SpecMoE: A Fast and Efficient Mixture-of-Experts Inference via Self-Assisted Speculative Decoding
Pith reviewed 2026-05-10 16:34 UTC · model grok-4.3
The pith
SpecMoE applies self-assisted speculative decoding to speed up Mixture-of-Experts inference without any additional training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
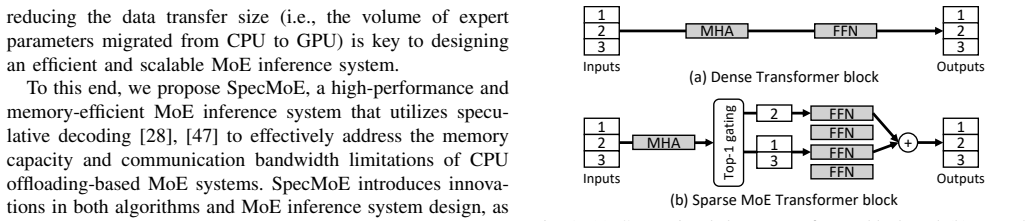
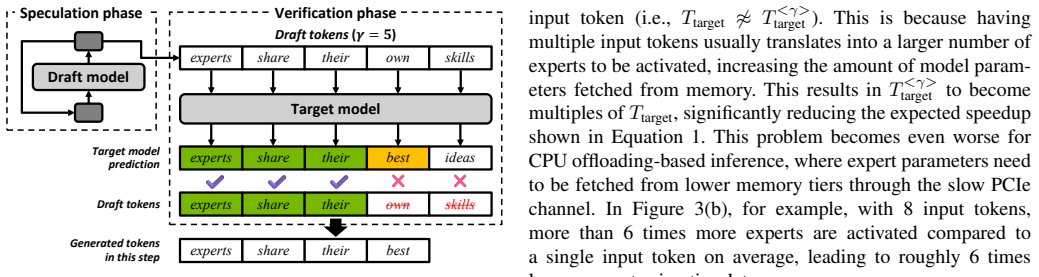
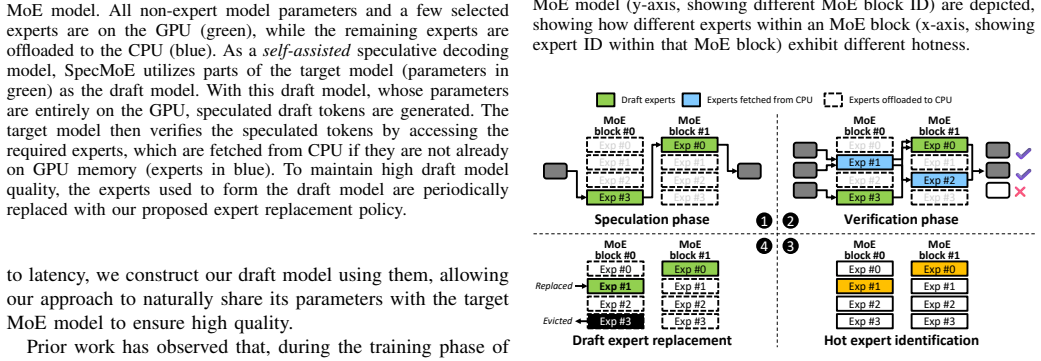
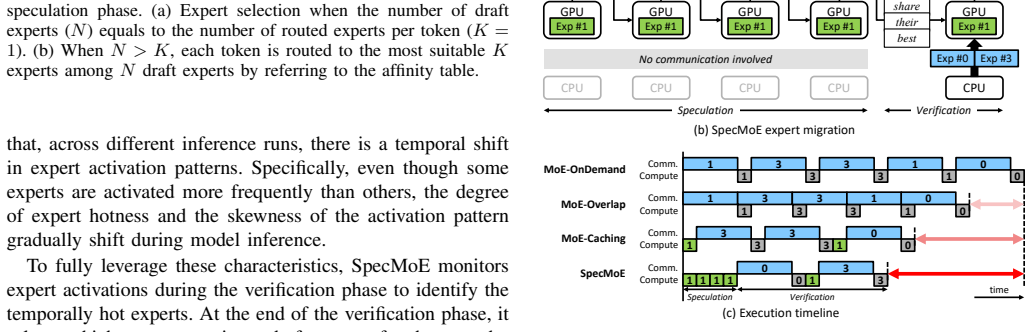
The core discovery is that applying speculative decoding in a self-assisted manner to existing Mixture-of-Experts models enables significant improvements in inference efficiency. Specifically, the system achieves up to 4.30 times higher throughput and markedly reduces the bandwidth requirements for memory and interconnects on memory-constrained systems, all without requiring additional model training or fine-tuning.
