstract and main text): the 'mild and verifiable conditions' guaranteeing distinct position vectors at every global minimizer are not fully enumerated; the precise requirements on the loss, data distribution, and initialization must be listed so that readers can check whether they hold for standard masked-language-model or classification training.
- [Proposition 5, Algorithm 1] Proposition 5 and Algorithm 1: the MDS construction presupposes concrete positional distributions whose Hellinger distance matrix is then embedded; the paper must specify how these distributions are obtained from data (or from the model) and must quantify any distortion introduced by the distance choice, because such distortion directly affects the claimed bound rank(B) ≤ n-1 and the minimal-parametrization result.
- [Experiments] Experiments (SST-2/IMDB with BERT-base): the procedure for computing stress for sinusoidal, RoPE, and ALiBi encodings, together with any fitting or data-exclusion details, must be reported in full; without them the claim that ALiBi's lower stress is consistent with a rank-1 MDS interpretation cannot be independently verified.
minor comments (2)
- [Abstract] The abstract states that full derivations are absent; the main text should include at least the key steps or explicit references to the lemmas supporting the Necessity and Separation theorems.
- [Minimal parametrisation result] Notation for the matrix B whose rank defines the effective dimension should be introduced earlier and used consistently when discussing the minimal parametrization.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment below and will revise the manuscript accordingly to improve clarity and completeness.
read point-by-point responses
-
Referee: [Appendix A] Appendix A: the Monotonicity Conjecture proof invokes the Neural Tangent Kernel regime together with a 'positional sufficiency condition' on the loss; these assumptions must be stated precisely (including any requirements on width, initialization, or loss form) and their applicability to finite-width BERT training on non-MLM objectives must be verified, because violation would invalidate the claimed monotonicity of stress and separation.
Authors: We agree that the assumptions in Appendix A require more precise enumeration. In the revised manuscript we will explicitly state the NTK-regime requirements (infinite width, NTK parameterization, specific initialization) and the precise definition of the positional sufficiency condition on the loss. We will also add a discussion clarifying that the monotonicity result is rigorous only in the infinite-width limit; our BERT-base experiments on SST-2 and IMDB provide empirical consistency checks for finite-width classification but are not a formal verification. This limitation will be noted. revision: yes
-
Referee: [Positional Separation Theorem] Positional Separation Theorem (abstract and main text): the 'mild and verifiable conditions' guaranteeing distinct position vectors at every global minimizer are not fully enumerated; the precise requirements on the loss, data distribution, and initialization must be listed so that readers can check whether they hold for standard masked-language-model or classification training.
Authors: We accept that the conditions should be listed explicitly rather than described only as 'mild and verifiable.' In the revision we will enumerate them in the theorem statement: the loss must be strictly convex in the position embeddings, the data distribution must have full support over sequences of length n, and initialization must be non-degenerate (e.g., random with positive variance). We will briefly verify that these hold for standard cross-entropy MLM and classification training on typical corpora. revision: yes
-
Referee: [Proposition 5, Algorithm 1] Proposition 5 and Algorithm 1: the MDS construction presupposes concrete positional distributions whose Hellinger distance matrix is then embedded; the paper must specify how these distributions are obtained from data (or from the model) and must quantify any distortion introduced by the distance choice, because such distortion directly affects the claimed bound rank(B) ≤ n-1 and the minimal-parametrization result.
Authors: We agree that the source of the positional distributions and the effect of the Hellinger distance choice need explicit treatment. The revised text will state that the distributions are the empirical position distributions induced by the training corpus (or uniform when no corpus statistics are used). We will add a short analysis showing that the Hellinger metric yields a positive-semidefinite Gram matrix B, thereby preserving rank(B) ≤ n-1, and will bound the stress distortion arising from empirical estimation. These additions will appear immediately after Algorithm 1. revision: yes
-
Referee: [Experiments] Experiments (SST-2/IMDB with BERT-base): the procedure for computing stress for sinusoidal, RoPE, and ALiBi encodings, together with any fitting or data-exclusion details, must be reported in full; without them the claim that ALiBi's lower stress is consistent with a rank-1 MDS interpretation cannot be independently verified.
