GeoLink: A 3D-Aware Framework Towards Better Generalization in Cross-View Geo-Localization
Pith reviewed 2026-05-10 15:08 UTC · model grok-4.3
The pith
GeoLink uses offline 3D point clouds to refine 2D features for better generalization in cross-view geo-localization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By reconstructing scene point clouds offline with VGGT from multi-view drone images and using these as 3D anchors, the Geometric-aware Semantic Refinement module reduces redundant and view-biased dependencies in 2D features, while the Unified View Relation Distillation module transfers 3D structural relations into the 2D pipeline, yielding representations that generalize better across unseen domains and diverse weather environments.
What carries the argument
Offline 3D point cloud reconstruction from drone images that supplies structural priors to guide two 2D learning modules: Geometric-aware Semantic Refinement for reducing biases and Unified View Relation Distillation for transferring relations.
If this is right
- Superior matching performance on multiple cross-view geo-localization benchmarks compared to prior methods.
- Enhanced ability to handle domain shifts to entirely new geographic regions.
- Robustness to variations in weather and environmental conditions during inference.
- Preservation of computational efficiency since 3D reconstruction occurs only offline and inference remains 2D-only.
Where Pith is reading between the lines
- Similar 3D-to-2D distillation could improve other viewpoint-invariant tasks like object recognition under domain shift.
- The reliance on drone multi-view data for reconstruction suggests potential extensions to scenarios where such data is available during training but not testing.
- If reconstruction quality varies, performance might correlate with the accuracy of the 3D priors in specific environments.
Load-bearing premise
The 3D reconstructions from VGGT must supply stable and unbiased structural information that reliably improves 2D feature learning without being disrupted by reconstruction inaccuracies or mismatches with the target 2D views.
What would settle it
Running the method on a new benchmark with significant domain shift and weather variation where its accuracy does not exceed that of leading 2D-only baselines would indicate the 3D guidance is not providing the claimed benefit.
Figures
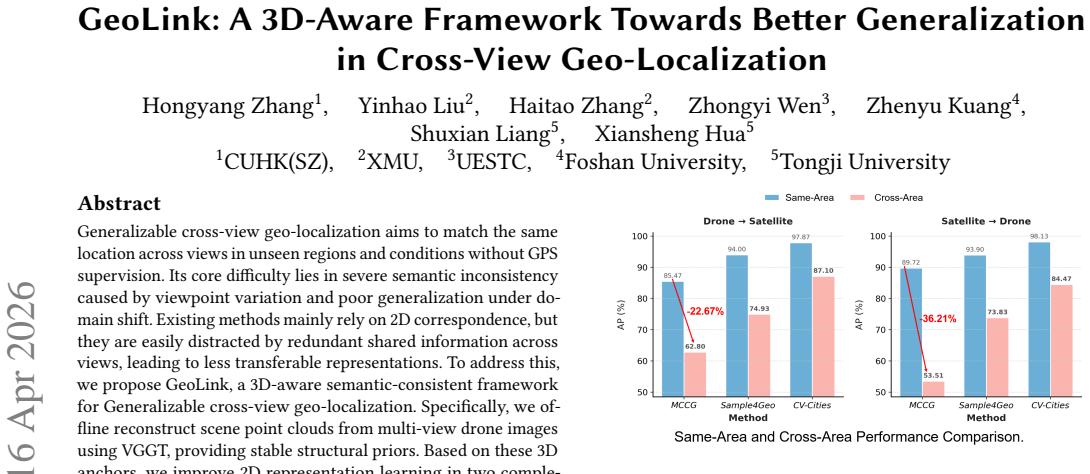






read the original abstract
Generalizable cross-view geo-localization aims to match the same location across views in unseen regions and conditions without GPS supervision. Its core difficulty lies in severe semantic inconsistency caused by viewpoint variation and poor generalization under domain shift. Existing methods mainly rely on 2D correspondence, but they are easily distracted by redundant shared information across views, leading to less transferable representations. To address this, we propose GeoLink, a 3D-aware semantic-consistent framework for Generalizable cross-view geo-localization. Specifically, we offline reconstruct scene point clouds from multi-view drone images using VGGT, providing stable structural priors. Based on these 3D anchors, we improve 2D representation learning in two complementary ways. A Geometric-aware Semantic Refinement module mitigates potentially redundant and view-biased dependencies in 2D features under 3D guidance. In addition, a Unified View Relation Distillation module transfers 3D structural relations to 2D features, improving cross-view alignment while preserving a 2D-only inference pipeline. Extensive experiments on multiple benchmarks show that GeoLink consistently outperforms state-of-the-art methods and achieves superior generalization across unseen domains and diverse weather environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes GeoLink, a 3D-aware framework for generalizable cross-view geo-localization. It performs offline 3D point cloud reconstruction from multi-view drone images using VGGT to obtain structural priors. These priors inform two modules: Geometric-aware Semantic Refinement, which reduces redundant and view-biased dependencies in 2D features, and Unified View Relation Distillation, which transfers 3D structural relations into 2D representations. The method preserves a 2D-only inference pipeline and claims consistent outperformance over prior methods together with superior generalization to unseen regions and weather conditions.
Significance. If the reported gains hold under rigorous validation, the framework offers a practical route to inject geometric consistency into 2D cross-view matching without incurring 3D cost at test time. This could strengthen robustness against viewpoint-induced semantic inconsistency, a persistent bottleneck in the field. The offline reconstruction plus distillation design is a pragmatic strength for deployment scenarios.
major comments (2)
- [§3] §3 (Method description): The central generalization claim rests on the assumption that VGGT-derived point clouds supply stable, unbiased structural priors. No quantitative assessment of reconstruction accuracy, error propagation under weather or geometric shifts, or sensitivity analysis is referenced, leaving open the possibility that domain-specific artifacts are distilled into the 2D features.
- [§4] §4 (Experiments): The abstract asserts that 'extensive experiments on multiple benchmarks show consistent outperformance' and 'superior generalization,' yet the manuscript summary supplies no tables, numerical deltas, error bars, ablation results, or dataset statistics. Without these load-bearing details the superiority and generalization claims cannot be evaluated.
minor comments (2)
- [Abstract] Abstract: Key quantitative highlights (e.g., mAP or recall improvements on the primary benchmarks) should be inserted to allow readers to gauge the magnitude of the claimed gains.
- [§3.2] Notation: The precise mathematical formulation of how 3D anchors modulate the 2D attention or distillation losses is not immediately clear from the high-level description; an equation or pseudocode block would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and have revised the manuscript to strengthen the presentation of our claims.
read point-by-point responses
-
Referee: [§3] §3 (Method description): The central generalization claim rests on the assumption that VGGT-derived point clouds supply stable, unbiased structural priors. No quantitative assessment of reconstruction accuracy, error propagation under weather or geometric shifts, or sensitivity analysis is referenced, leaving open the possibility that domain-specific artifacts are distilled into the 2D features.
Authors: We agree that explicit validation of the VGGT priors would better support the generalization claims. Although VGGT is employed offline and the inference pipeline remains 2D-only, we have added a new subsection in Section 3 that reports reconstruction accuracy metrics (completeness and accuracy) on the evaluation datasets, together with sensitivity analysis under simulated weather and viewpoint shifts. These results indicate limited error propagation into the distilled 2D features and are now included in the revised manuscript. revision: yes
-
Referee: [§4] §4 (Experiments): The abstract asserts that 'extensive experiments on multiple benchmarks show consistent outperformance' and 'superior generalization,' yet the manuscript summary supplies no tables, numerical deltas, error bars, ablation results, or dataset statistics. Without these load-bearing details the superiority and generalization claims cannot be evaluated.
