Grid2Matrix: Revealing Digital Agnosia in Vision-Language Models
Pith reviewed 2026-05-10 18:41 UTC · model grok-4.3
The pith
Vision-language models lose fine grid details when converting colors to numbers because a gap opens between what their visual encoders retain and what their language output can express.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
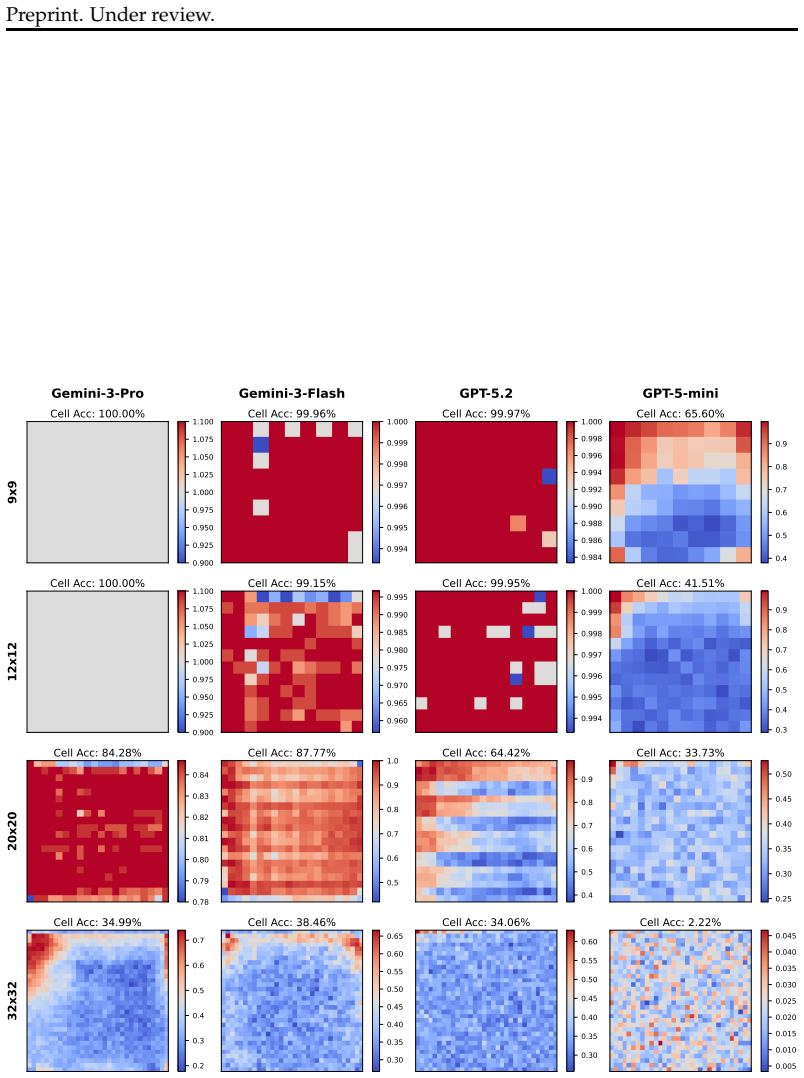
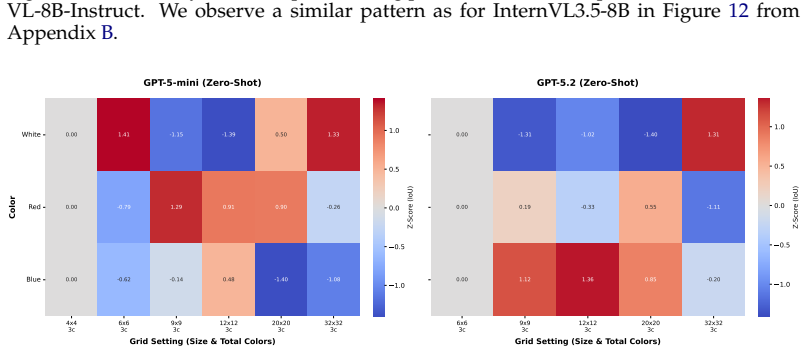
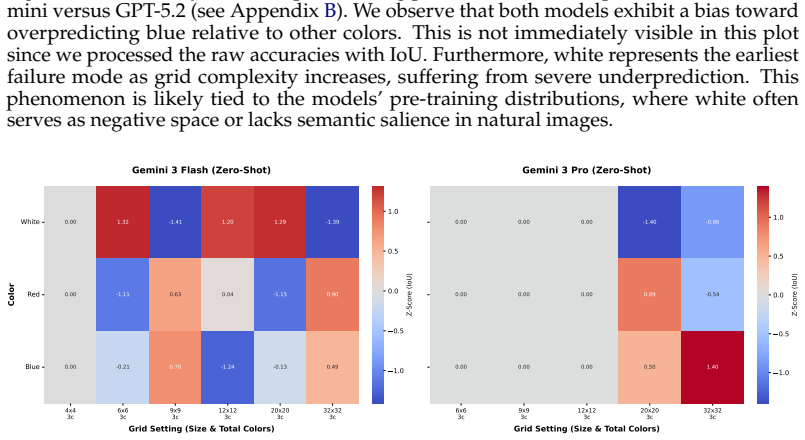
We introduce Grid2Matrix (G2M), a controlled benchmark in which a model is shown a color grid and a color-to-number mapping, and must output the corresponding matrix. By varying grid size and the number of colors, G2M provides a simple way to increase visual complexity while minimizing semantic confounds. We find that VLMs exhibit a sharp early collapse in zero-shot end-to-end evaluation, failing on surprisingly small grids rather than degrading gradually as the task becomes denser. We probe the visual encoders of VLMs from two representative families and find that they preserve substantially more of the grid information than the corresponding end-to-end outputs. This suggests that the gap,
What carries the argument
Grid2Matrix benchmark, which forces exhaustive visual-to-matrix readout on grids of controlled size and color count, together with the identified Digital Agnosia gap between preserved visual features and final language output.
If this is right
- VLMs cannot be trusted for tasks that require reading every cell of a table, chart, form, or GUI interface.
- Visual encoders must be probed separately from the language head to determine how much detail actually reaches the output stage.
- Many errors align with the fixed patch boundaries of the vision backbone rather than with grid content itself.
- Neither larger model size nor additional multimodal alignment training removes the failure mode on this class of inputs.
Where Pith is reading between the lines
- Similar controlled grids could be used to test whether other structured visual inputs, such as diagrams or maps, trigger the same encoder-to-language drop.
- Training objectives that explicitly reward cell-by-cell reconstruction might close the gap without requiring larger models.
- Systems that route visual features directly to an external symbolic decoder could bypass the language-side loss observed here.
Load-bearing premise
That varying grid size and number of colors raises visual complexity without semantic side effects, and that probing the visual encoder alone accurately measures what grid information is still available before the language head acts.
What would settle it
An experiment in which a model's end-to-end accuracy on grids matches or exceeds the accuracy of its isolated visual encoder probe on the same inputs, or in which accuracy remains high on grids larger than 6x6 without the reported early collapse.
