Orthogonal Subspace Projection for Continual Machine Unlearning via SVD-Based LoRA
Pith reviewed 2026-05-10 15:55 UTC · model grok-4.3
The pith
SVD-guided orthogonal projection lets LoRA handle thirty sequential unlearning tasks while keeping retained accuracy near baseline.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
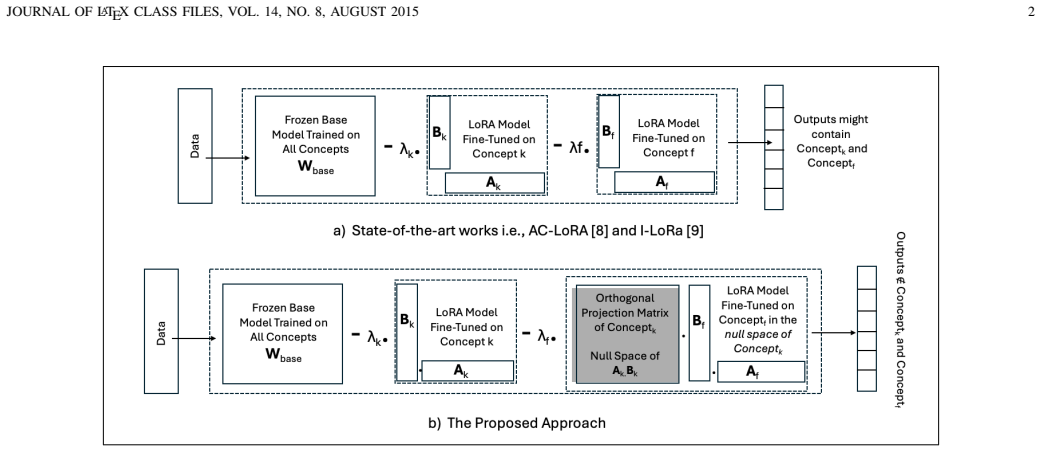
Constraining each new LoRA update during training so that it lies in the orthogonal complement of the subspaces used by earlier unlearning tasks preserves task isolation without requiring dynamic routing at deployment. After thirty sequential unlearning tasks, state-of-the-art static fusion reduces retained accuracy from 60.39 percent to 12.70 percent, whereas the proposed in-training constrained optimization maintains baseline performance of approximately 58.1 percent while preserving strong unlearning efficacy.
What carries the argument
SVD-based orthogonal subspace projection that forces each new LoRA adapter into the orthogonal complement of subspaces already used by prior unlearning tasks.
If this is right
- Retained accuracy remains close to the original baseline across long sequences of deletion requests.
- Each unlearning task stays isolated from the others without parameter collision.
- Inference requires no dynamic routing or task identification, keeping deployment cost unchanged.
- The same constrained training procedure works on both ResNet-20 and simpler architectures.
Where Pith is reading between the lines
- The same isolation idea could be applied to other continual adaptation problems where tasks must not overwrite one another.
- When subspace capacity is exhausted, increasing LoRA rank or periodically resetting the base model may become necessary.
- The approach could reduce reliance on full retraining from scratch in privacy-regulated settings.
Load-bearing premise
The remaining orthogonal directions in each layer will always contain enough capacity for an effective new unlearning update without driving the optimizer into poor local minima.
What would settle it
Run the method until the cumulative rank of used subspaces approaches the hidden dimension of a layer and measure whether retained accuracy or unlearning success rate drops sharply on the next task.
