Psychological Concept Neurons: Can Neural Control Bias Probing and Shift Generation in LLMs?
Pith reviewed 2026-05-10 15:49 UTC · model grok-4.3
The pith
Intervening on neurons selective for Big Five personality concepts shifts internal model probes toward targeted traits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
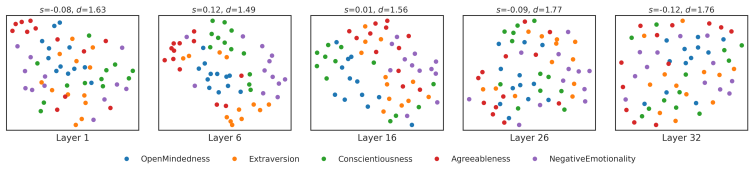
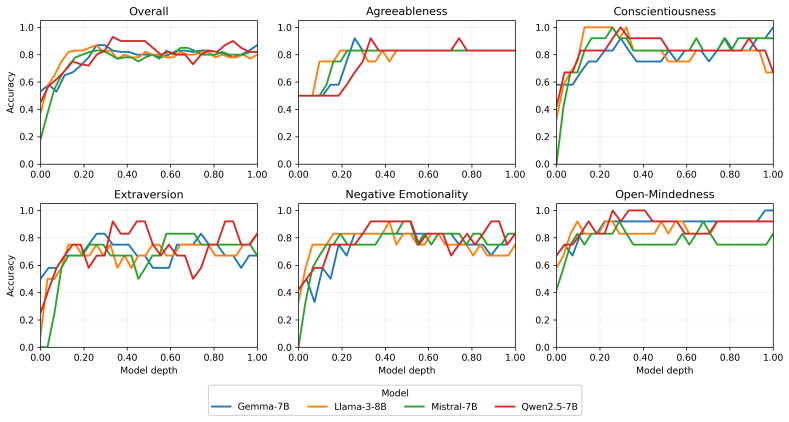
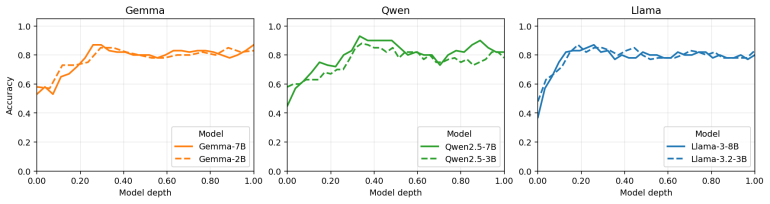
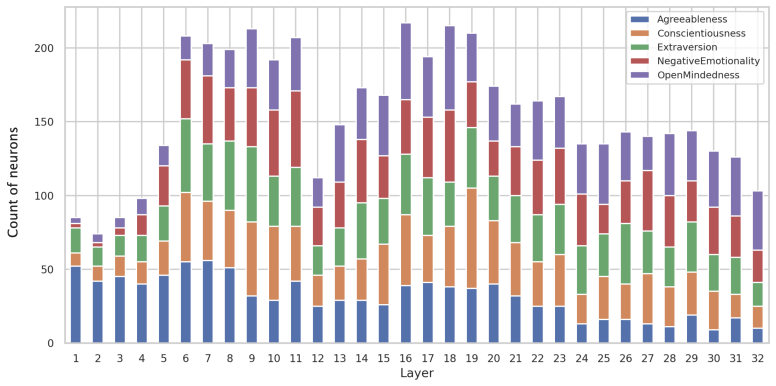
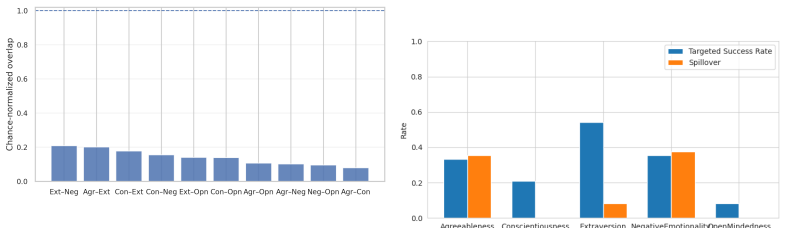
Big Five information becomes rapidly decodable in early layers and remains detectable through the final layers, while concept-selective neurons are most prevalent in mid layers and exhibit limited overlap across domains. Interventions on these neurons consistently shift probe readouts toward targeted concepts, with targeted success rates exceeding 0.8 for some concepts, indicating that the model's internal separation of Big Five personality traits can be causally steered. At the label-generation level, the same interventions often bias generated label distributions in the intended directions, but the effects are weaker, more concept-dependent, and often accompanied by cross-trait spillover.
