MedConceal: A Benchmark for Clinical Hidden-Concern Reasoning Under Partial Observability
Pith reviewed 2026-05-10 16:50 UTC · model grok-4.3
The pith
MedConceal shows hidden patient concerns remain a core unsolved challenge for medical dialogue systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
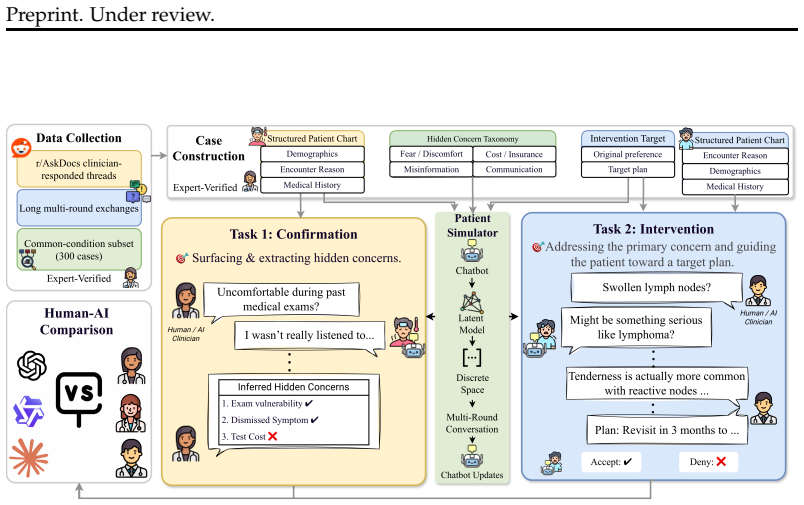
The MedConceal benchmark, built from clinician-answered online discussions and featuring a simulator that withholds hidden concerns while tracking their elicitation and resolution, demonstrates that no single system dominates confirmation metrics while human clinicians achieve the highest rates of successful intervention.
What carries the argument
An interactive patient simulator that pairs clinician-visible context with withheld hidden concerns, structures them via an expert taxonomy, and monitors revelation through theory-grounded turn-level communication signals.
If this is right
- Medical dialogue evaluation must measure the interactive process of elicitation rather than treating patient state as fully observable.
- Systems need separate training for surfacing latent concerns and for converting confirmed concerns into actionable care plans.
- Benchmarks should incorporate partial observability to avoid overestimating performance on tasks that assume complete information.
- Progress on this challenge would directly improve the realism of automated medical assistants.
Where Pith is reading between the lines
- The simulator could generate synthetic training dialogues to improve model performance on information-asymmetric tasks.
- Similar hidden-state designs might transfer to other domains with asymmetric information, such as legal or financial advising.
- If models close the gap on intervention success, it could reduce reliance on human clinicians for initial patient triage conversations.
Load-bearing premise
The expert-developed taxonomy and clinician-reviewed simulator cases accurately capture clinically relevant hidden concerns and the theory-grounded signals validly measure whether those concerns have been revealed and addressed.
What would settle it
A real-world study in which the same systems interact with actual patients and the benchmark's confirmation and intervention scores fail to predict measured patient adherence or satisfaction outcomes.
Figures








read the original abstract
Patient-clinician communication is an asymmetric-information problem: patients often do not disclose fears, misconceptions, or practical barriers unless clinicians elicit them skillfully. Effective medical dialogue therefore requires reasoning under partial observability: clinicians must elicit latent concerns, confirm them through interaction, and respond in ways that guide patients toward appropriate care. However, existing medical dialogue benchmarks largely sidestep this challenge by exposing hidden patient state, collapsing elicitation into extraction, or evaluating responses without modeling what remains hidden. We present MedConceal, a benchmark with an interactive patient simulator for evaluating hidden-concern reasoning in medical dialogue, comprising 300 curated cases and 600 clinician-LLM interactions. Built from clinician-answered online health discussions, each case pairing clinician-visible context with simulator-internal hidden concerns derived from prior literature and structured using an expert-developed taxonomy. The simulator withholds these concerns from the dialogue agent, tracks whether they have been revealed and addressed via theory-grounded turn-level communication signals, and is clinician-reviewed for clinical plausibility. This enables process-aware evaluation of both task success and the interaction process that leads to it. We study two abilities: confirmation, surfacing hidden concerns through multi-turn dialogue, and intervention, addressing the primary concern and guiding the patient toward a target plan. Results show that no single system dominates: frontier models lead on different confirmation metrics, while human clinicians (N=159) remain strongest on intervention success. Together, these results identify hidden-concern reasoning under partial observability as a key unresolved challenge for medical dialogue systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MedConceal, a benchmark with 300 curated cases derived from online health discussions and an interactive patient simulator that withholds hidden concerns (structured via an expert taxonomy) to evaluate hidden-concern reasoning under partial observability in medical dialogue. The simulator tracks revelation and addressing of concerns using theory-grounded turn-level signals (clinician-reviewed for plausibility) and supports 600 interactions. It evaluates LLMs and human clinicians (N=159) on two abilities—confirmation (surfacing concerns via multi-turn dialogue) and intervention (addressing the primary concern and guiding toward a target plan)—finding that no single system dominates, with frontier models leading on different confirmation metrics while humans are strongest on intervention success.
