Sentiment analysis for software engineering: How far can zero-shot learning (ZSL) go?
Pith reviewed 2026-05-10 12:44 UTC · model grok-4.3
The pith
Zero-shot learning techniques can match the performance of fine-tuned models in software engineering sentiment analysis using expert-curated labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
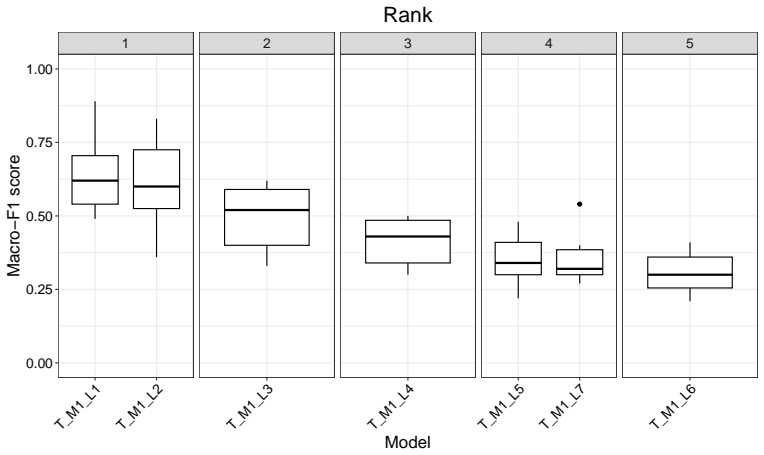
The study demonstrates that zero-shot learning techniques, particularly those that combine expert-curated labels with embedding-based or generative-based models, can achieve macro-F1 scores comparable to those of fine-tuned transformer-based models for sentiment analysis in software engineering. This capability addresses the challenge of annotated dataset scarcity by reducing the need for extensive domain-specific labeling efforts.
What carries the argument
Zero-shot learning applied to sentiment classification tasks, where models classify text into sentiment categories using pre-trained knowledge and label descriptions without task-specific fine-tuning data.
If this is right
- Zero-shot learning provides a viable alternative to supervised learning for sentiment analysis in software engineering.
- Expert-curated labels significantly boost the performance of embedding-based and generative zero-shot methods.
- Different configurations of labels influence the effectiveness of zero-shot techniques.
- Subjectivity in annotations and polar factual statements are primary sources of classification errors.
- Adopting zero-shot methods can lower the barrier to developing sentiment analysis tools tailored to software engineering contexts.
Where Pith is reading between the lines
- Zero-shot learning could be applied to other label-scarce tasks in software engineering such as defect prediction or requirement classification.
- Integrating zero-shot methods with active learning might further reduce the amount of expert input needed.
- Results suggest that improving label quality could be more impactful than refining the zero-shot models themselves.
- Broader adoption might enable real-time sentiment monitoring in large code repositories without prior training.
Load-bearing premise
The tested datasets and zero-shot implementations are representative of typical software engineering sentiment analysis scenarios.
What would settle it
Observing substantially lower macro-F1 scores for the best zero-shot methods compared to fine-tuned models on a new, independently collected software engineering dataset would indicate the comparability does not hold generally.
