Audio-Omni: Extending Multi-modal Understanding to Versatile Audio Generation and Editing
Pith reviewed 2026-05-10 15:24 UTC · model grok-4.3
The pith
Audio-Omni unifies audio understanding, generation, and editing across sound, music, and speech in one end-to-end system.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
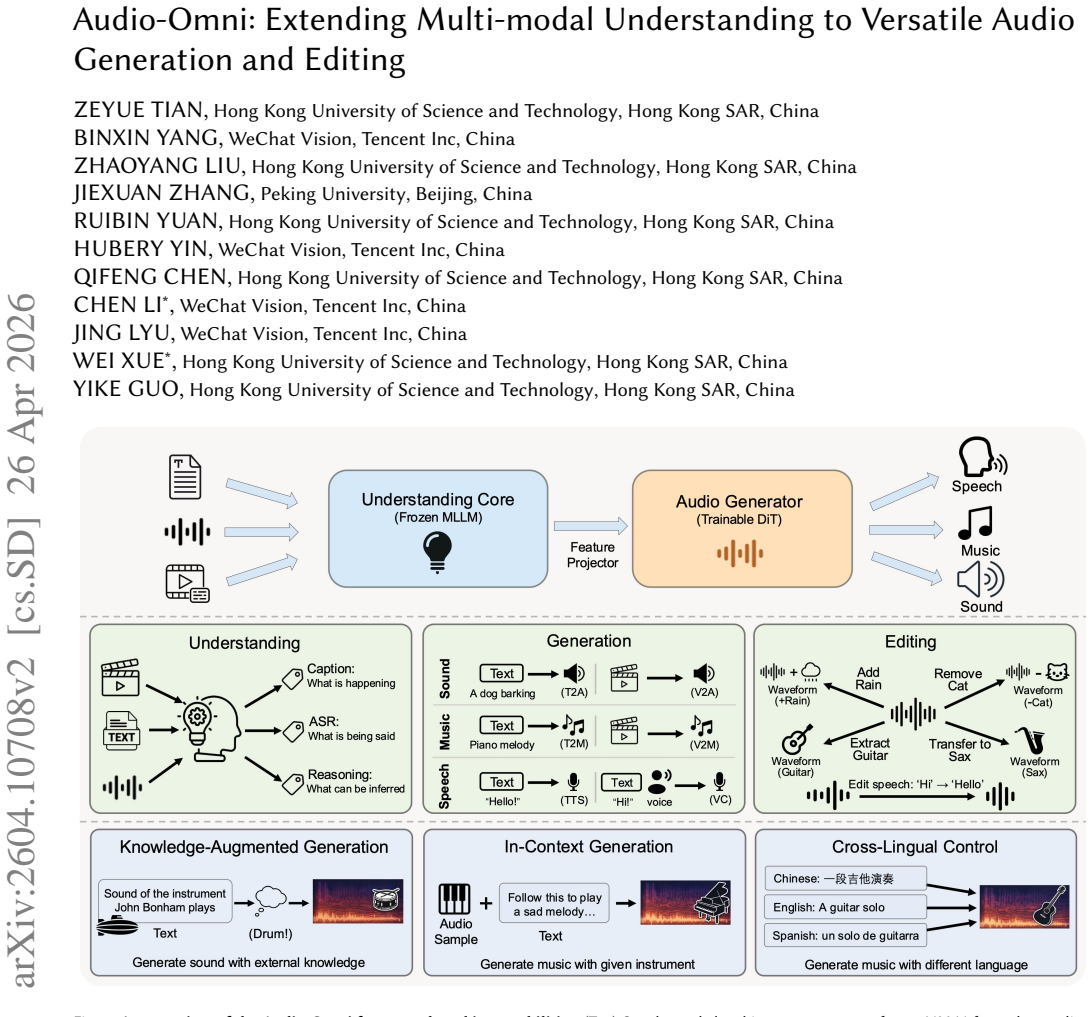
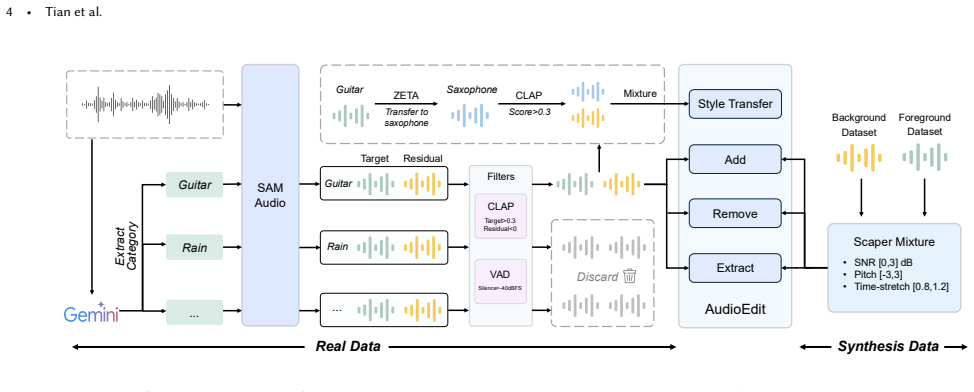
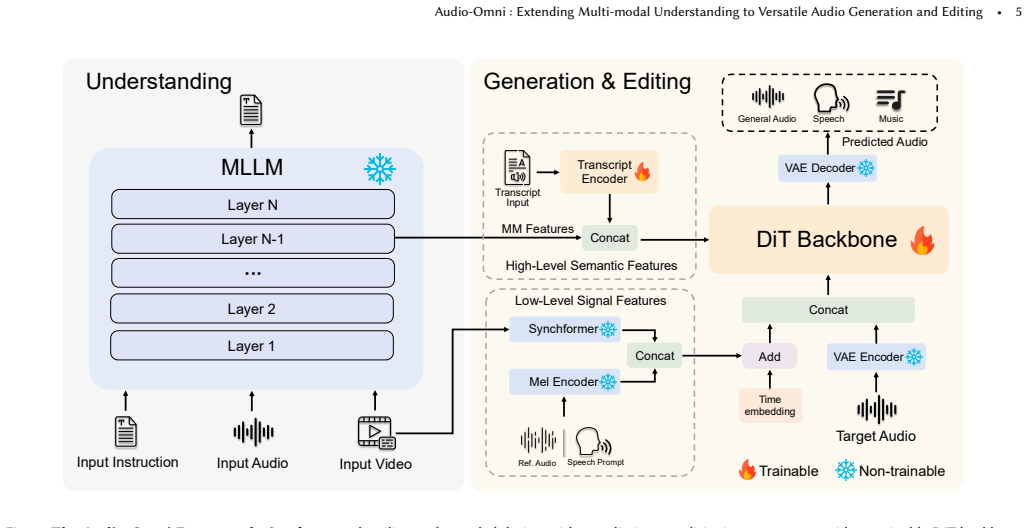
Audio-Omni is the first end-to-end framework that unifies generation and editing across general sound, music, and speech domains while adding integrated multi-modal understanding. It pairs a frozen Multimodal Large Language Model for high-level reasoning with a trainable Diffusion Transformer for high-fidelity synthesis. The authors address data scarcity by building the AudioEdit dataset containing more than one million curated editing pairs. Experiments show the model reaches state-of-the-art results on multiple benchmarks, matches or exceeds specialized expert models in their domains, and displays inherited abilities such as knowledge-augmented reasoning generation, in-context generation,零
What carries the argument
The central mechanism is the pairing of a frozen Multimodal Large Language Model for reasoning with a trainable Diffusion Transformer for synthesis, backed by the AudioEdit dataset of over one million editing pairs.
If this is right
- Audio-Omni reaches state-of-the-art performance on a suite of audio generation and editing benchmarks.
- The system outperforms earlier unified models and performs at or above the level of specialized expert models.
- It exhibits additional capabilities including knowledge-augmented reasoning generation, in-context generation, and zero-shot cross-lingual control.
- Public release of the code, model, and dataset supports further work toward universal generative audio systems.
Where Pith is reading between the lines
- If the frozen-reasoner plus trainable-synthesizer pattern succeeds here, the same structure could be tested for unifying video generation and editing tasks.