What carries the argument
The self-assisted speculative decoding algorithm, which generates draft tokens internally and verifies them against the full MoE model to accelerate inference while preserving accuracy.
If this is right
- Throughput improves by up to 4.30 times compared to baseline MoE inference.
- Memory and interconnect bandwidth requirements decrease substantially.
- Existing MoE models can be used directly without retraining or fine-tuning.
- The approach benefits CPU-offloaded systems particularly for larger batch sizes.
Where Pith is reading between the lines
- Such optimizations could make larger MoE models practical on devices with limited RAM or network bandwidth.
- Combining this with other techniques like model compression might yield further gains.
- The self-assisted aspect avoids the need for separate draft models, simplifying deployment.
Load-bearing premise
That the speculative decoding technique works effectively on MoE architectures without any model-specific training and that the measured speedups and bandwidth savings apply beyond the tested setups.
What would settle it
Observing no throughput improvement or increased errors when applying the self-assisted speculative decoding to an MoE model on standard hardware would falsify the effectiveness claim.
Figures









read the original abstract
The Mixture-of-Experts (MoE) architecture has emerged as a promising approach to mitigate the rising computational costs of large language models (LLMs) by selectively activating parameters. However, its high memory requirements and sub-optimal parameter efficiency pose significant challenges for efficient deployment. Although CPU-offloaded MoE inference systems have been proposed in the literature, they offer limited efficiency, particularly for large batch sizes. In this work, we propose SpecMoE, a memory-efficient MoE inference system based on our self-assisted speculative decoding algorithm. SpecMoE demonstrates the effectiveness of applying speculative decoding to MoE inference without requiring additional model training or fine-tuning. Our system improves inference throughput by up to $4.30\times$, while significantly reducing bandwidth requirements of both memory and interconnect on memory-constrained systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SpecMoE, a memory-efficient inference system for Mixture-of-Experts (MoE) models based on a self-assisted speculative decoding algorithm. The approach applies speculative decoding directly to existing MoE models without additional training or fine-tuning, claiming throughput improvements of up to 4.30× along with reduced memory and interconnect bandwidth requirements on memory-constrained systems.
Significance. If the results hold and generalize, the work could meaningfully advance practical deployment of large MoE LLMs on resource-limited hardware by addressing memory bottlenecks without retraining overhead. The no-training, self-assisted design is a clear strength that distinguishes it from methods requiring auxiliary models.
major comments (2)
- Abstract: The performance claims (up to 4.30× throughput and bandwidth reductions) are stated without any description of experimental setup, specific MoE models (expert count, top-k routing), hardware, baselines, batch sizes, or error bars/variance, preventing assessment of the central claims.
- Self-assisted speculative decoding algorithm (described in the proposed method section): The algorithm generates draft tokens from the target MoE itself, but provides no acceptance-rate analysis or ablations demonstrating robustness to input-dependent expert routing variations (e.g., top-1 vs. top-2, different capacity factors). This is load-bearing for the generalization claim to arbitrary MoE architectures and the reported speedups.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our results and strengthen the analysis of the proposed algorithm. We address each major comment below and will revise the manuscript to incorporate additional details and analysis.
read point-by-point responses
-
Referee: Abstract: The performance claims (up to 4.30× throughput and bandwidth reductions) are stated without any description of experimental setup, specific MoE models (expert count, top-k routing), hardware, baselines, batch sizes, or error bars/variance, preventing assessment of the central claims.
Authors: We agree that the abstract would benefit from more context on the experimental conditions supporting the claims. In the revised manuscript, we will expand the abstract to include brief descriptions of the evaluated MoE models (including expert counts and routing parameters such as top-k), the hardware platforms used, the baselines, typical batch sizes, and note that variance is reported in the main experimental results section. revision: yes
-
Referee: Self-assisted speculative decoding algorithm (described in the proposed method section): The algorithm generates draft tokens from the target MoE itself, but provides no acceptance-rate analysis or ablations demonstrating robustness to input-dependent expert routing variations (e.g., top-1 vs. top-2, different capacity factors). This is load-bearing for the generalization claim to arbitrary MoE architectures and the reported speedups.