Significance. If the simulator and signals hold, this work is significant as it fills a gap in medical dialogue benchmarks by explicitly modeling partial observability and process-aware evaluation rather than collapsing to extraction or exposed state. The clinician-reviewed construction from real discussions and the finding that humans outperform on intervention identify a concrete, unresolved challenge for LLM-based systems. Credit is due for shipping a new interactive benchmark with 300 cases and 600 interactions grounded in prior literature and expert taxonomy.
major comments (2)
- [§3 (Simulator and Signals)] §3 (Simulator and Signals): The theory-grounded turn-level communication signals used to score whether hidden concerns have been revealed and addressed are load-bearing for the central claim that humans remain strongest on intervention success and that hidden-concern reasoning is unresolved. Clinician review establishes plausibility but does not demonstrate that the signals distinguish genuine clinical resolution from superficial elicitation or correctly capture subtle addressing; without additional validation (e.g., outcome correlation or blinded expert scoring of full transcripts), the comparative results risk over- or under-estimating model performance.
- [§4 (Case Curation and Taxonomy)] §4 (Case Curation and Taxonomy): The process for deriving the 300 cases and expert taxonomy from online discussions, including selection criteria, diversity controls, and mitigation of curation bias, is described at a high level but lacks quantitative details such as inter-rater agreement or sensitivity analysis. This is load-bearing because the headline finding that no system dominates and that the challenge is unresolved depends on the cases and taxonomy accurately representing clinically relevant hidden concerns.
minor comments (2)
- [Abstract] The abstract states 600 clinician-LLM interactions but the methods should explicitly clarify how these map to the 300 cases and whether multiple interactions per case are used for robustness.
- [Results] Figure or table presenting per-model confirmation metrics would benefit from error bars or statistical comparisons to support the claim that 'no single system dominates.'
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments highlight important aspects of validation and documentation for the benchmark. We respond to each major comment below, proposing targeted revisions to the manuscript where feasible while maintaining the scope of this work as a benchmark introduction.
read point-by-point responses
-
Referee: §3 (Simulator and Signals): The theory-grounded turn-level communication signals used to score whether hidden concerns have been revealed and addressed are load-bearing for the central claim that humans remain strongest on intervention success... without additional validation (e.g., outcome correlation or blinded expert scoring of full transcripts), the comparative results risk over- or under-estimating model performance.
Authors: We agree that stronger validation of the signals would increase confidence in the results. The signals are derived from established patient-clinician communication frameworks in the literature and were reviewed by clinicians for clinical plausibility on a per-case basis. However, we did not perform blinded full-transcript scoring or outcome correlation, as these would require a separate, resource-intensive validation study beyond the current benchmark release. We will revise §3 to expand the description of signal definitions, the exact clinician review protocol (including reviewer expertise and process), and add an explicit limitations paragraph noting the absence of these additional validations and recommending them as future work. This clarifies the evidential basis without overstating the signals' demonstrated properties. revision: partial
-
Referee: §4 (Case Curation and Taxonomy): The process for deriving the 300 cases and expert taxonomy from online discussions, including selection criteria, diversity controls, and mitigation of curation bias, is described at a high level but lacks quantitative details such as inter-rater agreement or sensitivity analysis. This is load-bearing because the headline finding that no system dominates and that the challenge is unresolved depends on the cases and taxonomy accurately representing clinically relevant hidden concerns.
Authors: We acknowledge that additional quantitative details on curation would strengthen the description. The 300 cases were derived from clinician-answered online discussions using explicit selection criteria for hidden-concern relevance, diversity across demographics and concern types (per the taxonomy), and bias mitigation through expert oversight. We will revise §4 to include quantitative information on the curation pipeline, such as the number of source discussions initially screened, the proportion retained after criteria application, and details on the expert consensus process used for taxonomy development. If formal inter-rater agreement statistics were not computed, we will describe the multi-expert review steps taken instead and note this as a point for future refinement. revision: yes
Circularity Check
No circularity: new benchmark with external clinician validation and empirical comparisons
full rationale
The paper constructs MedConceal from online health discussions using an expert-developed taxonomy and clinician-reviewed simulator cases, then evaluates LLMs and human clinicians (N=159) on confirmation and intervention metrics via theory-grounded turn-level signals. No derivation chain, equations, fitted parameters, or self-citations reduce the central results to inputs by construction; the findings are direct empirical comparisons on a newly built dataset with external human baselines, satisfying the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Expert-developed taxonomy structures hidden concerns derived from prior literature and online discussions.
