MultiDocFusion: Hierarchical and Multimodal Chunking Pipeline for Enhanced RAG on Long Industrial Documents
Pith reviewed 2026-05-10 14:40 UTC · model grok-4.3
The pith
Reconstructing document hierarchies with vision and LLM parsing improves RAG retrieval precision by 8-15 percent on long industrial documents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
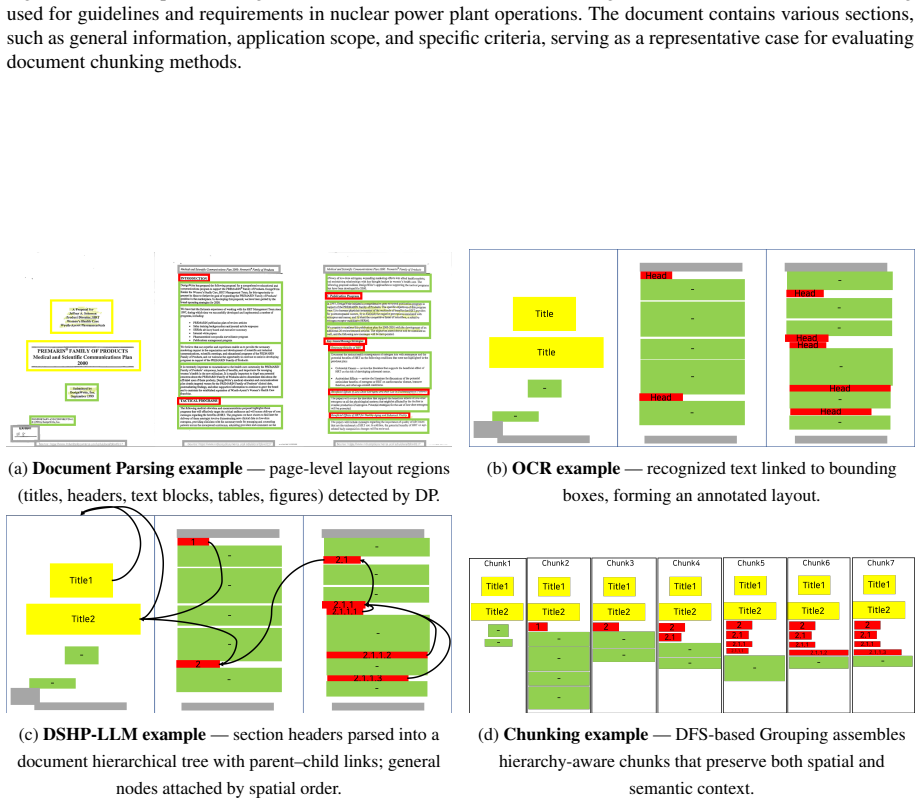
MultiDocFusion integrates vision-based region detection, OCR text extraction, LLM-based document section hierarchical parsing to build a tree, and DFS-based grouping to produce hierarchical chunks. This structure-aware approach explicitly leverages document hierarchy for multimodal document-based QA, delivering higher retrieval precision and answer fidelity than flat chunking baselines on long industrial documents.
What carries the argument
DSHP-LLM, the LLM-driven document section hierarchical parsing step that reconstructs sections into a tree structure, which then enables DFS-based grouping to preserve relationships across multimodal regions for retrieval.
If this is right
- Retrieval precision rises because hierarchical chunks keep related sections together instead of splitting them.
- QA answer quality improves as the system retrieves context that respects original document organization.
- Multimodal inputs become necessary to capture layout details that text-only methods miss.
- Structure-aware chunking reduces information loss in RAG systems handling complex technical content.
- The performance edge comes directly from treating hierarchy as a first-class element rather than an afterthought.
Where Pith is reading between the lines
- The same hierarchy-reconstruction steps could apply to other structured domains such as legal contracts or research papers if the LLM parser is retrained on their layouts.
- Early use of these chunks in a RAG pipeline might lessen the need for later-stage reranking or query rewriting.
- Adding a verification step to check the LLM-parsed tree against the visual layout could reduce propagation of parsing mistakes.
- Testing the pipeline on documents longer than the current benchmarks would reveal whether the gains scale with size.
Load-bearing premise
Vision-based region detection combined with LLM-driven hierarchical parsing can recover accurate document structures without errors that degrade later retrieval and QA steps.
What would settle it
Applying the full MultiDocFusion pipeline to the same industrial benchmarks and observing retrieval precision or ANLS QA scores no higher than standard flat-chunking baselines would show the claimed gains do not hold.