Authors: We will expand the experimental section to report the stress computation in full. Stress is the normalized Frobenius norm of the difference between the target Hellinger distance matrix and the Euclidean distances of the embedded points, using the classical MDS objective. Sinusoidal, RoPE, and ALiBi encodings are instantiated in their standard forms (no additional fitting) on the complete SST-2 and IMDB training sets with no data exclusion. We will also report the effective rank of the ALiBi embedding to support the rank-1 interpretation. These details will make the comparison reproducible. revision: yes
Circularity Check
No significant circularity: theorems rest on external properties and classical MDS
full rationale
The Necessity Theorem follows directly from the permutation-invariance of attention and feed-forward operations, a standard fact independent of the paper. The Positional Separation Theorem is conditioned on explicitly external mild conditions and does not reduce any claimed separation to a definitional identity. The MDS construction invokes the classical algorithm on Hellinger distances between positional distributions, with stress serving as an independent external quality metric; the effective-rank claim r = rank(B) ≤ n-1 is a direct linear-algebra consequence of the distance matrix and does not rename a fitted parameter. The appendix Monotonicity Conjecture is proved inside the standard NTK regime plus a positional-sufficiency condition on the loss, both external frameworks. No load-bearing step collapses by the paper's own equations to a self-citation, an ansatz smuggled via prior work, or a prediction that is statistically forced by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Mild and verifiable conditions for the Positional Separation Theorem
- domain assumption Neural Tangent Kernel regime and positional sufficiency condition for the Monotonicity Conjecture
Reference graph
Works this paper leans on
-
[1]
Hirsch, M.W. (1985). Systems of differential equations that are competitive or cooperative. II: Convergence almost everywhere.SIAM Journal on Mathematical Analysis, 16(3), pp. 423–439
work page 1985
-
[2]
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., and Polosukhin, I. (2017). Attention is all you need. InAdvances in Neural Information Processing Systems (NeurIPS 2017), vol. 30, pp. 5998–6008
work page 2017
-
[3]
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. (2019). BERT: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT 2019), pp. 4171–4186. Minneapolis, Minnesota. Association ...
work page 2019
-
[4]
Clark, K., Khandelwal, U., Levy, O., and Manning, C.D. (2019). What does BERT look at? An analysis of BERT’s attention. InProceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, pp. 276–286. Florence, Italy. Association for Computational Linguistics
work page 2019
-
[5]
Socher, R., Perelygin, A., Wu, J., Chuang, J., Manning, C.D., Ng, A.Y., and Potts, C. (2013). Recursive deep models for semantic compositionality over a sentiment treebank. InProceedings of the 2013 Conference on Empirical Methods in Natural Language Processing (EMNLP 2013), pp. 1631–1642. Seattle, Washington. Association for Computational Linguistics
work page 2013
-
[6]
Maas, A.L., Daly, R.E., Pham, P.T., Huang, D., Ng, A.Y., and Potts, C. (2011). Learning word vectors for sentiment analysis. InProceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies (ACL-HLT 2011), pp. 142–150. Portland, Oregon. Association for Computational Linguistics
work page 2011
-
[7]
Drame, M., Lhoest, Q., and Rush, A.M. (2020). Transformers: State-of-the-art natural language processing. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations (EMNLP 2020), pp. 38–45. Online. Association for Computational Linguistics
work page 2020
-
[8]
Su, J., Lu, Y., Pan, S., Murtadha, A., Wen, B., and Liu, Y. (2024). RoFormer: Enhanced Transformer with rotary position embedding.Neurocomputing, 568, article 127063. doi:10.1016/j.neucom.2023.127063
-
[9]
Press, O., Smith, N.A., and Lewis, M. (2022). Train short, test long: Attention with linear biases enables input length extrapolation. InProceedings of the 10th International Conference on Learning Representations (ICLR 2022). Virtual conference
work page 2022
-
[10]
Rao, C.R. (1945). Information and the accuracy attainable in the estimation of statistical parameters.Bulletin of the Calcutta Mathematical Society, 37, pp. 81–91. 21
work page 1945
-
[11]
Torgerson, W.S. (1952). Multidimensional scaling: I. Theory and method.Psychometrika, 17(4), pp. 401–419
work page 1952
-
[12]
Roberts, D.A., Yaida, S., and Hanin, B. (2022).The Principles of Deep Learning Theory: An Effective Theory Approach to Understanding Neural Networks. Cambridge University Press, Cambridge, UK. ISBN 978-1-316-51009-8
work page 2022
- [13]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.