What carries the argument
Concept-selective neurons for Big Five traits, identified by their selective activation to questionnaire items and used as targets for activation enhancement or suppression to test causal effects on representations and outputs.
If this is right
- Big Five information is encoded early in the network and stays detectable through later layers.
- Neurons selective for different traits are concentrated in middle layers and show little overlap.
- Interventions on these neurons can steer internal probe outputs toward chosen traits with high targeted success.
- Effects on actual label generation remain weaker, vary by trait, and frequently spill across traits.
- A clear separation exists between the ability to control latent representations and the ability to control generated behavior.
Where Pith is reading between the lines
- The same method of locating and intervening on selective neurons could be applied to other psychological or conceptual categories beyond personality.
- Behavioral control may require changes at later stages of processing in addition to mid-layer representational neurons.
- Targeting these circuits could provide a route to reduce or amplify specific trait-related patterns in model responses.
- The limited overlap between traits suggests personality constructs are handled in relatively separate internal circuits.
Load-bearing premise
The neurons selected by their response patterns are causally responsible for the personality-related internal states rather than merely correlated with them or influenced by artifacts in the probing method.
What would settle it
An experiment that intervenes on the same set of identified neurons yet finds no reliable directional shift in probe readouts or generated labels would show the claimed causal link does not hold.
Figures

read the original abstract
Using psychological constructs such as the Big Five, large language models (LLMs) can imitate specific personality profiles and predict a user's personality. While LLMs can exhibit behaviors consistent with these constructs, it remains unclear where and how they are represented inside the model and how they relate to behavioral outputs. To address this gap, we focus on questionnaire-operationalized Big Five concepts, analyze the formation and localization of their internal representations, and use interventions to examine how these representations relate to behavioral outputs. In our experiment, we first use probing to examine where Big Five information emerges across model depth. We then identify neurons that respond selectively to each Big Five concept and test whether enhancing or suppressing their activations can bias latent representations and label generation in intended directions. We find that Big Five information becomes rapidly decodable in early layers and remains detectable through the final layers, while concept-selective neurons are most prevalent in mid layers and exhibit limited overlap across domains. Interventions on these neurons consistently shift probe readouts toward targeted concepts, with targeted success rates exceeding 0.8 for some concepts, indicating that the model's internal separation of Big Five personality traits can be causally steered. At the label-generation level, the same interventions often bias generated label distributions in the intended directions, but the effects are weaker, more concept-dependent, and often accompanied by cross-trait spillover, indicating that comparable control over generated labels is difficult even with interventions on a large fraction of concept-selective neurons. Overall, our findings reveal a gap between representational control and behavioral control in LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Big Five personality information in LLMs becomes rapidly decodable via probing in early layers and persists through final layers, with concept-selective neurons concentrated in mid-layers showing limited cross-trait overlap. Interventions that enhance or suppress these neurons shift probe readouts toward targeted concepts at success rates >0.8 for some traits, indicating causal steerability of internal representations, while the same interventions produce weaker, more variable, and spillover-prone shifts in generated personality labels.