Figures


read the original abstract
Continual machine unlearning aims to remove the influence of data that should no longer be retained, while preserving the usefulness of the model on everything else. This setting becomes especially difficult when deletion requests arrive sequentially, because the model must repeatedly adapt without erasing previously retained knowledge. Low-Rank Adaptation (LoRA) offers an efficient way to implement such updates, but naively combining many sequential LoRA modules leads to parameter collision, causing \textit{strong interference} between tasks. We propose a static alternative based on Singular Value Decomposition (SVD)-guided orthogonal subspace projection. Our method constrains each new LoRA update during training so that it lies in the orthogonal complement of the subspaces used by earlier unlearning tasks. This preserves task isolation without requiring dynamic routing at deployment. Experiments on CIFAR-100 with ResNet-20 and on MNIST show stable behavior across long sequences of unlearning tasks. After thirty sequential unlearning tasks, state-of-the-art static fusion reduces retained accuracy from 60.39\% to 12.70\%, whereas the proposed in-training constrained optimization maintains baseline performance ($\sim$58.1\%) while preserving strong unlearning efficacy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SVD-based orthogonal subspace projection to constrain LoRA updates during continual machine unlearning. Each new update is forced into the orthogonal complement of subspaces from prior tasks, avoiding parameter collision when statically fusing multiple LoRA modules. On CIFAR-100 (ResNet-20) and MNIST, the method is reported to maintain ~58.1% retained accuracy after 30 sequential unlearning tasks, while state-of-the-art static fusion drops from 60.39% to 12.70%, with claims of preserved unlearning efficacy.
Significance. If the orthogonality constraint successfully preserves sufficient capacity in the complement subspace for new unlearning gradients without forcing poor local minima, the approach would provide a practical static alternative to dynamic routing for sequential unlearning. The concrete long-sequence results on standard benchmarks constitute a strength, offering empirical grounding for the isolation-without-routing claim.
major comments (3)
- [Abstract] Abstract: the central performance claim (maintenance of ~58.1% retained accuracy after 30 tasks versus degradation to 12.70%) is presented without error bars, without ablations on LoRA rank or SVD truncation threshold, and without explicit verification that unlearning is measured by membership-inference or retraining attacks; these omissions directly affect assessment of whether the shrinking orthogonal complement retains usable capacity for later tasks.
- [Method] Method description: the mechanism for enforcing the orthogonality constraint during optimization (how the SVD projection is applied inside the training loop, whether it is a hard constraint or a regularizer, and the precise definition of the complement subspace) is not specified with equations or pseudocode, leaving the load-bearing claim that updates remain inside the complement unverified.
- [Experiments] Experiments section: no ablation or analysis is provided on how the allowable subspace dimension decreases with each rank-r SVD block, nor any test confirming that required unlearning gradient directions remain inside the complement rather than being projected away after many tasks; this directly tests the weakest assumption identified in the stress-test note.
minor comments (2)
- [Abstract] Abstract: the phrase 'strong unlearning efficacy' should be replaced by a quantitative metric or reference to a standard evaluation protocol.
- Consider adding a table or figure that reports retained accuracy, unlearning success rate, and subspace dimension remaining after each block of tasks, with standard deviations.
Simulated Author's Rebuttal
Thank you for the referee's constructive and detailed feedback on our manuscript. We address each major comment point by point below, indicating the revisions we will make to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claim (maintenance of ~58.1% retained accuracy after 30 tasks versus degradation to 12.70%) is presented without error bars, without ablations on LoRA rank or SVD truncation threshold, and without explicit verification that unlearning is measured by membership-inference or retraining attacks; these omissions directly affect assessment of whether the shrinking orthogonal complement retains usable capacity for later tasks.
Authors: We agree that the abstract would be strengthened by these supporting details. In the revised manuscript we will report error bars on all accuracy figures, add ablations varying LoRA rank and SVD truncation threshold, and explicitly describe the unlearning verification protocol (membership-inference attacks together with retraining-from-scratch baselines). revision: yes
-
Referee: [Method] Method description: the mechanism for enforcing the orthogonality constraint during optimization (how the SVD projection is applied inside the training loop, whether it is a hard constraint or a regularizer, and the precise definition of the complement subspace) is not specified with equations or pseudocode, leaving the load-bearing claim that updates remain inside the complement unverified.