- Practical audio editing software could shift toward accepting open-ended natural language instructions instead of requiring technical parameters.
- The approach suggests that large-scale curated editing datasets may be the main remaining bottleneck for building versatile audio models.
Load-bearing premise
A frozen multimodal large language model combined with a trainable diffusion transformer can deliver seamless integration of reasoning and audio synthesis without domain-specific fine-tuning or extra components.
What would settle it
A controlled test in which the model receives editing instructions that require precise acoustic details absent from the AudioEdit dataset and produces clearly lower-quality results than existing specialized editing models.
Figures

read the original abstract
Recent progress in multimodal models has spurred rapid advances in audio understanding, generation, and editing. However, these capabilities are typically addressed by specialized models, leaving the development of a truly unified framework that can seamlessly integrate all three tasks underexplored. While some pioneering works have explored unifying audio understanding and generation, they often remain confined to specific domains. To address this, we introduce Audio-Omni, the first end-to-end framework to unify generation and editing across general sound, music, and speech domains, with integrated multi-modal understanding capabilities. Our architecture synergizes a frozen Multimodal Large Language Model for high-level reasoning with a trainable Diffusion Transformer for high-fidelity synthesis. To overcome the critical data scarcity in audio editing, we construct AudioEdit, a new large-scale dataset comprising over one million meticulously curated editing pairs. Extensive experiments demonstrate that Audio-Omni achieves state-of-the-art performance across a suite of benchmarks, outperforming prior unified approaches while achieving performance on par with or superior to specialized expert models. Beyond its core capabilities, Audio-Omni exhibits remarkable inherited capabilities, including knowledge-augmented reasoning generation, in-context generation, and zero-shot cross-lingual control for audio generation, highlighting a promising direction toward universal generative audio intelligence. The code, model, and dataset will be publicly released on https://zeyuet.github.io/Audio-Omni.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Audio-Omni, the first end-to-end framework to unify generation and editing across general sound, music, and speech domains while integrating multi-modal understanding. It combines a frozen Multimodal Large Language Model for high-level reasoning with a trainable Diffusion Transformer for synthesis, constructs the AudioEdit dataset of over one million editing pairs to address data scarcity, and claims state-of-the-art performance on benchmarks that matches or exceeds specialized expert models, along with emergent capabilities such as knowledge-augmented reasoning generation, in-context generation, and zero-shot cross-lingual control.
Significance. If the central claims hold, the work would mark a meaningful step toward universal generative audio intelligence by showing that a single unified model can handle diverse tasks and domains without per-domain fine-tuning. The planned public release of code, model, and dataset is a clear strength that would support reproducibility and community follow-up.
major comments (2)
- [Architecture] The architecture section does not detail the precise conditioning mechanism (e.g., cross-attention implementation, presence or absence of domain tokens or adapters) between the frozen MLLM embeddings and the single DiT; this is load-bearing for the claim that high-level reasoning seamlessly produces high-fidelity output across acoustically dissimilar domains (harmonic structure in music versus formant control in speech) without degradation or mode collapse.
- [Experiments] The experiments section asserts SOTA results and superiority over prior unified approaches but supplies no information on chosen baselines, exact metrics, number of runs or statistical significance tests, or analysis of curation biases and coverage in the AudioEdit dataset; without these, the performance claims central to the paper cannot be evaluated.
minor comments (1)
- [Abstract] The abstract would be clearer if it named the specific benchmarks on which SOTA performance is reported.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which has helped clarify key aspects of our work. We address each major comment below and have revised the manuscript accordingly to improve technical detail and experimental transparency.
read point-by-point responses
-
Referee: [Architecture] The architecture section does not detail the precise conditioning mechanism (e.g., cross-attention implementation, presence or absence of domain tokens or adapters) between the frozen MLLM embeddings and the single DiT; this is load-bearing for the claim that high-level reasoning seamlessly produces high-fidelity output across acoustically dissimilar domains (harmonic structure in music versus formant control in speech) without degradation or mode collapse.