Significance. If the intervention results demonstrate genuine causal influence on the model's internal trait representations rather than probe-specific artifacts, the work would be significant for mechanistic interpretability of psychological constructs in LLMs. It would also usefully document a representational-behavioral control gap, with potential implications for targeted editing of model internals versus reliable output steering.
major comments (3)
- [Methods (neuron identification and selectivity)] The neuron identification procedure (detailed in the methods section on selectivity analysis) must be shown to be independent of the linear probes later used for readout evaluation. If selectivity is computed via activation differences on the same questionnaire items or via probe importance scores, then scaling/suppressing those neurons will shift probe outputs by construction, undermining the causal claim that the neurons implement the model's internal separation of traits.
- [Results (probe readout interventions)] The reported probe success rates exceeding 0.8 (abstract and results on interventions) require explicit baselines, such as random neuron interventions or interventions on non-selective neurons, plus statistical tests and confidence intervals. Without these, it is unclear whether the shifts exceed what would be expected from any mid-layer intervention of comparable magnitude.
- [Results (label generation)] The weaker and spillover-prone effects on label generation (results section) are load-bearing for the paper's conclusion about the gap between representational and behavioral control. The manuscript should report the exact fraction of concept-selective neurons intervened upon per trait and compare effect sizes against controls that intervene on an equal number of randomly chosen neurons.
minor comments (2)
- [Methods] Clarify the precise intervention mechanism (additive scaling, clamping, or masking) and the number of neurons per concept in the main text rather than deferring all details to the appendix.
- [Abstract] The abstract's phrasing of 'targeted success rates exceeding 0.8' should be accompanied by per-concept breakdowns and a note on the definition of 'success' (e.g., direction of shift, magnitude threshold) to avoid overgeneralization.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important methodological clarifications and strengthens the evidential basis for our claims about representational versus behavioral control. We address each major comment below and will incorporate the suggested additions and controls into a revised manuscript.
read point-by-point responses
-
Referee: [Methods (neuron identification and selectivity)] The neuron identification procedure (detailed in the methods section on selectivity analysis) must be shown to be independent of the linear probes later used for readout evaluation. If selectivity is computed via activation differences on the same questionnaire items or via probe importance scores, then scaling/suppressing those neurons will shift probe outputs by construction, undermining the causal claim that the neurons implement the model's internal separation of traits.
Authors: We agree that independence must be demonstrated explicitly. Neuron selectivity was computed using activation differences on a held-out subset of questionnaire items (distinct from the probe training split), relying solely on raw activation contrasts without reference to probe weights or importance scores. We will add a dedicated methods subsection detailing the data partitioning, include a schematic of the splits, and report an auxiliary analysis using an alternative variance-based neuron selection criterion that avoids any probing step. revision: yes
-
Referee: [Results (probe readout interventions)] The reported probe success rates exceeding 0.8 (abstract and results on interventions) require explicit baselines, such as random neuron interventions or interventions on non-selective neurons, plus statistical tests and confidence intervals. Without these, it is unclear whether the shifts exceed what would be expected from any mid-layer intervention of comparable magnitude.
Authors: We accept this point and will strengthen the results. The revised version will include control interventions on randomly selected mid-layer neurons (matched in count and layer distribution) and on non-selective neurons, together with paired statistical tests and 95% confidence intervals on the success rates. These will appear in an expanded table and accompanying figure. revision: yes
-
Referee: [Results (label generation)] The weaker and spillover-prone effects on label generation (results section) are load-bearing for the paper's conclusion about the gap between representational and behavioral control. The manuscript should report the exact fraction of concept-selective neurons intervened upon per trait and compare effect sizes against controls that intervene on an equal number of randomly chosen neurons.