Authors: We acknowledge that explicit acceptance-rate analysis and routing ablations would strengthen the generalization claims. The self-assisted design uses the target model for drafting, so routing variations are handled by the same expert selection mechanism. To address this directly, we will add acceptance-rate measurements and ablations across different top-k values and capacity factors in the revised manuscript, demonstrating the robustness of the speedups. revision: yes
Circularity Check
No circularity; empirical system evaluation is self-contained
full rationale
The paper presents SpecMoE as an applied system for MoE inference that uses self-assisted speculative decoding without training or fine-tuning. Central claims rest on measured throughput gains (up to 4.30×) and bandwidth reductions on tested models/hardware. No mathematical derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. Results are independently verifiable via replication on the same setups, with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Speculative decoding techniques transfer effectively to MoE architectures without model changes or retraining.
invented entities (1)
-
Self-assisted speculative decoding algorithm
no independent evidence
Reference graph
Works this paper leans on
-
[1]
SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills,
A. Agrawal, A. Panwar, J. Mohan, N. Kwatra, B. S. Gulavani, and R. Ramjee, “SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills,” inarxiv.org, 2023
work page 2023
-
[2]
GQA: Training Generalized Multi-query Transformer Models from Multi-Head Checkpoints,
J. Ainslie, J. Lee-Thorp, M. de Jong, Y . Zemlyanskiy, F. Lebr ´on, and S. Sanghai, “GQA: Training Generalized Multi-query Transformer Models from Multi-Head Checkpoints,” inarxiv.org, 2023
work page 2023
-
[3]
DeepSpeed- Inference: Enabling Efficient Inference of Transformer Models at Un- precedented Scale,
R. Y . Aminabadi, S. Rajbhandari, A. A. Awan, C. Li, D. Li, E. Zheng, O. Ruwase, S. Smith, M. Zhang, J. Rasley, and Y . He, “DeepSpeed- Inference: Enabling Efficient Inference of Transformer Models at Un- precedented Scale,” inProceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis (SC), 2022
work page 2022
-
[4]
Findings of the 2014 Workshop on Statistical Ma- chine Translation,
O. Bojar, C. Buck, C. Federmann, B. Haddow, P. Koehn, J. Leveling, C. Monz, P. Pecina, M. Post, H. Saint-Amand, R. Soricut, L. Specia, and A. Tamchyna, “Findings of the 2014 Workshop on Statistical Ma- chine Translation,” inProceedings of the Ninth Workshop on Statistical Machine Translation, 2014
work page 2014
-
[5]
Language Models are Few-shot Learners,
T. B. Brown, “Language Models are Few-shot Learners,” inarxiv.org, 2020
work page 2020
-
[6]
Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads,
T. Cai, Y . Li, Z. Geng, H. Peng, J. D. Lee, D. Chen, and T. Dao, “Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads,” inarxiv.org, 2024
work page 2024
-
[7]
Accelerating Large Language Model Decoding with Speculative Sam- pling,
C. Chen, S. Borgeaud, G. Irving, J.-B. Lespiau, L. Sifre, and J. Jumper, “Accelerating Large Language Model Decoding with Speculative Sam- pling,” inarxiv.org, 2023
work page 2023
-
[8]
Punica: Multi-tenant LoRA Serving,
L. Chen, Z. Ye, Y . Wu, D. Zhuo, L. Ceze, and A. Krishnamurthy, “Punica: Multi-tenant LoRA Serving,”Proceedings of Machine Learning and Systems, 2024
work page 2024
-
[9]
Sequoia: Scalable, Robust, and Hardware-aware Speculative Decoding,
Z. Chen, A. May, R. Svirschevski, Y . Huang, M. Ryabinin, Z. Jia, and B. Chen, “Sequoia: Scalable, Robust, and Hardware-aware Speculative Decoding,” inarxiv.org, 2024
work page 2024
-
[10]
DeepSeek- R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning,
DeepSeek-AI, D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Bi, X. Zhang, X. Yu, Y . Wu, Z. F. Wu, Z. Gou, Z. Shao, Z. Li, Z. Gao, A. Liu, B. Xue, B. Wang, B. Wu, B. Feng, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruan, D. Dai, D. Chen, D. Ji, E. Li, F. Lin, F. Dai, F. Luo, G. Hao, G. Chen, G. Li, H. Zhang, H. Bao, H. Xu, H. W...