- domain assumption Clinician review ensures the simulator cases are clinically plausible.
invented entities (1)
-
Interactive patient simulator
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2601.03023 , year=
Lecheng Gong, Weimin Fang, Ting Yang, Dongjie Tao, Chunxiao Guo, Peng Wei, Bo Xie, Jinqun Guan, Zixiao Chen, Fang Shi, Jinjie Gu, and Junwei Liu. Meddialogrubrics: A com- prehensive benchmark and evaluation framework for multi-turn medical consultations in large language models.arXiv preprint arXiv:2601.03023,
-
[2]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
arXiv preprint arXiv:2510.04284 (2025) 24
Yunghwei Lai, Kaiming Liu, Ziyue Wang, Weizhi Ma, and Yang Liu. Doctor-r1: Mas- tering clinical inquiry with experiential agentic reinforcement learning.arXiv preprint arXiv:2510.04284,
-
[4]
11 Preprint. Under review. Run Peng, Ziqiao Ma, Amy Pang, Sikai Li, Zhang Xi-Jia, Yingzhuo Yu, Cristian-Paul Bara, and Joyce Chai. Communication and verification in llm agents towards collaboration under information asymmetry.arXiv preprint arXiv:2510.25595,
-
[5]
Clarity: Clinical assistant for routing, inference, and triage
Vladimir Shaposhnikov, Alexandr Nesterov, Ilia Kopanichuk, Ivan Bakulin, Zhelvakov Egor, Ruslan Abramov, Tsapieva Ekaterina Olegovna, Iaroslav Radionovich Bespalov, Dmitry V Dylov, and Ivan Oseledets. Clarity: Clinical assistant for routing, inference, and triage. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: In...
work page 2025
-
[6]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Ruiyi Wang, Stephanie Milani, Jamie C Chiu, Jiayin Zhi, Shaun M Eack, Travis Labrum, Samuel M Murphy, Nev Jones, Kate V Hardy, Hong Shen, et al. Patient-ψ: using large lan- guage models to simulate patients for training mental health professionals. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 12772–12797,
work page 2024
-
[8]
Measuring bargaining abilities of llms: A benchmark and a buyer-enhancement method
Tian Xia, Zhiwei He, Tong Ren, Yibo Miao, Zhuosheng Zhang, Yang Yang, and Rui Wang. Measuring bargaining abilities of llms: A benchmark and a buyer-enhancement method. InFindings of the Association for Computational Linguistics: ACL 2024, pp. 3579–3602,
work page 2024
-
[9]
Assessing motivational interviewing sessions with ai-generated patient simulations
Stav Yosef, Moreah Zisquit, Ben Cohen, Anat Klomek Brunstein, Kfir Bar, and Doron Fried- man. Assessing motivational interviewing sessions with ai-generated patient simulations. InProceedings of the 9th Workshop on Computational Linguistics and Clinical Psychology (CLPsych 2024). Association for Computational Linguistics,
work page 2024
-
[10]
12 Preprint. Under review. A Appendix Table of Contents •Appendix B: Related Work. • Appendix C: Data and Case Construction: source data and conversation extraction; common-condition subset construction; patient profile taxonomy; patient case population; annotation and labeling. • Appendix D: Human Clinician Study Details: recruitment and eligibility crit...
work page 2025
-
[11]
As in the confirmation appendix, these analyses operate on per-case metric values averaged over the 300 benchmark cases rather than on the concatenated main-paper aggregates. Because the main text treats the matched 8-turn condition as the fairness-aligned human–AI comparison, we focus on that family here and report only metrics for which the human refere...
work page 2018
-
[12]
Receiver value alignment Values Det
Scores how well the clin- ician validates concerns, explains need, collabo- rates, addresses barriers, and gives actionable next steps. Receiver value alignment Values Det. Value-framed health commu- nication (Heine & Wolters, 2021; Winters et al.,
work page 2021
-
[13]
The latent policy converts these turn-level rubric signals into state transitions
This shared evaluator is used for both human-trace export and offline AI evaluation so that reveal and address dynamics are computed from the same signal space. The latent policy converts these turn-level rubric signals into state transitions. For con- firmation, the policy computes a reveal-observation probability independently for each still-hidden conc...
work page 2002
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.