Figures










read the original abstract
Sentiment analysis in software engineering focuses on understanding emotions expressed in software artifacts. Previous research highlighted the limitations of applying general off-the-shelf sentiment analysis tools within the software engineering domain and indicated the need for specialized tools tailored to various software engineering contexts. The development of such tools heavily relies on supervised machine learning techniques that necessitate annotated datasets. Acquiring such datasets is a substantial challenge, as it requires domain-specific expertise and significant effort. Objective: This study explores the potential of ZSL to address the scarcity of annotated datasets in sentiment analysis within software engineering Method:} We conducted an empirical experiment to evaluate the performance of various ZSL techniques, including embedding-based, NLI-based, TARS-based, and generative-based ZSL techniques. We assessed the performance of these techniques under different labels setups to examine the impact of label configurations. Additionally, we compared the results of the ZSL techniques with state-of-the-art fine-tuned transformer-based models. Finally, we performed an error analysis to identify the primary causes of misclassifications. Results: Our findings demonstrate that ZSL techniques, particularly those combining expert-curated labels with embedding-based or generative-based models, can achieve macro-F1 scores comparable to fine-tuned transformer-based models. The error analysis revealed that subjectivity in annotation and polar facts are the main contributors to ZSL misclassifications. Conclusion: This study demonstrates the potential of ZSL for sentiment analysis in software engineering. ZSL can provide a solution to the challenge of annotated dataset scarcity by reducing reliance on annotated dataset.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that zero-shot learning (ZSL) techniques, particularly embedding-based and generative-based models paired with expert-curated labels, can achieve macro-F1 scores comparable to fine-tuned transformer-based models for sentiment analysis in software engineering. It evaluates embedding-based, NLI-based, TARS-based, and generative-based ZSL approaches under varying label setups, compares them empirically to state-of-the-art supervised models, and uses error analysis to attribute misclassifications primarily to annotation subjectivity and polar facts, concluding that ZSL mitigates the need for annotated datasets.
Significance. If the comparability result holds under broader validation, the work would be significant for software engineering by lowering the barrier to sentiment analysis tools, which currently depend on costly domain-specific annotations. It offers empirical guidance on ZSL viability in SE contexts and highlights practical error sources that could inform hybrid approaches, potentially accelerating adoption where labeled data is scarce.
major comments (3)
- [Abstract] Abstract: The central claim that ZSL techniques 'can achieve macro-F1 scores comparable to fine-tuned transformer-based models' is presented without any quantitative scores, dataset sizes, label counts, or statistical tests, making it impossible to assess whether the comparability is meaningful or merely directional.
- [Error Analysis] Error Analysis: Subjectivity in annotation and polar facts are identified as primary misclassification drivers, yet these issues plausibly affect the ground-truth labels shared by both ZSL methods and the fine-tuned baselines; without inter-annotator agreement statistics or a differential error breakdown, the comparability result risks being an artifact of the chosen annotation process rather than a property of ZSL.
- [Conclusion] Conclusion: The claim that ZSL reduces reliance on annotated datasets rests on the untested assumption that the evaluated datasets and expert-curated label configurations are representative of typical SE sentiment variability; the absence of cross-dataset validation or equivalence testing leaves generalizability unsupported.
minor comments (1)
- [Abstract] Abstract contains a clear formatting artifact ('Method:} We conducted') with an extraneous closing brace that should be removed for readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of clarity, rigor, and scope that we will address in the revision. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that ZSL techniques 'can achieve macro-F1 scores comparable to fine-tuned transformer-based models' is presented without any quantitative scores, dataset sizes, label counts, or statistical tests, making it impossible to assess whether the comparability is meaningful or merely directional.
Authors: We agree that the abstract would benefit from greater specificity to allow readers to evaluate the strength of the comparability claim. In the revised version, we will incorporate key quantitative results from the experiments, including the macro-F1 scores for the best-performing ZSL configurations and the fine-tuned baselines, along with dataset sizes, label counts, and a brief note on the statistical comparisons performed. This change will make the central claim more concrete without altering the manuscript's findings. revision: yes
-
Referee: [Error Analysis] Error Analysis: Subjectivity in annotation and polar facts are identified as primary misclassification drivers, yet these issues plausibly affect the ground-truth labels shared by both ZSL methods and the fine-tuned baselines; without inter-annotator agreement statistics or a differential error breakdown, the comparability result risks being an artifact of the chosen annotation process rather than a property of ZSL.