work page 2025
-
[11]
LayerSkip: Enabling Early Exit Inference and Self-speculative Decoding,
M. Elhoushi, A. Shrivastava, D. Liskovich, B. Hosmer, B. Wasti, L. Lai, A. Mahmoud, B. Acun, S. Agarwal, A. Roman, A. Aly, B. Chen, and C.- J. Wu, “LayerSkip: Enabling Early Exit Inference and Self-speculative Decoding,” inarxiv.org, 2024
work page 2024
-
[12]
Fast Inference of Mixture-of-Experts Lan- guage Models with Offloading,
A. Eliseev and D. Mazur, “Fast Inference of Mixture-of-Experts Lan- guage Models with Offloading,” inarxiv.org, 2023
work page 2023
-
[13]
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity,
W. Fedus, B. Zoph, and N. Shazeer, “Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity,”Journal of Machine Learning Research, 2022
work page 2022
-
[14]
Gemini: A Family of Highly Capable Multimodal Models,
G. T. Google, “Gemini: A Family of Highly Capable Multimodal Models,” inarxiv.org, 2023
work page 2023
-
[15]
Gemini 1.5: Unlocking Multimodal Understanding Across Mil- lions of Tokens of Context,
——, “Gemini 1.5: Unlocking Multimodal Understanding Across Mil- lions of Tokens of Context,” inarxiv.org, 2024
work page 2024
-
[16]
Teaching Machines to Read and Comprehend,
K. M. Hermann, T. Kocisk ´y, E. Grefenstette, L. Espeholt, W. Kay, M. Suleyman, and P. Blunsom, “Teaching Machines to Read and Comprehend,” inProceedings of the International Conference on Neural Information Processing Systems (NeurIPS), 2015
work page 2015
-
[17]
Training Compute-Optimal Large Language Models,
J. Hoffmann, S. Borgeaud, A. Mensch, E. Buchatskaya, T. Cai, E. Rutherford, D. de Las Casas, L. A. Hendricks, J. Welbl, A. Clark, T. Hennigan, E. Noland, K. Millican, G. van den Driessche, B. Damoc, A. Guy, S. Osindero, K. Simonyan, E. Elsen, J. W. Rae, O. Vinyals, and L. Sifre, “Training Compute-Optimal Large Language Models,” in arxiv.org, 2022
work page 2022
-
[18]
Speed: Speculative Pipelined Execution for Efficient Decoding,
C. Hooper, S. Kim, H. Mohammadzadeh, H. Genc, K. Keutzer, A. Gho- lami, and S. Shao, “Speed: Speculative Pipelined Execution for Efficient Decoding,” inarxiv.org, 2023
work page 2023
-
[19]
Towards MoE Deployment: Mitigating Inefficiencies in Mixture-of-Expert (MoE) Inference,
H. Huang, N. Ardalani, A. Sun, L. Ke, H.-H. S. Lee, A. Sridhar, S. Bhos- ale, C.-J. Wu, and B. Lee, “Towards MoE Deployment: Mitigating Inefficiencies in Mixture-of-Expert (MoE) Inference,” inarxiv.org, 2023
work page 2023
-
[20]
HuggingFace, “Hugging Face Accelerate,” 2022. [Online]. Available: https://huggingface.co/docs/accelerate/index
work page 2022
-
[21]
Tutel: Adaptive Mixture-of-Experts at Scale,
C. Hwang, W. Cui, Y . Xiong, Z. Yang, Z. Liu, H. Hu, Z. Wang, R. Salas, J. Jose, P. Ram, J. Chau, P. Cheng, F. Yang, M. Yang, and Y . Xiong, “Tutel: Adaptive Mixture-of-Experts at Scale,” inarxiv.org, 2023
work page 2023
-
[22]
Pre-gated MoE: An Algorithm-system Co-design for Fast and Scal- able Mixture-of-Expert Inference,
R. Hwang, J. Wei, S. Cao, C. Hwang, X. Tang, T. Cao, and M. Yang, “Pre-gated MoE: An Algorithm-system Co-design for Fast and Scal- able Mixture-of-Expert Inference,” inProceedings of the International Symposium on Computer Architecture (ISCA), 2024
work page 2024
-
[23]
A. Q. Jiang, A. Sablayrolles, A. Roux, A. Mensch, B. Savary, C. Bam- ford, D. S. Chaplot, D. de las Casas, E. B. Hanna, F. Bressand, G. Lengyel, G. Bour, G. Lample, L. R. Lavaud, L. Saulnier, M.-A. Lachaux, P. Stock, S. Subramanian, S. Yang, S. Antoniak, T. L. Scao, T. Gervet, T. Lavril, T. Wang, T. Lacroix, and W. E. Sayed, “Mixtral of Experts,” inarxiv....
