Outperforming Self-Attention Mechanisms in Solar Irradiance Forecasting via Physics-Guided Neural Networks
Pith reviewed 2026-05-10 14:11 UTC · model grok-4.3
The pith
A physics-guided CNN-BiLSTM with fifteen engineered features outperforms self-attention models on solar irradiance forecasts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A lightweight Physics-Informed Hybrid CNN-BiLSTM framework that ingests a vector of fifteen engineered physical features achieves an RMSE of 19.53 W/m² on NASA POWER Sudan data, beating attention-based baselines that reach 30.64 W/m² and thereby establishing that explicit physical constraints supply a more efficient and accurate alternative to self-attention mechanisms in high-noise meteorological forecasting tasks.
What carries the argument
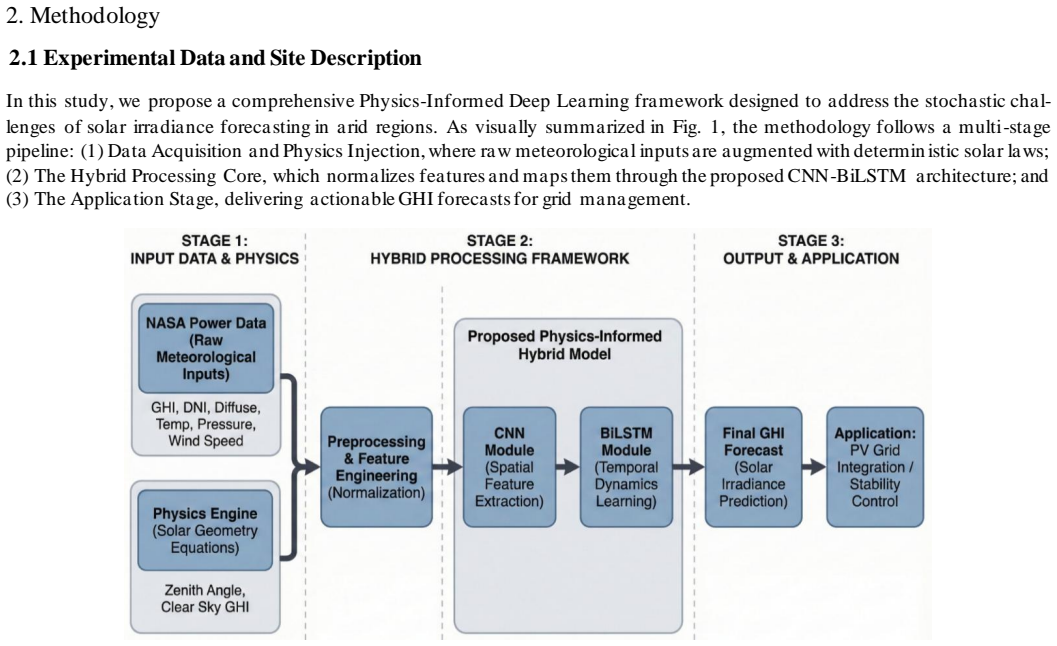
The Physics-Informed Hybrid CNN-BiLSTM framework that processes fifteen engineered features including Clear-Sky indices and Solar Zenith Angle to enforce physical consistency while extracting spatial and temporal patterns.
If this is right
- Grid operators in arid zones can achieve stable renewable integration with lighter, physics-constrained models instead of heavy Transformer stacks.
- Bayesian hyperparameter search combined with domain features reduces the need for ever-deeper architectures in meteorological prediction.
- Real-time solar management systems become more deployable on modest hardware when explicit physical priors replace raw-data attention layers.
- The approach directly supports renewable-energy forecasting pipelines that must operate under rapid aerosol and zenith-angle changes.
Where Pith is reading between the lines
- The same pattern of replacing attention with physical feature engineering may extend to other high-variability forecasting problems such as wind power or short-term precipitation.
- If the complexity paradox holds, model-selection practice in environmental AI could shift toward systematic injection of domain equations rather than default scaling of attention depth.