Authors: The full manuscript already contains Section 4 with tables reporting numerical performance deltas, ablation studies on both proposed modules, error bars from repeated runs, and dataset statistics across benchmarks. These results directly support the outperformance and cross-domain generalization claims. We have clarified the experimental presentation in the revision to make the supporting evidence more immediately accessible. revision: partial
Circularity Check
No significant circularity in GeoLink's 3D-guided 2D framework
full rationale
The paper's core chain uses an independent external tool (VGGT) for offline 3D point cloud reconstruction from drone images as input priors. These priors then inform two architectural modules (Geometric-aware Semantic Refinement and Unified View Relation Distillation) that refine 2D features during training, with 2D-only inference. This does not reduce to self-definition, fitted parameters renamed as predictions, or self-citation chains, as the 3D input is generated separately and the claimed generalization gains are presented as empirical outcomes on benchmarks rather than derived tautologically from the inputs. No equations or load-bearing self-citations are shown that collapse the result to its own assumptions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Offline multi-view 3D reconstruction using VGGT supplies stable structural priors for guiding 2D feature learning
- domain assumption Transferring 3D structural relations improves cross-view alignment in 2D features without harming inference
Reference graph
Works this paper leans on
-
[1]
Amar Ali-Bey, Brahim Chaib-Draa, and Philippe Giguere. 2023. Mixvpr: Fea- ture mixing for visual place recognition. InProceedings of the IEEE/CVF winter conference on applications of computer vision. 2998–3007
work page 2023
-
[2]
Jiajing Chen, Minmin Yang, and Senem Velipasalar. 2024. Letting 3D Guide the Way: 3D Guided 2D Few-Shot Image Classification. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2732–2740
work page 2024
-
[3]
Pengyu Cheng, Weituo Hao, Shuyang Dai, Jiachang Liu, Zhe Gan, and Lawrence Carin. 2020. Club: A contrastive log-ratio upper bound of mutual information. In International conference on machine learning. PMLR, 1779–1788
work page 2020
-
[4]
Ming Dai, Enhui Zheng, Zhenhua Feng, Lei Qi, Jiedong Zhuang, and Wankou Yang. 2023. Vision-based UAV self-positioning in low-altitude urban environ- ments.IEEE Transactions on Image Processing33 (2023), 493–508
work page 2023
-
[5]
Yongxing Dai, Xiaotong Li, Jun Liu, Zekun Tong, and Ling-Yu Duan. 2021. Gen- eralizable person re-identification with relevance-aware mixture of experts. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 16145–16154
work page 2021
-
[6]
Fabian Deuser, Konrad Habel, and Norbert Oswald. 2023. Sample4geo: Hard negative sampling for cross-view geo-localisation. InProceedings of the IEEE/CVF International Conference on Computer Vision. 16847–16856
work page 2023
-
[7]
Tongtong Feng, Qing Li, Xin Wang, Mingzi Wang, Guangyao Li, and Wenwu Zhu. 2024. Multi-weather cross-view geo-localization using denoising diffusion models. InProceedings of the 2nd Workshop on UA Vs in Multimedia: Capturing the World from a New Perspective. 35–39
work page 2024
-
[8]