work page 2024
-
[24]
Scaling Laws for Neural Language Models,
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei, “Scaling Laws for Neural Language Models,” inarxiv.org, 2020
work page 2020
-
[25]
Scaling Laws for Neural Language Models,
——, “Scaling Laws for Neural Language Models,” inarxiv.org, 2020
work page 2020
-
[26]
Efficient Memory Management for Large Language Model Serving with PagedAttention,
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. Gonzalez, H. Zhang, and I. Stoica, “Efficient Memory Management for Large Language Model Serving with PagedAttention,” inProceedings of the ACM Symposium on Operating System Principles (SOSP), 2023
work page 2023
-
[27]
GShard: Scaling Giant Models with Condi- tional Computation and Automatic Sharding,
D. Lepikhin, H. Lee, Y . Xu, D. Chen, O. Firat, Y . Huang, M. Krikun, N. Shazeer, and Z. Chen, “GShard: Scaling Giant Models with Condi- tional Computation and Automatic Sharding,” inarxiv.org, 2020
work page 2020
-
[28]
Fast Inference from Trans- formers via Speculative Decoding,
Y . Leviathan, M. Kalman, and Y . Matias, “Fast Inference from Trans- formers via Speculative Decoding,” inProceedings of the International Conference on Machine Learning (ICML), 2023
work page 2023
-
[29]
EAGLE: Speculative Sam- pling Requires Rethinking Feature Uncertainty,
Y . Li, F. Wei, C. Zhang, and H. Zhang, “EAGLE: Speculative Sam- pling Requires Rethinking Feature Uncertainty,” inProceedings of the International Conference on Machine Learning (ICML), 2024
work page 2024
-
[30]
Llama 4 and Multimodal AI: Expanding Intelligence Across Modalities,
Meta AI, “Llama 4 and Multimodal AI: Expanding Intelligence Across Modalities,” 2024. [Online]. Available: https://ai.meta.com/blog/llama- 4-multimodal-intelligence/
work page 2024
-
[31]
X. Miao, G. Oliaro, Z. Zhang, X. Cheng, Z. Wang, Z. Zhang, R. Y . Y . Wong, A. Zhu, L. Yang, X. Shi, C. Shi, Z. Chen, D. Arfeen, R. Ab- hyankar, and Z. Jia, “Specinfer: Accelerating Large Language Model Serving with Tree-based Speculative Inference and Verification,” in Proceedings of the International Conference on Architectural Support for Programming L...
work page 2024
- [32]
-
[33]
Characterizing Power Management Opportunities for LLMs in the Cloud,
P. Patel, E. Choukse, C. Zhang, ´I. Goiri, B. Warrier, N. Mahalingam, and R. Bianchini, “Characterizing Power Management Opportunities for LLMs in the Cloud,” inProceedings of the International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2024
work page 2024
-
[34]
Splitwise: Efficient Generative LLM Inference using Phase Splitting,
P. Patel, E. Choukse, C. Zhang, A. Shah, ´I. Goiri, S. Maleki, and R. Bianchini, “Splitwise: Efficient Generative LLM Inference using Phase Splitting,” inProceedings of the International Symposium on Computer Architecture (ISCA), 2024
work page 2024
-
[35]
Scaling Language Mod- els: Methods, Analysis & Insights from Training Gopher,
J. W. Rae, S. Borgeaud, T. Cai, K. Millican, J. Hoffmann, F. Song, J. Aslanides, S. Henderson, R. Ring, S. Young, E. Rutherford, T. Hen- nigan, J. Menick, A. Cassirer, R. Powell, G. van den Driessche, L. A. Hendricks, M. Rauh, P.-S. Huang, A. Glaese, J. Welbl, S. Dathathri, S. Huang, J. Uesato, J. Mellor, I. Higgins, A. Creswell, N. McAleese, A. Wu, E. El...