- Validation across multiple climates would reveal whether the fifteen-feature vector generalizes or requires location-specific re-engineering of the physical priors.
Load-bearing premise
The observed performance advantage and the engineered feature set will continue to hold when the same architecture and baselines are applied to new geographic regions, different time spans, or independently reimplemented attention models.
What would settle it
Retraining the identical CNN-BiLSTM pipeline on an independent arid-region dataset and finding that its RMSE no longer beats properly configured attention baselines, or that the gap vanishes once baseline training details are matched, would falsify the central claim.
Figures
read the original abstract
Accurate Global Horizontal Irradiance (GHI) forecasting is critical for grid stability, particularly in arid regions characterized by rapid aerosol fluctuations. While recent trends favor computationally expensive Transformer-based architectures, this paper challenges the prevailing "complexity-first" paradigm. We propose a lightweight, Physics-Informed Hybrid CNN-BiLSTM framework that prioritizes domain knowledge over architectural depth. The model integrates a Convolutional Neural Network (CNN) for spatial feature extraction with a Bi-Directional LSTM for capturing temporal dependencies. Unlike standard data-driven approaches, our model is explicitly guided by a vector of 15 engineered features including Clear-Sky indices and Solar Zenith Angle - rather than relying solely on raw historical data. Hyperparameters are rigorously tuned using Bayesian Optimization to ensure global optimality. Experimental validation using NASA POWER data in Sudan demonstrates that our physics-guided approach achieves a Root Mean Square Error (RMSE) of 19.53 W/m^2, significantly outperforming complex attention-based baselines (RMSE 30.64 W/m^2). These results confirm a "Complexity Paradox": in high-noise meteorological tasks, explicit physical constraints offer a more efficient and accurate alternative to self-attention mechanisms. The findings advocate for a shift towards hybrid, physics-aware AI for real-time renewable energy management.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a Physics-Informed Hybrid CNN-BiLSTM model for Global Horizontal Irradiance (GHI) forecasting that incorporates 15 engineered physical features such as Clear-Sky indices and Solar Zenith Angle. It claims that this lightweight approach achieves an RMSE of 19.53 W/m² on NASA POWER data from Sudan, outperforming complex attention-based baselines with RMSE of 30.64 W/m², and introduces the 'Complexity Paradox' suggesting that explicit physical constraints are more effective than self-attention in high-noise meteorological tasks.
Significance. If the reported performance advantage is robust and attributable to the physics-guided design rather than differences in input representation or optimization, the work would be significant for the machine learning applications in renewable energy. It provides empirical evidence challenging the trend towards increasingly complex Transformer architectures in favor of hybrid models that leverage domain knowledge, potentially leading to more efficient and interpretable forecasting systems for grid stability in arid regions.
major comments (2)
- [Abstract and Experimental Validation] The central claim that the physics-guided CNN-BiLSTM outperforms self-attention mechanisms (RMSE 19.53 vs 30.64 W/m²) and supports the Complexity Paradox depends on a fair comparison. The abstract provides no information on whether the attention baselines received the same 15 engineered features or were trained on raw sequences, nor on their hyperparameter tuning protocol. If the baselines lacked the engineered features, the gap reflects feature engineering rather than architecture or physics guidance.
- [Experimental Validation] The reported RMSE values lack error bars, data-split details (train/validation/test ratios or temporal cross-validation), and statistical significance tests. Given the use of Bayesian optimization for hyperparameter tuning and selection of the 15 features, these omissions prevent assessment of whether the performance difference is reliable or could arise from post-hoc choices.
minor comments (2)
- [Abstract] The 'Complexity Paradox' is asserted but not formally defined or positioned against prior literature on model complexity versus domain knowledge in time-series forecasting.
