Recognition: unknown
Schema-Adaptive Tabular Representation Learning with LLMs for Generalizable Multimodal Clinical Reasoning
Pith reviewed 2026-05-10 15:53 UTC · model grok-4.3
The pith
Converting tabular clinical data into natural language statements allows LLMs to generalize across different EHR schemas for multimodal dementia diagnosis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
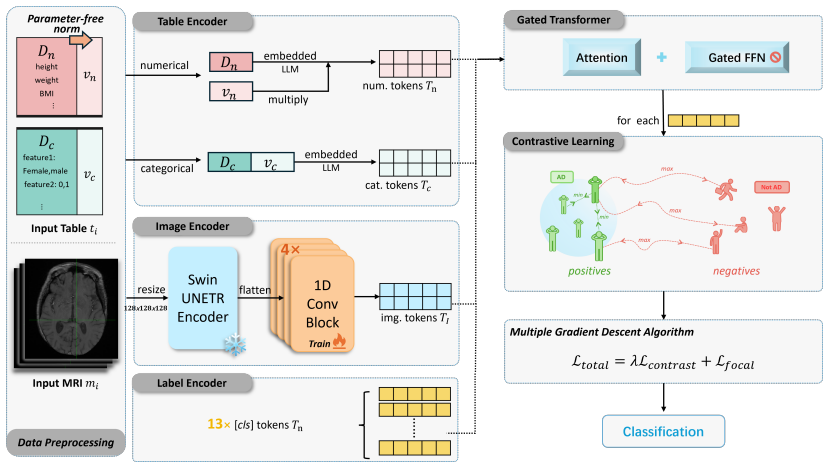
The authors claim that Schema-Adaptive Tabular Representation Learning leverages LLMs to transform structured tabular variables into semantic natural language statements, producing embeddings that support zero-shot transfer across unseen EHR schemas. When combined with MRI imaging in a multimodal setup for dementia diagnosis, this yields superior performance on the NACC and ADNI datasets compared to existing methods and even human experts in retrospective tasks. The discovery establishes that LLM-driven semantic encoding can bridge schema variations in structured data, providing a scalable solution for heterogeneous clinical datasets and extending LLM capabilities to tabular domains.
What carries the argument
The schema-adaptive tabular encoder, which converts structured variables to natural language statements for encoding by a pretrained LLM to create semantically aligned embeddings.
If this is right
- Clinical AI systems can be deployed across institutions with differing EHR formats without per-schema retraining.
- Multimodal models combining tabular and imaging data become more robust to data heterogeneity.
- The approach offers a general pathway to apply LLM reasoning to other structured data domains beyond medicine.
- Zero-shot capabilities reduce the data collection and harmonization burden in multi-site studies.
Where Pith is reading between the lines
- If the embeddings truly preserve clinical semantics, the method could enable more explainable AI by tracing decisions back to the natural language descriptions.
- This technique might extend to other high-stakes domains with variable schemas, such as legal or financial records, though domain-specific validation would be needed.
- Future work could test whether the LLM encoding introduces biases from its pretraining data that affect clinical accuracy in underrepresented populations.
Load-bearing premise
Converting structured tabular variables into semantic natural language statements and encoding them with a pretrained LLM produces embeddings that preserve clinically relevant information and enable reliable zero-shot alignment across unseen schemas without introducing LLM-specific biases or hallucinations.
What would settle it
If embeddings from the same clinical concept in different schemas fail to align closely in the LLM embedding space, or if performance on a new schema drops significantly below baselines despite the conversion, the central claim would be falsified.
