Recognition: no theorem link
Adaptive Prompt Structure Factorization: A Framework for Self-Discovering and Optimizing Compositional Prompt Programs
Pith reviewed 2026-05-10 18:53 UTC · model grok-4.3
The pith
By factoring prompts into semantic components and updating them individually through interventions, aPSF achieves better accuracy with substantially lower optimization costs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
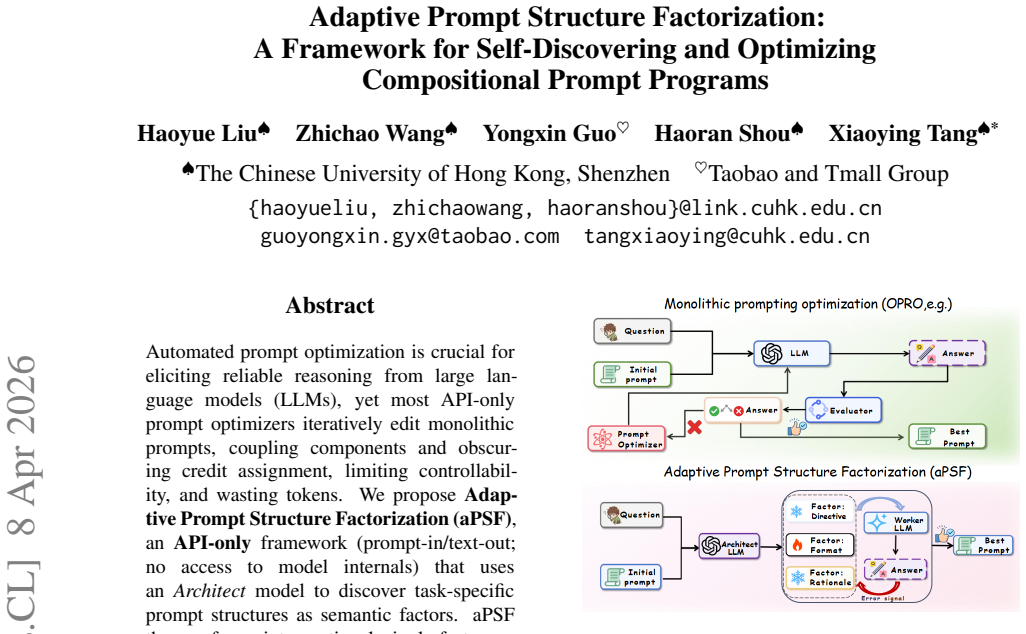
aPSF employs an Architect model to discover task-specific prompt structures as semantic factors. It then applies interventional single-factor updates, where each factor's marginal contribution is estimated by changes in validation performance, and error-guided selection directs updates to the dominant failure source. This compositional approach outperforms monolithic prompt optimizers on reasoning benchmarks.
What carries the argument
The Architect model for self-discovering semantic factors together with interventional factor-level scoring that isolates each factor's contribution.
Load-bearing premise
The factors discovered by the Architect model represent truly independent components of the prompt, allowing their individual effects on performance to be measured and optimized in isolation.
What would settle it
A controlled test in which changing one discovered factor produces performance shifts that cannot be isolated to that factor alone, or in which aPSF shows no reliable accuracy gain over strong baselines across repeated trials.
Figures














read the original abstract
Automated prompt optimization is crucial for eliciting reliable reasoning from large language models (LLMs), yet most API-only prompt optimizers iteratively edit monolithic prompts, coupling components and obscuring credit assignment, limiting controllability, and wasting tokens. We propose Adaptive Prompt Structure Factorization (aPSF), an API-only framework (prompt-in/text-out; no access to model internals) that uses an Architect model to discover task-specific prompt structures as semantic factors. aPSF then performs interventional, single-factor updates: interventional factor-level scoring estimates each factor's marginal contribution via validation-performance changes, and error-guided factor selection routes updates to the current dominant failure source for more sample-efficient optimization. Across multiple advanced reasoning benchmarks, aPSF outperforms strong baselines including principle-aware optimizers, improving accuracy by up to +2.16 percentage points on average, and reduces optimization cost by 45--87% tokens on MultiArith while reaching peak validation in 1 step.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Adaptive Prompt Structure Factorization (aPSF), an API-only framework for prompt optimization in LLMs. An Architect model discovers task-specific semantic factors from prompts; these are then optimized via interventional single-factor updates that estimate marginal contributions from validation-performance deltas and route updates to dominant failure sources. The central claims are that aPSF outperforms strong baselines (including principle-aware optimizers) by up to +2.16 percentage points on average across reasoning benchmarks while reducing optimization cost by 45-87% tokens on MultiArith and reaching peak validation performance in a single step.