Authors: This observation is fair and points to a limitation in our error analysis. Because both ZSL and fine-tuned models are assessed against identical ground-truth labels, the performance comparison remains valid as a measure of how each method performs on the same (potentially noisy) annotations typical of SE sentiment data. We did not compute or report inter-annotator agreement because the datasets originate from prior published studies in which such statistics were not provided. We will add a dedicated limitations paragraph acknowledging this and expand the error analysis section to include a side-by-side comparison of error categories across ZSL and supervised models. This will clarify that the identified error sources are task-inherent rather than method-specific. revision: partial
-
Referee: [Conclusion] Conclusion: The claim that ZSL reduces reliance on annotated datasets rests on the untested assumption that the evaluated datasets and expert-curated label configurations are representative of typical SE sentiment variability; the absence of cross-dataset validation or equivalence testing leaves generalizability unsupported.
Authors: We accept that the conclusion overstates generalizability. Our evaluation was conducted on multiple established SE sentiment datasets using expert-curated labels, yet we did not perform explicit cross-dataset validation or statistical equivalence testing. In the revised conclusion, we will explicitly qualify the claims to reflect the scope of the datasets and label setups examined in this study, while recommending broader validation as future work. This revision ensures the conclusion accurately represents the empirical evidence presented. revision: yes
Circularity Check
No circularity: standard empirical head-to-head evaluation of ZSL techniques
full rationale
The paper reports an empirical study that runs multiple ZSL variants (embedding-based, NLI-based, TARS-based, generative) on SE sentiment datasets under varying label setups, measures macro-F1, and directly compares the numbers to fine-tuned transformer baselines. No equations, fitted parameters, or predictions are defined in terms of the target result; the comparability claim is the observed experimental outcome, not a quantity forced by construction or by a self-citation chain. Error analysis is post-hoc inspection of misclassifications and does not retroactively define the performance metric. The work is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Pre-trained models for ZSL can transfer to the software engineering sentiment domain without domain-specific fine-tuning
- domain assumption Expert-curated labels provide a fair and unbiased basis for evaluating ZSL performance
Reference graph
Works this paper leans on
-
[1]
T. Zhang, B. Xu, F. Thung, S. A. Haryono, D. Lo, L. Jiang, Sentiment analysis for software engineering: How far can pre-trained transformer models go?, in: 2020 IEEE Intealefato2018sentimentrnational Confer- ence on Software Maintenance and Evolution (ICSME), IEEE, 2020, pp. 70–80
work page 2020
- [2]
- [3]
-
[4]
B. Lin, F. Zampetti, G. Bavota, M. Di Penta, M. Lanza, R. Oliveto, Sentiment analysis for software engineering: How far can we go?, in: Proceedings of the 40th international conference on software engineering, 2018, pp. 94–104
work page 2018
-
[5]
A. Sajadi, K. Damevski, P. Chatterjee, Towards understanding emotions in informal developer interactions: A gitter chat study, in: Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, 2023, pp. 2097– 2101
work page 2023
-
[6]
N. Novielli, F. Calefato, D. Dongiovanni, D. Girardi, F. Lanubile, Can we use se-specific sentiment analysis tools in a cross-platform setting?, in: Proceedings of the 17th International Conference on Mining Software Repositories, 2020, pp. 158–168. 33
work page 2020
- [7]
-
[8]
F. Calefato, F. Lanubile, F. Maiorano, N. Novielli, Sentiment polarity detection for software development, in: Proceedings of the 40th Inter- national Conference on Software Engineering, 2018, pp. 128–128
work page 2018
-
[9]
