Recognition: no theorem link
ORACLE-SWE: Quantifying the Contribution of Oracle Information Signals on SWE Agents
Pith reviewed 2026-05-10 18:25 UTC · model grok-4.3
The pith
Oracle-SWE isolates perfect versions of key signals from SWE benchmarks to measure their separate effects on agent success rates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
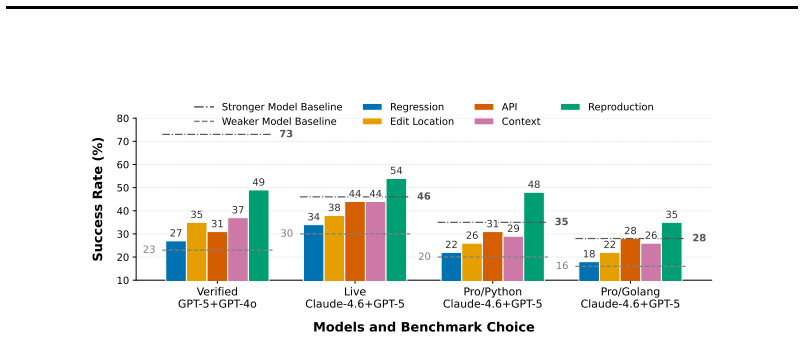
We introduce Oracle-SWE, a unified method to isolate and extract oracle information signals from SWE benchmarks and quantify the impact of each signal on agent performance. To further validate the pattern, we evaluate the performance gain of signals extracted by strong LMs when provided to a base agent, approximating real-world task-resolution settings. These evaluations aim to guide research prioritization for autonomous coding systems.
What carries the argument
Oracle-SWE, the extraction procedure that creates perfect oracles for each listed information signal and then measures the change in agent success when each oracle is supplied.
If this is right
- Each signal can be ranked by the size of the success-rate increase it produces when supplied as an oracle.
- The gap between oracle gains and LM-supplied gains indicates how much room remains for improving signal acquisition in practical agents.
- Combined oracles produce higher success than any single signal, establishing an upper bound on what perfect information could achieve.
- The measured contributions can be used to decide which signal-acquisition capabilities to implement first in new agent workflows.
Where Pith is reading between the lines
- Future agent architectures could be built around first acquiring the highest-impact signals rather than attempting all signals at once.
- The same isolation technique could be applied to non-SWE agent domains to rank information sources by usefulness.
- Benchmark designers might add explicit tests for whether an agent can obtain each signal on its own.
Load-bearing premise
That performance gains measured with perfect, isolated oracle signals will accurately reflect how much value those same signals provide when agents must discover them imperfectly amid noise and interdependencies.
What would settle it
Re-running the full Oracle-SWE pipeline on the same benchmarks but supplying the oracles in random order or with added noise and finding that the relative performance ordering of the signals changes.
Figures








read the original abstract
Recent advances in language model (LM) agents have significantly improved automated software engineering (SWE). Prior work has proposed various agentic workflows and training strategies as well as analyzed failure modes of agentic systems on SWE tasks, focusing on several contextual information signals: Reproduction Test, Regression Test, Edit Location, Execution Context, and API Usage. However, the individual contribution of each signal to overall success remains underexplored, particularly their ideal contribution when intermediate information is perfectly obtained. To address this gap, we introduce Oracle-SWE, a unified method to isolate and extract oracle information signals from SWE benchmarks and quantify the impact of each signal on agent performance. To further validate the pattern, we evaluate the performance gain of signals extracted by strong LMs when provided to a base agent, approximating real-world task-resolution settings. These evaluations aim to guide research prioritization for autonomous coding systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Oracle-SWE, a unified method to isolate and extract five oracle information signals (Reproduction Test, Regression Test, Edit Location, Execution Context, API Usage) from SWE benchmarks. It quantifies each signal's contribution to agent performance by injecting them as perfect oracles and measuring marginal gains, then evaluates performance when the same signals are extracted by strong LMs and supplied to a base agent.
Significance. If the reported quantifications prove robust, the work could help prioritize which information signals to emphasize when designing autonomous SWE agents, providing a clearer basis for allocating research effort among reproduction, localization, and execution signals.
major comments (1)
- [Method / Oracle-SWE procedure] The core quantification procedure (described in the abstract and the method outline) injects each of the five signals independently as a perfect oracle and reports additive performance deltas. This design assumes signals are independent and that discovery costs are zero; however, the manuscript provides no analysis or ablation of pairwise correlations (e.g., whether Edit Location reduces the marginal value of Reproduction Test) or of the agent steps consumed in discovering signals. Because the central claim is a quantitative ranking of signal importance, this independence assumption is load-bearing and requires either empirical validation or an explicit bounding argument.
minor comments (1)
- [Abstract] The abstract states that LM-extracted signals are evaluated 'to further validate the pattern,' but does not define what pattern is being validated or how the LM-extraction protocol differs from the oracle protocol; a short clarifying sentence would improve readability.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the single major comment below and describe the planned revisions.
read point-by-point responses
-
Referee: The core quantification procedure (described in the abstract and the method outline) injects each of the five signals independently as a perfect oracle and reports additive performance deltas. This design assumes signals are independent and that discovery costs are zero; however, the manuscript provides no analysis or ablation of pairwise correlations (e.g., whether Edit Location reduces the marginal value of Reproduction Test) or of the agent steps consumed in discovering signals. Because the central claim is a quantitative ranking of signal importance, this independence assumption is load-bearing and requires either empirical validation or an explicit bounding argument.