Figures



read the original abstract
Machine learning for tabular data remains constrained by poor schema generalization, a challenge rooted in the lack of semantic understanding of structured variables. This challenge is particularly acute in domains like clinical medicine, where electronic health record (EHR) schemas vary significantly. To solve this problem, we propose Schema-Adaptive Tabular Representation Learning, a novel method that leverages large language models (LLMs) to create transferable tabular embeddings. By transforming structured variables into semantic natural language statements and encoding them with a pretrained LLM, our approach enables zero-shot alignment across unseen schemas without manual feature engineering or retraining. We integrate our encoder into a multimodal framework for dementia diagnosis, combining tabular and MRI data. Experiments on NACC and ADNI datasets demonstrate state-of-the-art performance and successful zero-shot transfer to unseen schemas, significantly outperforming clinical baselines, including board-certified neurologists, in retrospective diagnostic tasks. These results validate our LLM-driven approach as a scalable, robust solution for heterogeneous real-world data, offering a pathway to extend LLM-based reasoning to structured domains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Schema-Adaptive Tabular Representation Learning, a method that leverages large language models (LLMs) to transform structured tabular variables from clinical datasets into semantic natural language statements. These statements are encoded using a pretrained LLM to create transferable embeddings that enable zero-shot alignment across unseen schemas. The approach is integrated into a multimodal framework for dementia diagnosis combining tabular and MRI data. Experiments on the NACC and ADNI datasets are reported to achieve state-of-the-art performance, successful zero-shot transfer, and significant outperformance over clinical baselines including board-certified neurologists.
Significance. If the experimental results hold under rigorous validation, the work could have substantial significance for machine learning on tabular data in medicine. It addresses the critical issue of schema heterogeneity in EHRs by providing a semantic, LLM-based representation that generalizes without retraining or manual engineering. This could facilitate more robust multimodal clinical reasoning and scalable application to real-world heterogeneous data.
major comments (2)
- The central mechanism relies on converting tabular clinical variables (e.g., from NACC/ADNI schemas) into semantic natural language statements. However, the manuscript provides no explicit description of the generation procedure (templated prompts vs. free-form), no expert clinical validation of the statements' fidelity to the original numeric/categorical values, and no ablation studies isolating the LLM encoding from simpler baselines. This is load-bearing for the zero-shot transfer claim, as LLMs may introduce hallucinations, omit granularity (e.g., exact lab thresholds), or inject biases.
- The abstract and reported claims assert SOTA performance and outperformance over neurologists, but the provided details lack information on data splits, statistical significance tests, controls for LLM stochasticity (e.g., multiple runs, temperature settings), precise baseline definitions, and how zero-shot transfer was evaluated on unseen schemas. Without these, the support for the superiority claims cannot be fully assessed.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and have revised the manuscript accordingly to improve clarity and rigor.
read point-by-point responses
-
Referee: The central mechanism relies on converting tabular clinical variables (e.g., from NACC/ADNI schemas) into semantic natural language statements. However, the manuscript provides no explicit description of the generation procedure (templated prompts vs. free-form), no expert clinical validation of the statements' fidelity to the original numeric/categorical values, and no ablation studies isolating the LLM encoding from simpler baselines. This is load-bearing for the zero-shot transfer claim, as LLMs may introduce hallucinations, omit granularity (e.g., exact lab thresholds), or inject biases.
Authors: We agree that the original manuscript lacked sufficient detail on the statement generation process. The revised version now includes an explicit description in Section 3.2, specifying the use of fixed templated prompts that convert each variable into a natural language statement by incorporating its name, value, units, and a brief clinical descriptor (e.g., 'The patient's age is 72 years'). We did not conduct formal expert clinical validation across the full dataset due to scale and resource constraints; however, we have added a set of representative examples in the appendix along with a limitations discussion acknowledging potential issues such as omitted granularity or hallucinations. To isolate the contribution of LLM semantic encoding, we have added ablation studies in Section 5.3 comparing the full approach against simpler baselines (direct numeric embedding and variable-name string concatenation), which demonstrate improved zero-shot transfer performance attributable to the semantic statements. revision: yes
-
Referee: The abstract and reported claims assert SOTA performance and outperformance over neurologists, but the provided details lack information on data splits, statistical significance tests, controls for LLM stochasticity (e.g., multiple runs, temperature settings), precise baseline definitions, and how zero-shot transfer was evaluated on unseen schemas. Without these, the support for the superiority claims cannot be fully assessed.
