Recognition: no theorem link
KMMMU: Evaluation of Massive Multi-discipline Multimodal Understanding in Korean Language and Context
Pith reviewed 2026-05-15 10:32 UTC · model grok-4.3
The pith
A new benchmark of 3,466 native Korean exam questions shows current multimodal models reaching at most 42 percent accuracy, with larger gaps on items requiring local conventions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
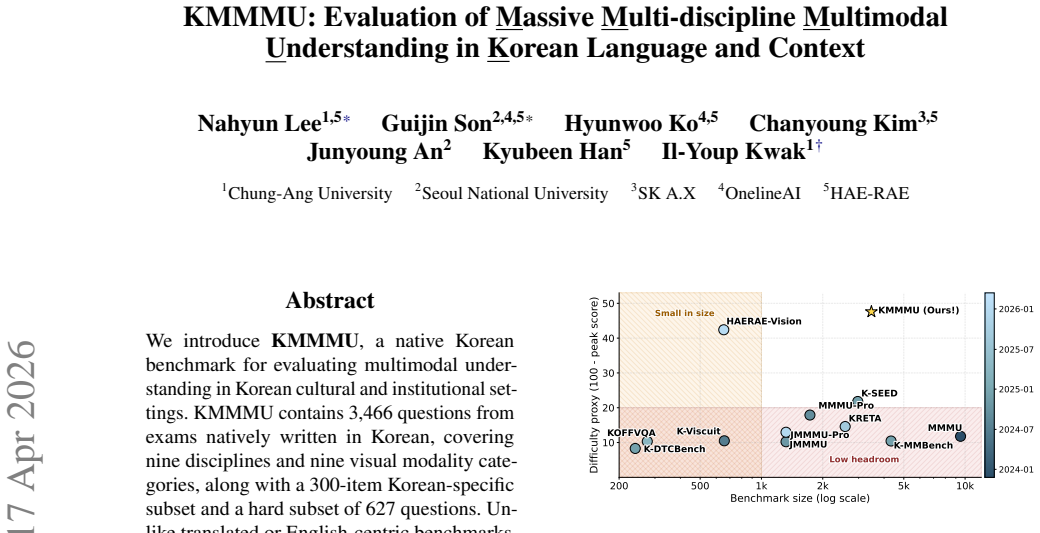
KMMMU contains 3,466 questions drawn from Korean exams that cover nine disciplines and nine visual modality categories, plus a 300-item Korean-specific subset and a 627-item hard subset. Leading open-source models achieve 42.05 percent accuracy on the full set, while the best proprietary model reaches 52.42 percent only on the hard subset. Accuracy varies sharply by discipline and falls further on Korean-specific questions by up to 13.43 percent. Failures arise mainly from weak convention-to-label mapping, few-shot symbolic induction, localized knowledge recall, and domain-specific standards understanding rather than from insufficient reasoning depth.
What carries the argument
The KMMMU benchmark itself, built from native Korean exam questions that embed local cultural conventions and visual formats.
Load-bearing premise
The selected Korean exam questions and visual formats represent the distribution of real-world Korean multimodal tasks without major selection bias toward certain topics or difficulty levels.
What would settle it
A new collection of Korean exam or workplace questions, collected independently, on which the same models achieve markedly higher accuracy than the 42 percent reported here would indicate the benchmark overstates the difficulty of typical Korean multimodal tasks.
Figures

















read the original abstract
We introduce KMMMU, a native Korean benchmark for evaluating multimodal understanding in Korean cultural and institutional settings. KMMMU contains 3,466 questions from exams natively written in Korean, covering nine disciplines and nine visual modality categories, along with a 300-item Korean-specific subset and a hard subset of 627 questions. Unlike translated or English-centric benchmarks, KMMMU targets information-dense problems shaped by local conventions, official standards, and discipline-specific visual formats. Experiments show that the strongest open-source model reaches only 42.05% accuracy on the full set, while the best proprietary model achieves 52.42% on the hard subset. Performance varies across disciplines, with some disciplines emerging as bottlenecks, and Korean-specific questions showing gaps of up to 13.43%. Error analysis suggests that these failures stem less from insufficient reasoning depth than from weak convention-to-label mapping, few-shot symbolic induction, localized knowledge recall, and domain-specific standards understanding. KMMMU provides a testbed for multimodal evaluation beyond English-centric benchmarks and for developing more reliable systems for expert real-world tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces KMMMU, a benchmark of 3,466 questions drawn from native Korean exams spanning nine disciplines and nine visual modality categories. It includes a 300-item Korean-specific subset and a 627-question hard subset. Model evaluations report that the strongest open-source model achieves 42.05% accuracy on the full set while the best proprietary model reaches 52.42% on the hard subset, with performance varying by discipline and showing drops of up to 13.43% on Korean-specific items. Error analysis attributes failures primarily to weak convention-to-label mapping, localized knowledge recall, and domain-specific standards rather than insufficient reasoning depth.