Figures


read the original abstract
RAG-based QA has emerged as a powerful method for processing long industrial documents. However, conventional text chunking approaches often neglect complex and long industrial document structures, causing information loss and reduced answer quality. To address this, we introduce MultiDocFusion, a multimodal chunking pipeline that integrates: (i) detection of document regions using vision-based document parsing, (ii) text extraction from these regions via OCR, (iii) reconstruction of document structure into a hierarchical tree using large language model (LLM)-based document section hierarchical parsing (DSHP-LLM), and (iv) construction of hierarchical chunks through DFS-based grouping. Extensive experiments across industrial benchmarks demonstrate that MultiDocFusion improves retrieval precision by 8-15% and ANLS QA scores by 2-3% compared to baselines, emphasizing the critical role of explicitly leveraging document hierarchy for multimodal document-based QA. These significant performance gains underscore the necessity of structure-aware chunking in enhancing the fidelity of RAG-based QA systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MultiDocFusion, a multimodal chunking pipeline for RAG on long industrial documents. It combines vision-based region detection, OCR text extraction, LLM-based document section hierarchical parsing (DSHP-LLM) to build a hierarchical tree, and DFS-based grouping to create hierarchical chunks. Experiments on industrial benchmarks are reported to yield 8-15% gains in retrieval precision and 2-3% gains in ANLS QA scores over baselines, attributing the improvements to explicit use of document hierarchy.
Significance. If the performance claims are supported by detailed baselines, ablations, and validation of the hierarchy reconstruction, the work would offer a practical advance for RAG systems processing complex industrial documents by demonstrating measurable benefits of structure-aware chunking over conventional flat approaches.
major comments (2)
- [Abstract] Abstract: The stated quantitative improvements (8-15% retrieval precision, 2-3% ANLS) are presented without any information on the baselines, dataset sizes, number of documents, statistical significance, error bars, or ablation controls. This prevents evaluation of whether the gains are real, reproducible, or specifically due to the hierarchical components.
- [Method] Method section (DSHP-LLM and hierarchical chunking): No intermediate metrics are reported on the fidelity of DSHP-LLM hierarchy reconstruction (e.g., section-boundary F1, tree-edit distance, or nesting consistency), nor is there an ablation isolating DSHP-LLM versus vision/OCR alone. If boundary or nesting errors occur, the DFS chunks become noisy flat chunks and the attribution of gains to hierarchy-aware chunking cannot be substantiated.
minor comments (1)
- The abstract and method descriptions would benefit from explicit definitions of the industrial benchmarks and the precise baselines (e.g., standard chunking methods or other RAG pipelines) used for comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will incorporate revisions to improve clarity and substantiation of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The stated quantitative improvements (8-15% retrieval precision, 2-3% ANLS) are presented without any information on the baselines, dataset sizes, number of documents, statistical significance, error bars, or ablation controls. This prevents evaluation of whether the gains are real, reproducible, or specifically due to the hierarchical components.
Authors: We agree that the abstract's brevity limits inclusion of full experimental details. In the revised manuscript, we will expand the abstract to specify the number of documents and datasets used while remaining concise. We will also add a reference to the Experiments section for baselines, statistical significance, error bars, and ablation controls. Full details on these aspects, including dataset sizes and reproducibility information, are already provided in Section 4 and the associated tables; the revision will make this linkage explicit in the abstract. revision: partial
-
Referee: [Method] Method section (DSHP-LLM and hierarchical chunking): No intermediate metrics are reported on the fidelity of DSHP-LLM hierarchy reconstruction (e.g., section-boundary F1, tree-edit distance, or nesting consistency), nor is there an ablation isolating DSHP-LLM versus vision/OCR alone. If boundary or nesting errors occur, the DFS chunks become noisy flat chunks and the attribution of gains to hierarchy-aware chunking cannot be substantiated.
Authors: We acknowledge that intermediate validation metrics for DSHP-LLM would strengthen the attribution of gains to hierarchy-aware chunking. In the revised manuscript, we will add an ablation study comparing the full MultiDocFusion pipeline against a variant using only vision parsing and OCR (without DSHP-LLM). We will also report section-boundary F1 scores and tree-edit distances on a manually annotated subset of documents to quantify hierarchy reconstruction fidelity. These additions will directly address concerns about potential nesting errors and substantiate the role of the hierarchical components. revision: yes
Circularity Check
No circularity: empirical pipeline evaluated on external benchmarks
full rationale
The paper describes a multimodal chunking pipeline (vision region detection + OCR + DSHP-LLM hierarchy reconstruction + DFS grouping) and reports end-to-end retrieval and ANLS gains on industrial benchmarks. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. Performance claims rest on comparative experiments rather than any step that reduces by construction to its own inputs. The absence of intermediate validation metrics (e.g., hierarchy F1) is a potential attribution weakness but does not constitute circularity in the derivation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Vision-based document parsing can accurately detect regions in industrial documents
- domain assumption LLMs can perform reliable document section hierarchical parsing from extracted text
Reference graph
Works this paper leans on
-
[1]
Lum- berchunker: Long-form narrative document segmen- tation.arXiv preprint arXiv:2406.17526, 2024
Vision grid transformer for document layout analysis. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision (ICCV). Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, and et al. 2021. An image is worth 16x16 words: Transformers for image recognition at scale. InProceedings of the 9th International Conference on ...
-
[2]
The llama 3 herd of models.Preprint, arXiv:2407.21783. Zeyu Han, Chao Gao, Jinyang Liu, Jeff Zhang, and Sai Qian Zhang. 2024. Parameter-efficient fine- tuning for large models: A comprehensive survey. Preprint, arXiv:2403.14608. Dan Hendrycks, Collin Burns, Anya Chen, and Spencer Ball. 2021. Cuad: An expert-annotated nlp dataset for legal contract review....
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.