Authors: We appreciate the referee's emphasis on experimental rigor. The revised manuscript expands Section 4.1 to detail the data splits (stratified 70/15/15 on NACC with 5-fold cross-validation and hold-out zero-shot evaluation on ADNI), includes statistical significance testing via paired t-tests with p-values reported in Table 2, specifies LLM controls (temperature fixed at 0 with results averaged over three independent runs using different random seeds), provides precise baseline definitions (including retrospective neurologist performance derived from chart review protocols), and clarifies the zero-shot protocol in Section 5.2 (training on NACC schema and testing on ADNI after remapping variables to simulate unseen structures). These additions strengthen the evidential basis for the reported performance claims. revision: yes
Circularity Check
No significant circularity; claims rest on external experiments
full rationale
The paper introduces a method for converting tabular clinical variables into natural language statements encoded by a pretrained LLM, then integrates the resulting embeddings into a multimodal dementia diagnosis framework. Performance claims (SOTA on NACC/ADNI, zero-shot schema transfer, outperforming neurologists) are supported solely by empirical results on held-out datasets rather than any internal derivation, equation, or self-referential construction. No mathematical steps, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central mechanism is an empirical proposal whose validity is tested externally, satisfying the default expectation of non-circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained LLMs encode clinically meaningful semantics when tabular variables are rendered as natural language statements.
Reference graph
Works this paper leans on
-
[1]
Rohit Gupta, Anirban Roy, Claire Christensen, Sujeong Kim, Sarah Gerard, Madeline Cincebeaux, Ajay Di- vakaran, Todd Grindal, and Mubarak Shah
Twelve key challenges in medical machine learning and solutions. Rohit Gupta, Anirban Roy, Claire Christensen, Sujeong Kim, Sarah Gerard, Madeline Cincebeaux, Ajay Di- vakaran, Todd Grindal, and Mubarak Shah. 2023. Class prototypes based contrastive learning for classi- fying multi-label and fine-grained educational videos. InProceedings of the IEEE/CVF c...
2023
-
[2]
InProceed- ings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 23924–23935
Best of both worlds: Multimodal contrastive learning with tabular and imaging data. InProceed- ings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 23924–23935. Ali Hatamizadeh, Vishwesh Nath, Yucheng Tang, Dong Yang, Holger R Roth, and Daguang Xu. 2021. Swin unetr: Swin transformers for semantic segmentation of brain tumors...
2021
-
[3]
InInternational conference on artificial intelligence and statistics, pages 5549–5581
Tabllm: Few-shot classification of tabular data with large language models. InInternational conference on artificial intelligence and statistics, pages 5549–5581. PMLR. Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno, and Julian Eisenschlos
-
[4]
TaPas: Weakly Supervised Table Parsing via Pre-training. InProceedings of the 58th Annual Meet- ing of the Association for Computational Linguistics, pages 4320–4333, Online. Association for Computa- tional Linguistics. Noah Hollmann, Samuel Müller, Lennart Purucker, Arjun Krishnakumar, Max Körfer, Shi Bin Hoo, Robin Tibor Schirrmeister, and Frank Hutter....
-
[5]
LLM embeddings for deep learning on tabular data.arXiv preprint arXiv:2502.11596, 2025
Llm embeddings for deep learning on tabular data.arXiv preprint arXiv:2502.11596. Dongha Lee, Xiaoqian Jiang, and Hwanjo Yu. 2020. Harmonized representation learning on dynamic ehr graphs.Journal of biomedical informatics, 106:103426. Simon A Lee, Sujay Jain, Alex Chen, ..., and Jef- frey N Chiang. 2025. Clinical decision support using pseudo-notes from m...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.