Significance. If the subset construction is free of selection bias, KMMMU supplies a concrete, non-English multimodal testbed that quantifies gaps in handling culturally embedded visual and institutional content. The reported accuracy ceilings and discipline-specific bottlenecks provide falsifiable targets for future model development and underscore the limitations of English-centric training for expert-level tasks in other languages.
major comments (1)
- [Abstract and benchmark construction] Abstract and benchmark construction section: The headline claim that Korean-specific questions produce gaps of up to 13.43% (and that these reflect localized knowledge rather than difficulty) rests on the unverified assumption that the 300-item subset and 627 hard questions are representative samples. No sampling protocol, inter-annotator agreement statistics for the 'Korean-specific' label, or comparative difficulty/visual-density distributions between the full set and the subsets are reported. If harder or more visually complex items were over-selected for the Korean-specific subset, the observed gaps could be artifacts of curation rather than evidence of model deficiencies in convention-to-label mapping.
minor comments (2)
- [Experiments] Experiments section: Full details on prompting templates, few-shot examples, and any post-processing of model outputs should be provided to confirm that the accuracy numbers (42.05%, 52.42%) are not sensitive to undocumented choices.
- [Error analysis] Error analysis: The categorization of errors into 'weak convention-to-label mapping' versus 'insufficient reasoning' would benefit from quantitative inter-annotator agreement on the error labels and a breakdown by visual modality.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive feedback. We address the concern about subset representativeness and construction details below, and commit to adding the requested clarifications and statistics in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract and benchmark construction] Abstract and benchmark construction section: The headline claim that Korean-specific questions produce gaps of up to 13.43% (and that these reflect localized knowledge rather than difficulty) rests on the unverified assumption that the 300-item subset and 627 hard questions are representative samples. No sampling protocol, inter-annotator agreement statistics for the 'Korean-specific' label, or comparative difficulty/visual-density distributions between the full set and the subsets are reported. If harder or more visually complex items were over-selected for the Korean-specific subset, the observed gaps could be artifacts of curation rather than evidence of model deficiencies in convention-to-label mapping.
Authors: We appreciate the referee highlighting the importance of transparency in subset construction. The 300-item Korean-specific subset was selected by native Korean domain experts who reviewed questions for explicit reliance on localized conventions, regulations, or cultural/institutional knowledge unique to Korea (e.g., specific Korean legal standards or historical references not covered in international equivalents). The 627-question hard subset was constructed by first running preliminary model evaluations and then supplementing with expert judgment on items requiring dense visual interpretation or multi-step domain reasoning. We acknowledge that the original manuscript did not include a full sampling protocol description, inter-annotator agreement figures, or comparative difficulty/visual-density statistics. In the revision we will add a dedicated subsection detailing the exact selection criteria and process, report inter-annotator agreement for the Korean-specific labeling (performed by multiple experts), and include side-by-side comparisons of metrics such as average token length, number of answer choices, proportion of image-containing questions, and image modality distribution across the full set, Korean-specific subset, and hard subset. These additions will allow readers to assess whether the observed 13.43% gaps are attributable to curation bias or to the intended factors of localized knowledge and convention-to-label mapping. revision: yes
Circularity Check
No circularity: pure empirical benchmark evaluation
full rationale
The paper introduces KMMMU as a fixed benchmark of 3,466 exam questions and reports direct accuracy measurements on it (e.g., 42.05% for the strongest open-source model). No equations, fitted parameters, predictions, or derivations appear anywhere in the manuscript. Performance gaps and error analysis are computed from model outputs on the held-out test items; nothing reduces to prior quantities by construction. Self-citations, if present, are not load-bearing for any result. The evaluation is self-contained against external model runs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Byungjin Choi, Seongsu Bae, Sunjun Kweon, and Ed- ward Choi
Varco-vision-2.0 technical report.arXiv preprint arXiv:2509.10105. Byungjin Choi, Seongsu Bae, Sunjun Kweon, and Ed- ward Choi. 2026a. Kormedmcqa-v: A multimodal benchmark for evaluating vision-language models on the korean medical licensing examination.arXiv preprint arXiv:2602.13650. Dasol Choi, Guijin Son, Hanwool Lee, Minhyuk Kim, Hyunwoo Ko, Teabin L...
-
[2]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language under- standing.arXiv preprint arXiv:2009.03300. Seokhee Hong, Sunkyoung Kim, Guijin Son, Soyeon Kim, Yeonjung Hong, and Jinsik Lee. 2025. From kmmlu-redux to kmmlu-pro: A professional korean benchmark suite for llm evaluation.arXiv preprint arXiv:2507.08924. Taebaek Hwang, Minseo Kim, Gisang Lee, Seonuk Kim, and Hyunj...
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[3]
Data cleaning and de-duplication.We first remove samples with invalid image links and de-duplicate near-duplicate questions across exam years using image and text similarity checks
-
[4]
Model-based adversarial filtering.We then sequentially filter the remaining candidate pool using four multimodal models: PHI- 3.5-VISION-INSTRUCT(Abdin et al., 2024), INTERNVL-3.5-38B (Wang et al., 2025), GEMINI-2.5-FLASH-LITE, and GEMINI-2.5- FLASH(Comanici et al., 2025). Each model is evaluated in a zero-shot setting, and questions answered correctly at...
work page 2024
-
[5]
extraction area slope criteria
Final retention.Only questions that remain unsolved after all four filtering stages are re- tained in the final benchmark. The resulting KMMMU benchmark contains 3,466curated questions. Figure 7:Annotation tool interface used for OCR verification.The tool displays the original PDF page on the left and the parsed text and images on the right, allowing anno...
work page 2015
-
[6]
Parallel - tw o parallel wings. 3 . Or t hogonal ( or cr oss) - wit h wings at right angles. The Villa Medici in Fiesole is consider ed an e xample of t he or t hogonal plan. So if t he image sho ws a cr oss shape (v er tical and horiz ontal ax es), t hen it's 직교형 and t he villa is 메디치장. So option 3 . </t hink> corr ect option: $\ \bo x ed{(3) 직교형-메디치장}$ ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.