Authors: We acknowledge that the current method section lacks the required mathematical precision. The revised version will include explicit equations and pseudocode showing that the SVD projection is applied as a hard constraint at each optimization step, together with the precise definition of the complement subspace as the orthogonal complement of the span of all prior-task right singular vectors. revision: yes
-
Referee: [Experiments] Experiments section: no ablation or analysis is provided on how the allowable subspace dimension decreases with each rank-r SVD block, nor any test confirming that required unlearning gradient directions remain inside the complement rather than being projected away after many tasks; this directly tests the weakest assumption identified in the stress-test note.
Authors: We will add both an analysis of the progressive reduction in allowable subspace dimension across the 30 tasks and new experiments that measure the fraction of each unlearning gradient that lies inside the current complement (via projection norms and cosine similarity before/after projection). These results will be reported in the revised experiments section. revision: yes
Circularity Check
No circularity: method is an algorithmic training constraint with empirical validation
full rationale
The paper proposes an SVD-based orthogonal projection to constrain sequential LoRA updates during training so each new unlearning task occupies the orthogonal complement of prior subspaces. This is a design choice implemented as an in-training optimization constraint, not a post-hoc derivation or prediction. The reported performance numbers (e.g., retained accuracy after 30 tasks) are direct experimental outcomes on CIFAR-100 and MNIST; no equations reduce these results to fitted parameters by construction, nor do any self-citations or ansatzes form a load-bearing loop. The derivation chain is self-contained as an engineering solution whose validity rests on the experiments rather than tautological equivalence to its inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
L. Bourtoule, V. Chandrasekaran, C. A. Choquette-Choo, H. Jia, A. Travers, B. Zhang, D. Lie, and N. Papernot, ``Machine unlearning,'' in 2021 IEEE Symposium on Security and Privacy (SP). 1em plus 0.5em minus 0.4em IEEE, 2021, pp. 141--159
work page 2021
-
[2]
E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, and W. Chen, ``Lora: Low-rank adaptation of large language models,'' in International Conference on Learning Representations, 2022
work page 2022
-
[3]
J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinska et al., ``Overcoming catastrophic forgetting in neural networks,'' Proceedings of the national academy of sciences, vol. 114, no. 13, pp. 3521--3526, 2017
work page 2017
-
[4]
D. Lopez-Paz and M. Ranzato, ``Gradient episodic memory for continual learning,'' Advances in neural information processing systems, vol. 30, 2017
work page 2017
-
[5]
G. Zeng, Y. Chen, B. Cui, and S. Yu, ``Continual learning of context-dependent processing in neural networks,'' Nature Machine Intelligence, vol. 1, no. 8, pp. 364--372, 2019
work page 2019
-
[6]
A. Golatkar, A. Achille, and S. Soatto, ``Eternal sunshine of the spotless net: Selective forgetting in deep networks,'' in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 9304--9312
work page 2020
-
[7]
P. W. Koh and P. Liang, ``Understanding black-box predictions via influence functions,'' in International conference on machine learning. 1em plus 0.5em minus 0.4em PMLR, 2017, pp. 1885--1894
work page 2017
-
[8]
L. Magdalena Lazier, A. Dhar, V. Stambolic, and L. Cavigelli, ``Ac-lora: Access control aware llms through dynamic adapter retrieval,'' in Advances in Neural Information Processing Systems (NeurIPS), 2025
work page 2025
-
[9]
G. Zhao, Q. Zhang, S. Zhai, D. Shen, T. Zhang, Y. Qiao, and T. Xu, ``I-lora: Iterative merging of routing-tuned adapters for continual learning,'' in sbumitted to ICLR 2025, 2024
work page 2025
- [11]
-
[12]
11em plus .33em minus .07em 4000 4000 100 4000 4000 500 `\.=1000 = #1 \@IEEEnotcompsoconly \@IEEEcompsoconly #1 * [1] 0pt [0pt][0pt] #1 * [1] 0pt [0pt][0pt] #1 * \| ** #1 \@IEEEauthorblockNstyle \@IEEEcompsocnotconfonly \@IEEEauthorblockAstyle \@IEEEcompsocnotconfonly \@IEEEcompsocconfonly \@IEEEauthordefaulttextstyle \@IEEEcompsocnotconfonly \@IEEEauthor...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.