work page 2022
-
[36]
S. Rajbhandari, C. Li, Z. Yao, M. Zhang, R. Y . Aminabadi, A. A. Awan, J. Rasley, and Y . He, “Deepspeed-MoE: Advancing Mixture-of- Experts Inference and Training to Power Next-generation AI Scale,” inProceedings of the International Conference on Machine Learning (ICML), 2022
work page 2022
-
[37]
Zero- Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning,
S. Rajbhandari, O. Ruwase, J. Rasley, S. Smith, and Y . He, “Zero- Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning,” inProceedings of the international conference for high performance computing, networking, storage and analysis, 2021
work page 2021
-
[38]
ZeRO-Offload: Democratizing Billion-scale Model Training,
J. Ren, S. Rajbhandari, R. Y . Aminabadi, O. Ruwase, S. Yang, M. Zhang, D. Li, and Y . He, “ZeRO-Offload: Democratizing Billion-scale Model Training,” inUSENIX Annual Technical Conference (ATC), 2021
work page 2021
-
[39]
SambaNova Systems, “Speculative decoding,” 2025. [Online]. Available: https://docs.sambanova.ai/sambastudio/latest/spec-decoding. html# choosing a draft model
work page 2025
-
[40]
Get to The Point: Summarization with Pointer-generator Networks,
A. See, P. J. Liu, and C. D. Manning, “Get to The Point: Summarization with Pointer-generator Networks,” inProceedings of the ACL (Associa- tion for Computational Linguistics), 2017
work page 2017
-
[41]
Outrageously Large Neural Networks: The Sparsely-gated Mixture-of-Experts Layer,
N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. Le, G. Hinton, and J. Dean, “Outrageously Large Neural Networks: The Sparsely-gated Mixture-of-Experts Layer,” inarxiv.org, 2017
work page 2017
-
[42]
S-LoRA: Serving Thousands of Concurrent Lora Adapters,
Y . Sheng, S. Cao, D. Li, C. Hooper, N. Lee, S. Yang, C. Chou, B. Zhu, L. Zheng, K. Keutzer, J. E. Gonzalez, and I. Stoica, “S-LoRA: Serving Thousands of Concurrent Lora Adapters,” inarxiv.org, 2023
work page 2023
-
[43]
FlexGen: High-throughput Generative Inference of Large Language Models with a Single GPU,
Y . Sheng, L. Zheng, B. Yuan, Z. Li, M. Ryabinin, D. Y . Fu, Z. Xie, B. Chen, C. Barrett, J. E. Gonzalez, P. Liang, C. R ´e, I. Stoica, and C. Zhang, “FlexGen: High-throughput Generative Inference of Large Language Models with a Single GPU,” inarxiv.org, 2023
work page 2023
-
[44]
Scaling LLM Test-time Compute Optimally can be More Effective Than Scaling Model Parameters,
C. Snell, J. Lee, K. Xu, and A. Kumar, “Scaling LLM Test-time Compute Optimally can be More Effective Than Scaling Model Parameters,” in arxiv.org, 2024
work page 2024
-
[45]
PowerInfer: Fast Large Language Model Serving with a Consumer-grade GPU,
Y . Song, Z. Mi, H. Xie, and H. Chen, “PowerInfer: Fast Large Language Model Serving with a Consumer-grade GPU,” inProceedings of the ACM Symposium on Operating System Principles (SOSP), 2024
work page 2024
-
[46]
Accelerating LLM Inference with Staged Speculative Decoding,
B. Spector and C. Re, “Accelerating LLM Inference with Staged Speculative Decoding,” inarxiv.org, 2023
work page 2023
-
[47]
Blockwise Parallel Decoding for Deep Autoregressive Models,
M. Stern, N. Shazeer, and J. Uszkoreit, “Blockwise Parallel Decoding for Deep Autoregressive Models,”Advances in Neural Information Processing Systems, 2018
work page 2018
-
[48]
SpecExec: Massively Parallel Speculative Decoding For Interactive LLM Inference on Consumer Devices,
R. Svirschevski, A. May, Z. Chen, B. Chen, Z. Jia, and M. Ryabinin, “SpecExec: Massively Parallel Speculative Decoding For Interactive LLM Inference on Consumer Devices,” inProceedings of the Interna- tional Conference on Neural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[49]
No Language Left Behind: Scaling Human-centered Machine Translation,
N. Team, M. R. Costa-juss `a, J. Cross, O. C ¸ elebi, M. Elbayad, K. Heafield, K. Heffernan, E. Kalbassi, J. Lam, D. Licht, J. Maillard, A. Sun, S. Wang, G. Wenzek, A. Youngblood, B. Akula, L. Barrault, G. M. Gonzalez, P. Hansanti, J. Hoffman, S. Jarrett, K. R. Sadagopan, D. Rowe, S. Spruit, C. Tran, P. Andrews, N. F. Ayan, S. Bhosale, S. Edunov, A. Fan, ...