Figures

























read the original abstract
Vision-Language Models (VLMs) excel on many multimodal reasoning benchmarks, but these evaluations often do not require an exhaustive readout of the image and can therefore obscure failures in faithfully capturing all visual details. We introduce Grid2Matrix (G2M), a controlled benchmark in which a model is shown a color grid and a color-to-number mapping, and must output the corresponding matrix. By varying grid size and the number of colors, G2M provides a simple way to increase visual complexity while minimizing semantic confounds. We find that VLMs exhibit a sharp early collapse in zero-shot end-to-end evaluation, failing on surprisingly small grids rather than degrading gradually as the task becomes denser. We probe the visual encoders of VLMs from two representative families and find that they preserve substantially more of the grid information than the corresponding end-to-end outputs. This suggests that the failure is not explained by visual encoding alone, but also reflects a gap between what remains recoverable from visual features and what is ultimately expressed in language. We term this gap \textit{Digital Agnosia}. Further analyses show that these errors are highly structured and depend strongly on how grid cells overlap with visual patch boundaries. We also find that common strategies such as model scaling and multimodal alignment do not fully eliminate this failure mode. We expect G2M to serve as a useful testbed for understanding where and how VLMs lose fine visual details, and for evaluating tasks where missing even small visual details can matter, such as tables, charts, forms, and GUIs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Grid2Matrix (G2M) benchmark, in which VLMs receive a color grid plus a color-to-number mapping and must output the corresponding numeric matrix. By varying grid size and color count, the authors observe a sharp collapse in zero-shot end-to-end accuracy on surprisingly small grids. Separate probing of the visual encoders recovers substantially more grid information than the language outputs, which the authors interpret as evidence of a gap they term 'Digital Agnosia'. Errors are shown to align with patch boundaries, and neither model scaling nor multimodal alignment fully resolves the failure.
Significance. If the central empirical pattern is robust, G2M supplies a simple, low-semantic-confound testbed for diagnosing where VLMs lose fine visual structure before it reaches the language head. The structured error analysis tied to patch boundaries and the explicit comparison between end-to-end prompting and visual probing are concrete strengths that could guide future work on tables, charts, and GUI understanding.
major comments (2)
- [Methods / Probing subsection] Methods / Probing subsection: the visual-probing results rely on trained classifiers or decoders fit to the frozen visual features, while the end-to-end evaluation remains strictly zero-shot prompting. This supervised-versus-unsupervised difference supplies an alternative explanation for the reported performance gap and therefore weakens the direct attribution to an intrinsic 'Digital Agnosia' between vision and language.
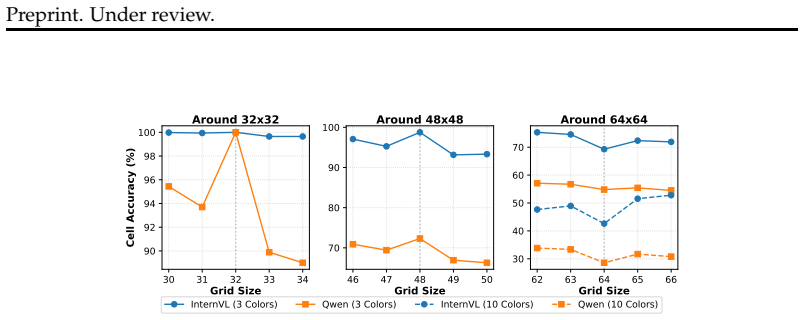
- [Results, zero-shot evaluation paragraph] Results, zero-shot evaluation paragraph: the claim that failure occurs on 'surprisingly small grids' and does not degrade gradually requires the exact grid sizes, color counts, and accuracy curves (including confidence intervals) to be shown; without these numbers it is difficult to judge whether the collapse is as abrupt as asserted or whether it simply tracks the point at which patch-level information becomes insufficient.
minor comments (2)
- [Introduction] The introduction of the term 'Digital Agnosia' would benefit from a brief discussion of how it differs from or overlaps with existing notions of visual grounding failure or detail loss already reported in the VLM literature.
- [Figures] Figure captions should explicitly state the number of models, grid sizes, and color cardinalities shown in each panel so that readers can interpret the plots without returning to the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below, indicating the revisions we will make.
read point-by-point responses
-
Referee: [Methods / Probing subsection] Methods / Probing subsection: the visual-probing results rely on trained classifiers or decoders fit to the frozen visual features, while the end-to-end evaluation remains strictly zero-shot prompting. This supervised-versus-unsupervised difference supplies an alternative explanation for the reported performance gap and therefore weakens the direct attribution to an intrinsic 'Digital Agnosia' between vision and language.