Significance. If the empirical results and underlying isolation assumption hold, aPSF would represent a meaningful advance in controllable, sample-efficient prompt optimization under API-only constraints. The approach directly addresses credit-assignment opacity in monolithic prompt editing and could reduce token waste in iterative optimization loops. The reported gains and speed-ups, if reproducible, would be of practical interest to the prompt-engineering community.
major comments (1)
- The interventional single-factor scoring procedure (described in the abstract and methodology) rests on the untested assumption that the Architect-discovered semantic factors are sufficiently independent for marginal credit assignment. No factor-correlation statistics, joint-update ablations, or sensitivity analysis on factor granularity are reported; if factors interact (e.g., a reasoning-template factor modulating example-selection usage), the single-factor delta will misattribute gains, directly undermining both the +2.16 pp accuracy claim and the 45-87% token-reduction claim.
minor comments (2)
- Abstract: performance numbers are stated without accompanying details on experimental setup, number of runs, statistical tests, or variance, making it impossible to assess whether the reported gains are robust.
- The manuscript should include explicit definitions or pseudocode for the Architect factorization step and the error-guided factor-selection rule to allow replication.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed review. The concern about the independence assumption in our interventional scoring is well-taken, and we address it directly below while committing to strengthen the manuscript with additional analyses.
read point-by-point responses
-
Referee: The interventional single-factor scoring procedure (described in the abstract and methodology) rests on the untested assumption that the Architect-discovered semantic factors are sufficiently independent for marginal credit assignment. No factor-correlation statistics, joint-update ablations, or sensitivity analysis on factor granularity are reported; if factors interact (e.g., a reasoning-template factor modulating example-selection usage), the single-factor delta will misattribute gains, directly undermining both the +2.16 pp accuracy claim and the 45-87% token-reduction claim.
Authors: We agree that the single-factor interventional updates rely on the assumption that Architect-discovered semantic factors exhibit limited interactions, enabling reliable marginal credit assignment through validation-performance deltas. The current manuscript does not report explicit pairwise factor-correlation statistics, joint-update ablations, or granularity sensitivity analyses. However, the consistent accuracy gains (up to +2.16 pp) and token reductions (45-87% on MultiArith) across multiple reasoning benchmarks provide indirect empirical support that the discovered factors permit effective, sample-efficient optimization in practice. To directly address the concern, we will revise the manuscript to include: (1) quantitative statistics on factor correlations derived from co-occurrence patterns in the optimized prompts, (2) an ablation study comparing single-factor updates against joint multi-factor updates, and (3) sensitivity analysis varying the Architect's factor-granularity prompt. These additions will test the independence assumption and clarify the conditions under which marginal scoring remains valid, thereby reinforcing the reported accuracy and efficiency claims. revision: yes
Circularity Check
No circularity: empirical framework with independent validation
full rationale
The paper presents aPSF as an empirical API-only method: an Architect model discovers semantic factors, followed by interventional single-factor scoring on validation performance deltas and error-guided updates. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claims (accuracy gains, token savings) rest on reported benchmark comparisons to external baselines rather than reducing to definitions or prior self-work by construction. The independence assumption for factors is an untested modeling choice (correctness risk) but does not create definitional or fitted-input circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2402.08702 , year=
Finite-time analysis of the multiarmed bandit problem. Machine learning, 47(2):235–256. Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901...