Authors: We agree that the original description was high-level and insufficient for reproducing the cross-domain behavior. In the revised manuscript, we have added a new subsection (Section 3.2) with a detailed diagram and equations specifying the conditioning: MLLM embeddings are projected via a linear layer and injected as keys/values into multi-head cross-attention blocks within the DiT at every layer. No domain tokens are employed; domain handling emerges from the MLLM's reasoning over the prompt. To address potential mode collapse across dissimilar acoustics, we introduce lightweight, learnable domain adapters (one per broad category: sound/music/speech) that modulate the DiT's scale/shift parameters based on an inferred domain embedding. This design choice is now explicitly justified with reference to our ablation studies showing degradation when adapters are removed. revision: yes
-
Referee: [Experiments] The experiments section asserts SOTA results and superiority over prior unified approaches but supplies no information on chosen baselines, exact metrics, number of runs or statistical significance tests, or analysis of curation biases and coverage in the AudioEdit dataset; without these, the performance claims central to the paper cannot be evaluated.
Authors: We acknowledge these gaps in the original submission. The revised Experiments section (Section 4) now includes: an exhaustive table of baselines (both unified models such as AudioGen and domain-specific experts such as MusicGen and SpeechT5, with citations); precise metric definitions and computation details (FAD, CLAP score, MOS, etc.); results reported as mean ± std over 5 random seeds with Wilcoxon signed-rank tests for significance (p-values provided); and a dedicated dataset analysis subsection reporting domain coverage statistics (e.g., 42% music, 35% speech, 23% general sound), editing operation distribution, and explicit discussion of curation biases (e.g., prompt length skew) together with mitigation steps taken during collection. revision: yes
Circularity Check
No circularity detected; architecture and results rest on external benchmarks and new dataset construction
full rationale
The paper presents Audio-Omni as a new architecture (frozen MLLM + trainable DiT) and a newly curated AudioEdit dataset, with performance evaluated on external benchmarks. No equations, derivations, or load-bearing steps reduce by construction to fitted inputs, self-definitions, or self-citation chains. Claims of unification and SOTA results are empirical rather than tautological, with no imported uniqueness theorems or ansatzes from prior author work that would force the outcome. This is a standard non-circular model-description paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Stable audio open.arXiv preprint arXiv:2407.14358(2024). Deepanway Ghosal, Navonil Majumder, Ambuj Mehrish, and Soujanya Poria. 2023. Text-to-audio generation using instruction-tuned llm and latent diffusion model. arXiv preprint arXiv:2304.13731(2023). Sreyan Ghosh, Zhifeng Kong, Sonal Kumar, S. Sakshi, Jaehyeon Kim, Wei Ping, Rafael Valle, Dinesh Manoch...
-
[2]
Audio flamingo 3: Advancing audio intelligence with fully open large audio language models.arXiv preprint arXiv:2507.08128(2025). Yingqing He, Zhaoyang Liu, Jingye Chen, Zeyue Tian, Hongyu Liu, Xiaowei Chi, Runtao Liu, Ruibin Yuan, Yazhou Xing, Wenhai Wang, et al. 2024. Llms meet multimodal generation and editing: A survey.arXiv preprint arXiv:2405.19334(...
-
[3]
Audio Flamingo: A Novel Audio Language Model with Few-Shot Learning and Dialogue Abilities. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net. https://openreview. net/forum?id=WYi3WKZjYe Felix Kreuk, Gabriel Synnaeve, Adam Polyak, Uriel Singer, Alexandre Défossez, Jade Copet, Devi Pari...
-
[4]
Ruijie Tao, Zexu Pan, Rohan Kumar Das, Xinyuan Qian, Mike Zheng Shou, and Haizhou Li
Scaper: A library for soundscape synthesis and augmentation. In2017 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (W ASPAA). IEEE, 344–348. Bowen Shi, Andros Tjandra, John Hoffman, Helin Wang, Yi-Chiao Wu, Luya Gao, Julius Richter, Matt Le, Apoorv Vyas, Sanyuan Chen, et al. 2025. SAM Audio: Segment Anything in Audio.arXiv prepr...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.