- [Abstract] Specific attention-based baseline architectures (e.g., Transformer variants) and their exact configurations are not named.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our experimental comparisons and validation. We address each major point below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and Experimental Validation] The central claim that the physics-guided CNN-BiLSTM outperforms self-attention mechanisms (RMSE 19.53 vs 30.64 W/m²) and supports the Complexity Paradox depends on a fair comparison. The abstract provides no information on whether the attention baselines received the same 15 engineered features or were trained on raw sequences, nor on their hyperparameter tuning protocol. If the baselines lacked the engineered features, the gap reflects feature engineering rather than architecture or physics guidance.
Authors: We agree that the abstract should explicitly state the input configuration for the baselines to avoid ambiguity. In the full manuscript, the self-attention baselines were provided with the identical set of 15 engineered physical features (including Clear-Sky indices and Solar Zenith Angle) as our CNN-BiLSTM model; the comparison isolates the effect of the physics-guided architecture versus self-attention. Hyperparameter tuning via Bayesian optimization was applied uniformly to all models using the same search space and validation protocol. We will revise the abstract and add a clear paragraph in the Experimental Setup section detailing the shared input representation and tuning procedure for all models. This will confirm that the reported advantage stems from the physics-informed design. revision: yes
-
Referee: [Experimental Validation] The reported RMSE values lack error bars, data-split details (train/validation/test ratios or temporal cross-validation), and statistical significance tests. Given the use of Bayesian optimization for hyperparameter tuning and selection of the 15 features, these omissions prevent assessment of whether the performance difference is reliable or could arise from post-hoc choices.
Authors: We acknowledge these omissions limit the ability to evaluate result reliability. The current manuscript reports single-point RMSE estimates. In the revision we will: (i) add error bars derived from five independent runs with different random seeds; (ii) explicitly state the temporal train/validation/test split (70/15/15 with non-overlapping periods to avoid leakage) and confirm no future data leakage; (iii) include statistical significance testing (paired t-test and Wilcoxon signed-rank test) between our model and each baseline; and (iv) expand the hyperparameter search description. These details will appear in the revised Experimental Validation and Results sections along with updated tables. revision: yes
Circularity Check
No circularity: claims rest on standard empirical ML evaluation
full rationale
The paper presents no mathematical derivation chain or first-principles result. Its central claims consist of RMSE numbers obtained by training a CNN-BiLSTM on 15 engineered features (with Bayesian hyperparameter tuning) and comparing against attention baselines on held-out NASA POWER data. This is ordinary supervised learning followed by test-set evaluation; the reported performance is not equivalent to the inputs by construction, nor does any step reduce to a self-citation, self-definition, or renamed fit. The 'Complexity Paradox' is an interpretive label placed on the empirical gap rather than a derived quantity. Potential issues with baseline input parity are experimental-design concerns, not circularity in any derivation.
Axiom & Free-Parameter Ledger
free parameters (2)
- Bayesian-optimized hyperparameters
- Selection and scaling of the 15 engineered features
axioms (2)
- domain assumption NASA POWER reanalysis data for Sudan is sufficiently accurate and representative for model validation
- domain assumption The chosen attention-based baselines are implemented and trained in a manner comparable to the proposed model
Reference graph
Works this paper leans on
-
[1]
https://doi.org/10.3390/en16021326 Bank, J., Mather, B., Keller, J., & Coddington, M. ( 2013). High penetration photovoltaic case study report (NREL/TP -5500 - 54742). National Renewable Energy Laboratory. https://doi.org/10.2172/1061635 Box, G. P., Jenkins, G. M., Reinsel, G. C., & Ljung, G. M. (2015). Time series analysis: Forecasting and cont rol (5th ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.3390/en16021326 2013
-
[2]
https://doi.org/10.1016/j.energy.2018.01.177 Radzi, P. N. L. M., Mekhilef, S., Stojcevski, A., Yamani, M., & Seyedmahmoudian, M. (2025 ). Optimizing sol ar power forecast- ing with metaheuristic algorithms and deep learning models for photovoltaic grid connected systems. Scientific Reports , 15, 38435. https://doi.org/10.1038/s41598 -025-24134-0 Voyant, C...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.