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. 2020. Generative adversarial networks.Commun. ACM63, 11 (2020), 139–144
work page 2020
-
[9]
Michael Gutmann and Aapo Hyvärinen. 2010. Noise-contrastive estimation: A new estimation principle for unnormalized statistical models. InProceedings of the thirteenth international conference on artificial intelligence and statistics. JMLR Workshop and Conference Proceedings, 297–304
work page 2010
-
[10]
Christian Häne, Lionel Heng, Gim Hee Lee, Friedrich Fraundorfer, Paul Furgale, Torsten Sattler, and Marc Pollefeys. 2017. 3D visual perception for self-driving cars using a multi-camera system: Calibration, mapping, localization, and obstacle detection.Image and Vision Computing68 (2017), 14–27
work page 2017
-
[11]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising diffusion probabilistic models.Advances in neural information processing systems33 (2020), 6840–6851
work page 2020
-
[12]
Ji Hou, Saining Xie, Benjamin Graham, Angela Dai, and Matthias Nießner. 2021. Pri3d: Can 3d priors help 2d representation learning?. InProceedings of the IEEE/CVF International Conference on Computer Vision. 5693–5702
work page 2021
-
[13]
Shuyu Hu, Zelin Shi, Tong Jin, and Yunpeng Liu. 2025. Query-Driven Feature Learning for Cross-View Geo-Localization.IEEE Transactions on Geoscience and Remote Sensing(2025)
work page 2025
-
[14]
Gaoshuang Huang, Yang Zhou, Luying Zhao, and Wenjian Gan. 2024. Cv-cities: Advancing cross-view geo-localization in global cities.IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing(2024)
work page 2024
-
[15]
Yuxiang Ji, Boyong He, Zhuoyue Tan, and Liaoni Wu. 2025. Game4loc: A uav geo- localization benchmark from game data. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 3913–3921
work page 2025
-
[16]
Yuxiang Ji, Boyong He, Zhuoyue Tan, and Liaoni Wu. 2025. MMGeo: Multi- modal Compositional Geo-Localization for UAVs. InProceedings of the IEEE/CVF International Conference on Computer Vision. 25165–25175
work page 2025
- [17]
-
[18]
Haoyuan Li, Chang Xu, Wen Yang, Li Mi, Huai Yu, Haijian Zhang, and Gui-Song Xia. 2025. Unsupervised Multi-view UAV Image Geo-localization via Iterative Rendering.IEEE Transactions on Geoscience and Remote Sensing(2025)
work page 2025
- [19]
-
[20]
Ilya Loshchilov and Frank Hutter. 2017. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[21]
Laurens van der Maaten and Geoffrey Hinton. 2008. Visualizing data using t-SNE. Journal of machine learning research9, Nov (2008), 2579–2605
work page 2008
-
[22]
Colin McManus, Winston Churchill, Will Maddern, Alexander D Stewart, and Paul Newman. 2014. Shady dealings: Robust, long-term visual localisation using illumination invariance. In2014 IEEE international conference on robotics and automation (ICRA). IEEE, 901–906
work page 2014
-
[23]
Li Mi, Chang Xu, Javiera Castillo-Navarro, Syrielle Montariol, Wen Yang, Antoine Bosselut, and Devis Tuia. 2024. Congeo: Robust cross-view geo-localization across ground view variations. InEuropean Conference on Computer Vision. Springer, 214–230
work page 2024
-
[24]
Maxime Oquab, Timothée Darcet, Theo Moutakanni, Huy V. Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Russell Howes, Po-Yao Huang, Hu Xu, Vasu Sharma, Shang-Wen Li, Wojciech Galuba, Mike Rabbat, Mido Assran, Nicolas Ballas, Gabriel Synnaeve, Ishan Misra, Herve Jegou, Julien Mairal, Patrick Labatu...