Authors: We acknowledge that the supervised nature of the visual probes (trained classifiers on frozen features) versus the strictly zero-shot end-to-end prompting is a methodological distinction that could contribute to the observed gap and should not be overlooked in attributing the failure to an intrinsic vision-language disconnect. Probing is intended to establish an upper bound on recoverable grid information from the visual encoder, but we agree this does not equate to a direct comparison. We will revise the Methods / Probing subsection to explicitly discuss this difference, qualify the interpretation of Digital Agnosia, and add a caveat that part of the gap may stem from the evaluation protocol rather than solely from an intrinsic bottleneck. We will also emphasize that the substantial information recovery via probing still indicates the visual features encode the grid structure beyond what zero-shot language outputs utilize. revision: partial
-
Referee: [Results, zero-shot evaluation paragraph] Results, zero-shot evaluation paragraph: the claim that failure occurs on 'surprisingly small grids' and does not degrade gradually requires the exact grid sizes, color counts, and accuracy curves (including confidence intervals) to be shown; without these numbers it is difficult to judge whether the collapse is as abrupt as asserted or whether it simply tracks the point at which patch-level information becomes insufficient.
Authors: We agree that explicit quantitative details are required to substantiate the claim of an abrupt collapse on small grids rather than gradual degradation. We will add a new table in the Results section listing the exact grid sizes tested, corresponding color counts, zero-shot accuracies, and 95% confidence intervals. We will also expand the zero-shot evaluation paragraph to directly reference this table and discuss the relationship to patch boundaries. This will allow readers to assess the sharpness of the performance drop and its alignment with visual patch constraints. revision: yes
Circularity Check
No circularity: purely empirical benchmark and probing study with independent measurements.
full rationale
The paper introduces the Grid2Matrix benchmark, runs zero-shot end-to-end VLM evaluations, and trains separate probes on visual encoder features to recover grid information. No equations, derivations, fitted parameters renamed as predictions, or self-citations are used to justify the central claim of a recoverable-vs-expressed gap (termed Digital Agnosia). All results follow directly from the described experimental protocol on held-out grids; the comparison between probing accuracy and zero-shot output is an external measurement rather than a self-referential reduction. Minor self-citations, if present, are not load-bearing for the reported findings.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption VLMs can be meaningfully decomposed into visual encoders and language components for separate probing.
invented entities (1)
-
Digital Agnosia
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Reshape:We reshape the sequence into a 2D spatial feature map of size (B, D, h, w), whereh=w= √ L
-
[2]
Interpolate:Because the native feature map resolution ( h×w ) cannot natively match every target grid density (N×N ), we apply bilinear interpolation to resize the feature map to the exactN×Ndimensions
-
[3]
Classification:We project the features using a 1 × 1 Convolutional Head. This is mathematically equivalent to training a shared linear classifier that sweeps across and operates on every grid cell independently. Y=Softmax(Conv 1×1(GELU(BN(Conv1×1(Xresized))))) The probe head projects the input dimension to a hidden dimension of 512, followed by Batch Norm...
-
[4]
Scan the grid row by row, from top to bottom
-
[5]
For each row, map every cell using the color mapping
-
[6]
Output Format: Return ONLY a Python list of lists (e.g., [[0, 1], [2, 0]])
Ensure the output has exactlyHrows andWcolumns. Output Format: Return ONLY a Python list of lists (e.g., [[0, 1], [2, 0]]). Do not use markdown, code blocks, or explanations. To prevent prompt instability, the color mapping dictionary is strictly sorted by its integer values before being injected into the prompt template. We enforce fully deterministic ge...
work page 2048
-
[7]
Strict Evaluation:We first attempt to directly parse the output stream as a valid Python array usingast.literal eval
-
[8]
Row-wise Regex:If standard parsing fails, we apply regular expressions to catch row-by-row structural patterns (e.g., ROW1=[...]), a format some models sponta- neously adopt when overwhelmed
-
[9]
Fallback Flattening:As a final contingency, we extract all integers from the text response. If the total integer count perfectly matches the expected H×W cells, we sequentially reshape this 1D array into the target 2D grid dimensions. If all three extraction methods fail, the sample is recorded as a complete parse error and yields a 0% Cell Accuracy for t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.