Authors: We appreciate the referee highlighting this point. Oracle-SWE is explicitly constructed to measure the isolated upper-bound contribution of each signal under perfect information; this isolation is intentional to produce a clear ranking for research prioritization. We agree, however, that the manuscript contains no pairwise ablation or explicit treatment of discovery costs. In the revision we will add (i) an ablation table reporting performance deltas for all pairwise signal combinations and (ii) a short discussion that bounds the number of agent steps typically required to obtain each signal, thereby providing the requested empirical check and clarifying the scope of the independence assumption. revision: yes
Circularity Check
No circularity: Oracle-SWE is an empirical isolation method with independent benchmark measurements
full rationale
The paper introduces Oracle-SWE as a procedure to extract specific information signals from existing SWE benchmarks and measure agent performance gains when each signal is provided as a perfect oracle. This is a direct experimental design relying on external task benchmarks and agent runs rather than any closed mathematical derivation, parameter fitting, or self-referential definition. No equations, uniqueness theorems, or ansatzes are described that reduce the reported quantifications to the method's own inputs by construction. The central claim therefore remains self-contained against external evaluation data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[3]
If any of the testcases required above fails, go back to explore and edit again
Run reproduction and regression tests to validate your fix. If any of the testcases required above fails, go back to explore and edit again
-
[4]
"" ) eliflocation: USER_PROMPT =
If you pass both reproduction and regression tests, submit. """ ) eliflocation: USER_PROMPT = """ Following your colleagues' contributions, your next steps should be:
-
[5]
But remember that all the locations that need to edited have been listed above
Explore the source codes if you want to understand the contexts of the buggy locations or testcases better. But remember that all the locations that need to edited have been listed above
-
[7]
Edit all the locations specified by your colleagues to resolve the issue.\n"
-
[8]
Due to time limit, do not run the regression tests in the repository
Run your reproduction script to validate your fix. Due to time limit, do not run the regression tests in the repository. If the reproduction script still fails, go back to explore and edit again
-
[9]
"" elifreproduction: USER_PROMPT =
If you pass your reproduction script, submit. """ elifreproduction: USER_PROMPT = """ Following your colleagues' contributions, your next steps should be:\n"
-
[11]
Edit the codes to resolve the issue
-
[12]
Due to time limit, do not run the regression tests in the repository
Run reproduction tests to validate your fix. Due to time limit, do not run the regression tests in the repository. If any of the reproduction testcases listed above fails, go back to explore and edit again
-
[13]
"" ) elifregression: USER_PROMPT =
If you pass ALL the reproduction tests, submit. """ ) elifregression: USER_PROMPT = """ Follow these steps to resolve the issue:
-
[15]
Create a script to reproduce the problem and execute it using the bash tool to confirm the problem
-
[17]
Rerun your reproduce script to confirm that the error is fixed. Run the regression tests found by your colleague to check that your edits have not broken anything else. If your reproduce script or any of the regression testcases required above fail, go back to explore and edit again
-
[18]
If you pass both your reproduce script and all the regression tests found by your colleague, submit your answer. """ else: USER_PROMPT = """ Follow these steps to resolve the issue:
-
[19]
As a first step, it might be a good idea to find and read code relevant to the <pr_description>
-
[20]
Create a script to reproduce the error and execute it using the bash tool to confirm the error
-
[21]
Edit the sourcecode of the repo to resolve the issue
-
[22]
Rerun your reproduce script and confirm that the error is fixed!
-
[23]
"" H Agent Prompt of Validation Experiment Stage 1 (Signal Extraction) ifreproduction: iflang ==
Think about edgecases and make sure your fix handles them as well 34 Your thinking should be thorough and so it's fine if it's very long. """ H Agent Prompt of Validation Experiment Stage 1 (Signal Extraction) ifreproduction: iflang == "python": target_file = "/testbed/reproduction.py" eliflang == "go": target_file = "/testbed/reproduction_test.go" else: ...
-
[24]
all the API functions that need to be used to edit the code to resolve the issue
-
[25]
the important API functions that are used around the locations to be edited which can help understand how to edit the code. These API functions are crucial for understanding how to edit the code and avoiding implementing existing utilities again. You need to determine where the API functions are used / will be used for editing the source code, and find th...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.