work page 2023
-
[25]
Paul-Edouard Sarlin, Daniel DeTone, Tsun-Yi Yang, Armen Avetisyan, Julian Straub, Tomasz Malisiewicz, Samuel Rota Bulo, Richard Newcombe, Peter Kontschieder, and Vasileios Balntas. 2023. Orienternet: Visual localization in 2d public maps with neural matching. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 21632–21642
work page 2023
-
[26]
Tianrui Shen, Yingmei Wei, Lai Kang, Shanshan Wan, and Yee-Hong Yang
-
[27]
MCCG: A ConvNeXt-based multiple-classifier method for cross-view geo-localization.IEEE Transactions on Circuits and Systems for Video Technology 34, 3 (2023), 1456–1468
work page 2023
-
[28]
Yujiao Shi, Liu Liu, Xin Yu, and Hongdong Li. 2019. Spatial-aware feature aggrega- tion for cross-view image based geo-localization.Advances in Neural Information Processing Systems32 (2019)
work page 2019
-
[29]
Tavis Shore, Simon Hadfield, and Oscar Mendez. 2024. BEV-CV: Birds-eye- view transform for cross-view geo-localisation. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 11048–11055
work page 2024
-
[31]
Aysim Toker, Qunjie Zhou, Maxim Maximov, and Laura Leal-Taixé. 2021. Coming down to earth: Satellite-to-street view synthesis for geo-localization. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 6488–6497
work page 2021
-
[32]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in neural information processing systems30 (2017)
work page 2017
-
[33]
Xueyi Wang, Lele Zhang, Zheng Fan, Yang Liu, Chen Chen, and Fang Deng. 2025. From Coarse to Fine: A Matching and Alignment Framework for Unsupervised Cross-View Geo-Localization. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 8024–8032
work page 2025
-
[34]
Yuntao Wang, Jinpu Zhang, Ruonan Wei, Wenbo Gao, and Yuehuan Wang. 2024. Mfrgn: Multi-scale feature representation generalization network for ground-to- aerial geo-localization. InProceedings of the 32nd ACM International Conference on Multimedia. 2574–2583
work page 2024
-
[35]
Panwang Xia, Yi Wan, Zhi Zheng, Yongjun Zhang, and Jiwei Deng. 2024. Enhanc- ing cross-view geo-localization with domain alignment and scene consistency. IEEE Transactions on Circuits and Systems for Video Technology(2024)
work page 2024
-
[36]
Zelong Zeng, Zheng Wang, Fan Yang, and Shin’Ichi Satoh. 2023. Geo-Localization via Ground-to-Satellite Cross-View Image Retrieval.Multimedia, IEEE Trans. on (T-MM)25, 000 (2023), 13
work page 2023
-
[37]
Linfeng Zhang, Runpei Dong, Hung-Shuo Tai, and Kaisheng Ma. 2023. Point- distiller: Structured knowledge distillation towards efficient and compact 3d detection. InProceedings of the IEEE/CVF conference on computer vision and pat- tern recognition. 21791–21801
work page 2023
-
[38]
Qingwang Zhang and Yingying Zhu. 2024. Aligning geometric spatial layout in cross-view geo-localization via feature recombination. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 7251–7259
work page 2024
-
[39]
Renrui Zhang, Liuhui Wang, Yali Wang, Peng Gao, Hongsheng Li, and Jianbo Shi. 2023. Starting from non-parametric networks for 3d point cloud analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 5344–5353
work page 2023
-
[40]
Hu Zhao, Keyan Ren, Tianyi Yue, Chun Zhang, and Shuai Yuan. 2024. TransFG: A cross-view geo-localization of satellite and UAVs imagery pipeline using transformer-based feature aggregation and gradient guidance.IEEE Transactions on Geoscience and Remote Sensing62 (2024), 1–12
work page 2024
-
[41]
Zhedong Zheng, Yunchao Wei, and Yi Yang. 2020. University-1652: A multi-view multi-source benchmark for drone-based geo-localization. InProceedings of the 28th ACM international conference on Multimedia. 1395–1403. Conference’17, July 2017, Washington, DC, USA Hongyang Zhang1, Yinhao Liu 2, Haitao Zhang 2, Zhongyi Wen 3, Zhenyu Kuang 4, Shuxian Liang 5, X...
work page 2020
-
[42]
Runzhe Zhu, Ling Yin, Mingze Yang, Fei Wu, Yuncheng Yang, and Wenbo Hu
-
[43]
SUES-200: A multi-height multi-scene cross-view image benchmark across drone and satellite.IEEE Transactions on Circuits and Systems for Video Technology 33, 9 (2023), 4825–4839
work page 2023
-
[44]
Sijie Zhu, Mubarak Shah, and Chen Chen. 2022. Transgeo: Transformer is all you need for cross-view image geo-localization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1162–1171. Received 20 February 2007; revised 12 March 2009; accepted 5 June 2009
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.