Authors: We agree these details are necessary. We will report the precise fractions of intervened neurons per trait (ranging 8–22% of mid-layer units) and add matched random-neuron control conditions with effect-size comparisons (using distributional metrics such as KL divergence). These controls and statistics will be added to the label-generation results section with new supplementary figures. revision: yes
Circularity Check
No significant circularity; empirical intervention results are independent of selection
full rationale
The paper's chain proceeds from probing for decodability across layers, to identifying concept-selective neurons via selectivity measures on questionnaire items, to performing activation interventions and measuring resulting shifts in probe readouts and label generation. These are distinct empirical steps: selectivity identification does not mathematically define the intervention outcomes, and the reported weaker/spillover effects on generation further indicate the probe shifts are not forced by construction. No self-citations, uniqueness theorems, or ansatzes are invoked to justify the central claims. The derivation relies on direct measurement rather than reduction to fitted inputs or prior author results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
doi: 10.1037/0022-3514.91.6.1138. John M. Digman. Higher-order factors of the big five.Journal of Personality and Social Psychology, 73(6):1246–1256,
-
[2]
doi: 10.1037/0022-3514.73.6.1246. Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1037/0022-3514.73.6.1246
-
[3]
URLhttps://openreview.net/ forum?id=jE8xbmvFin. Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chap- lot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, L´elio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timoth ´ee Lacroix, and...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
URLhttps: //openreview.net/forum?id=z9SbcYYP0M. Leland McInnes, John Healy, and James Melville. Umap: Uniform manifold approximation and projection for dimension reduction.arXiv preprint arXiv:1802.03426,
work page internal anchor Pith review arXiv
-
[5]
URLhttps://arxiv.org/abs/2412.15115. Federico Ravenda, Seyed Ali Bahrainian, Andrea Raballo, Antonietta Mira, and Noriko Kando. Are LLMs effective psychological assessors? leveraging adaptive RAG for interpretable mental health screening through psychometric practice. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (eds.),Pr...
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Fang, J., Jiang, H., Wang, K., Ma, Y ., Shi, J., Wang, X., He, X., and Chua, T
Association for Computational Linguistics. ISBN 979-8-89176-251-0. doi: 10.18653/v1/ 2025.acl-long.440. URLhttps://aclanthology.org/2025.acl-long.440/. Aadesh Salecha, Molly E Ireland, Shashanka Subrahmanya, Jo ˜ao Sedoc, Lyle H Ungar, and Jo- hannes C Eichstaedt. Large language models display human-like social desirability biases in big five personality ...
-
[7]
doi: 10.1093/ pnasnexus/pgae533
ISSN 2752-6542. doi: 10.1093/ pnasnexus/pgae533. URLhttps://doi.org/10.1093/pnasnexus/pgae533. Aleksandra Sorokovikova, Sharwin Rezagholi, Natalia Fedorova, and Ivan P. Yamshchikov. LLMs simulate big5 personality traits: Further evidence. In Ameet Deshpande, EunJeong Hwang, Vish- vak Murahari, Joon Sung Park, Diyi Yang, Ashish Sabharwal, Karthik Narasimha...
-
[8]
URLhttps://aclanthology.org/2024.personalize-1.7/
Association for Computa- tional Linguistics. URLhttps://aclanthology.org/2024.personalize-1.7/. Christopher J Soto and Oliver P John. The next big five inventory (bfi-2): Developing and assessing a hierarchical model with 15 facets to enhance bandwidth, fidelity, and predictive power.Journal of personality and social psychology, 113(1):117,
work page 2024
-
[9]
URLhttps://arxiv.org/abs/2005.07647. Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivi `ere, Mihir Sanjay Kale, Juliette Love, Pouya Tafti, L ´eonard Hussenot, Pier Giuseppe Sessa, Aakanksha Chowdhery, Adam Roberts, Aditya Barua, Alex Botev, Alex Castro-Ros, Ambrose Slone, Am´elie H´e...
-
[10]
Gemma: Open Models Based on Gemini Research and Technology
URLhttps://arxiv.org/abs/2403.08295. Minjun Zhu, Yixuan Weng, Linyi Yang, and Yue Zhang. Personality alignment of large language models. InThe Thirteenth International Conference on Learning Representations,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.