-
[2]
In The Twelfth International Conference on Learning Rep- resentations
Large language models as optimizers. In The Twelfth International Conference on Learning Rep- resentations. Shunyu Y ao, Dian Y u, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Y uan Cao, and Karthik Narasimhan
-
[3]
Advances in neural in- formation processing systems, 36:11809–11822
Tree of thoughts: Deliberate problem solving with large language models. Advances in neural in- formation processing systems, 36:11809–11822. Seungyoun Yi, Minsoo Khang, and Sungrae Park
-
[4]
[verbatim substring from template]
Zera: Zero-init instruction evolving re- finement agent–from zero instructions to structured prompts via principle-based optimization. In Pro- ceedings of the 2025 Conference on Empirical Meth- ods in Natural Language Processing , pages 23334– 23348. Zihao Zhao, Eric Wallace, Shi Feng, Dan Klein, and Sameer Singh. 2021. Calibrate before use: Improv- ing fe...
work page 2025
-
[5]
Output ONLY the new text segment
-
[6]
The new segment must be grammatically compatible with the surrounding text
-
[7]
PRESERVE what makes the current prompt work for correct samples
-
[8]
Keep improvements CONCISE and GENERAL-PURPOSE for this dataset type
-
[9]
Do NOT overfit to the specific error examples - improve the general approach
-
[10]
Consider the nature of {dataset_name} tasks when making improvements
-
[11]
Do NOT include markdown blocks, just raw JSON. Output format: A valid JSON array of strings, e.g., [“description 1”, “description 2”]. Figure 9: Meta-prompt for Factor-Wise Editing. It provides error analysis as reference while explicitly preventing overfitting through general-purpose constraints. Semantic grouping for cross-task analysis. For the heatmap ...
-
[12]
Error Essence: Identify the fundamental root cause of the error
-
[13]
Error Type: Assign a concise and descriptive label to characterize the error
-
[14]
Error Mechanism: Explain how and why the error occurred
-
[15]
Error Impact: Assess how this error affects the overall reasoning or outcome
-
[16]
Improvement Direction: Propose specific and actionable prompt-level improvements. Response Format Error Essence: [...] Error Type: [...] Error Mechanism: [...] Error Impact: [...] Improvement Suggestion: [...] Figure 10: Meta-prompt for Step 1: Open-Ended Error Diagnosis . It enables unbiased identification of root causes and failure mechanisms prior to ta...
-
[17]
The factor whose improvement would most directly resolve the root cause
-
[18]
The factor whose scope best aligns with the observed failure patterns
-
[19]
The factor with the highest potential to prevent similar future errors. Factor Selection History Frequently selected: {overexplored_factors} Less explored: {underexplored_factors} Recommendation: If the less explored factors are also relevant to solving the current errors, consider giving them opportunities to ensure balanced exploration and avoid over-fo...
work page 2025
-
[20]
ComponentAnalysis: Identify key quantities
-
[21]
CalculationExecution: Perform arithmetic operations
-
[22]
ParsingStatements: Extract logical premises
ResultAggregation: Format final output 1 → 2 → 3 → 4 Logic (BBH) 1. ParsingStatements: Extract logical premises
-
[23]
EstablishingOrder: Deduce chronological/logical sequence
-
[24]
EvaluatingOptions: V erify consistency against premises
-
[25]
ProblemAnalysis: Identify question type
OptionV erification: Double-check constraints 1 → 2 → 3 → 4 QA (AQUA) 1. ProblemAnalysis: Identify question type
-
[26]
CalculationExecution: Perform systematic calculations
-
[27]
V erification: Self-validate plausibility
-
[28]
AnswerSelection: Select correct option 1 → 2 → 3 → 4 Table 14: Factor structures discovered by aPSF. The factor names (e.g., ComponentAnalysis, CalculationExecu- tion) correspond to the domain-specific terminology cataloged in Appendix K. Parameter Value Temperature 0.0 (deterministic) Top-p (nucleus sampling) 1.0 (disabled) Top-k Not applied Max output to...
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.