work page 2022
-
[50]
LLaMA: Open and Efficient Foundation Language Models,
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozi `ere, N. Goyal, E. Hambro, F. Azhar, A. Rodriguez, A. Joulin, E. Grave, and G. Lample, “LLaMA: Open and Efficient Foundation Language Models,” inarxiv.org, 2023
work page 2023
-
[51]
APTMoE: Affinity-aware Pipeline Tuning for MoE Models on Bandwidth-constrained GPU Nodes,
Y . Wei, J. Du, J. Jiang, X. Shi, X. Zhang, D. Huang, N. Xiao, and Y . Lu, “APTMoE: Affinity-aware Pipeline Tuning for MoE Models on Bandwidth-constrained GPU Nodes,” inProceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis (SC), 2024
work page 2024
-
[52]
HuggingFace’s Transformers: State-of-the-art Natural Language Processing,
T. Wolf, L. Debut, V . Sanh, J. Chaumond, C. Delangue, A. Moi, P. Cistac, T. Rault, R. Louf, M. Funtowicz, J. Davison, S. Shleifer, P. von Platen, C. Ma, Y . Jernite, J. Plu, C. Xu, T. L. Scao, S. Gugger, M. Drame, Q. Lhoest, and A. M. Rush, “HuggingFace’s Transformers: State-of-the-art Natural Language Processing,” inarxiv.org, 2020
work page 2020
-
[53]
{dLoRA}: Dynamically Orchestrating Requests and Adapters for{LoRA}{LLM} Serving,
B. Wu, R. Zhu, Z. Zhang, P. Sun, X. Liu, and X. Jin, “{dLoRA}: Dynamically Orchestrating Requests and Adapters for{LoRA}{LLM} Serving,” inProceedings of the USENIX Symposium on Operating Systems Design and Implementation (OSDI), 2024
work page 2024
-
[54]
EdgeLLM: Fast On-Device LLM Inference With Speculative Decoding,
D. Xu, W. Yin, H. Zhang, X. Jin, Y . Zhang, S. Wei, M. Xu, and X. Liu, “EdgeLLM: Fast On-Device LLM Inference With Speculative Decoding,”IEEE Transactions on Mobile Computing, 2024
work page 2024
-
[55]
EdgeMoE: Fast On-device Inference of MoE-based Large Language Models,
R. Yi, L. Guo, S. Wei, A. Zhou, S. Wang, and M. Xu, “EdgeMoE: Fast On-device Inference of MoE-based Large Language Models,” in arxiv.org, 2023
work page 2023
-
[56]
D. Yu, L. Shen, H. Hao, W. Gong, H. Wu, J. Bian, L. Dai, and H. Xiong, “MoESys: A Distributed and Efficient Mixture-of-Experts Training and Inference System for Internet Services,” inarxiv.org, 2022
work page 2022
-
[57]
Orca: A Distributed Serving System for{Transformer-based}Generative Mod- els,
G.-I. Yu, J. S. Jeong, G.-W. Kim, S. Kim, and B.-G. Chun, “Orca: A Distributed Serving System for{Transformer-based}Generative Mod- els,” inProceedings of the USENIX Symposium on Operating Systems Design and Implementation (OSDI), 2022
work page 2022
-
[58]
S. Yun, K. Kyung, J. Cho, J. Choi, J. Kim, B. Kim, S. Lee, K. Sohn, and J. H. Ahn, “Duplex: A Device for Large Language Models with Mixture of Experts, Grouped Query Attention, and Continuous Batching,” in arxiv.org, 2024
work page 2024
-
[59]
Draft & Verify: Lossless Large Language Model Acceleration via Self- speculative decoding,
J. Zhang, J. Wang, H. Li, L. Shou, K. Chen, G. Chen, and S. Mehrotra, “Draft & Verify: Lossless Large Language Model Acceleration via Self- speculative decoding,” inarxiv.org, 2023
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.