R. Jongeling, S. Datta, A. Serebrenik, Choosing your weapons: On sen- timent analysis tools for software engineering research, in: 2015 IEEE International Conference on Software Maintenance and Evolution (IC- SME), IEEE, 2015, pp. 531–535
work page 2015
-
[10]
P. Tourani, Y. Jiang, B. Adams, Monitoring sentiment in open source mailing lists: exploratory study on the apache ecosystem., in: CASCON, Vol. 14, 2014, pp. 34–44
work page 2014
-
[11]
N. Novielli, D. Girardi, F. Lanubile, A benchmark study on sentiment analysis for software engineering research, in: Proceedings of the 15th International Conference on Mining Software Repositories, 2018, pp. 364–375
work page 2018
-
[12]
B. Lin, N. Cassee, A. Serebrenik, G. Bavota, N. Novielli, M. Lanza, Opinion mining for software development: a systematic literature re- view, ACM Transactions on Software Engineering and Methodology (TOSEM) 31 (3) (2022) 1–41
work page 2022
-
[13]
L. Tunstall, L. Von Werra, T. Wolf, Natural language processing with transformers, ” O’Reilly Media, Inc.”, 2022
work page 2022
-
[14]
J. Alammar, M. Grootendorst, Hands-On Large Language Models: Lan- guage Understanding and Generation, ” O’Reilly Media, Inc.”, 2024
work page 2024
-
[15]
S. P. Veeranna, J. Nam, E. L. Mencıa, J. F¨ urnkranz, Using semantic similarity for multi-label zero-shot classification of text documents, in: Proceeding of european symposium on artificial neural networks, com- putational intelligence and machine learning. bruges, belgium: Elsevier, 2016, pp. 423–428
work page 2016
-
[16]
W. Alhoshan, A. Ferrari, L. Zhao, Zero-shot learning for requirements classification: An exploratory study, Information and Software Technol- ogy 159 (2023) 107202. 34
work page 2023
- [17]
- [18]
- [19]
-
[20]
M. S´ anchez-Gord´ on, R. Colomo-Palacios, Taking the emotional pulse of software engineering—a systematic literature review of empirical stud- ies, Information and Software Technology 115 (2019) 23–43
work page 2019
- [21]
-
[22]
M. R. Islam, M. F. Zibran, Sentistrength-se: Exploiting domain speci- ficity for improved sentiment analysis in software engineering text, Jour- nal of Systems and Software 145 (2018) 125–146
work page 2018
-
[23]
M. R. Islam, M. F. Zibran, Deva: sensing emotions in the valence arousal space in software engineering text, in: Proceedings of the 33rd annual ACM symposium on applied computing, 2018, pp. 1536–1543
work page 2018
-
[24]
M. R. Islam, M. K. Ahmmed, M. F. Zibran, Marvalous: Machine learn- ing based detection of emotions in the valence-arousal space in software engineering text, in: Proceedings of the 34th ACM/SIGAPP Sympo- sium on Applied Computing, 2019, pp. 1786–1793
work page 2019
- [25]
-
[26]
S. Cagnoni, L. Cozzini, G. Lombardo, M. Mordonini, A. Poggi, M. Tomaiuolo, Emotion-based analysis of programming languages on stack overflow, ICT Express 6 (3) (2020) 238–242. 35
work page 2020
-
[27]
G. Uddin, Y.-G. Gu´ eh´ enuc, F. Khomh, C. K. Roy, An empirical study of the effectiveness of an ensemble of stand-alone sentiment detection tools for software engineering datasets, ACM Transactions on Software Engineering and Methodology (TOSEM) 31 (3) (2022) 1–38
work page 2022
- [28]
-
[29]
J. Ding, H. Sun, X. Wang, X. Liu, Entity-level sentiment analysis of issue comments, in: Proceedings of the 3rd International Workshop on Emotion Awareness in Software Engineering, 2018, pp. 7–13
work page 2018
- [30]
-
[31]
H. Batra, N. S. Punn, S. K. Sonbhadra, S. Agarwal, Bert-based sen- timent analysis: A software engineering perspective, in: Database and Expert Systems Applications: 32nd International Conference, DEXA 2021, Virtual Event, September 27–30, 2021, Proceedings, Part I 32, Springer, 2021, pp. 138–148
work page 2021
- [32]
-
[33]
K. Sun, X. Shi, H. Gao, H. Kuang, X. Ma, G. Rong, D. Shao, Z. Zhao, H. Zhang, Incorporating pre-trained transformer models into textcnn for sentiment analysis on software engineering texts, in: Proceedings of the 13th Asia-Pacific Symposium on Internetware, 2022, pp. 127–136
work page 2022
-
[34]
M. Shafikuzzaman, M. R. Islam, A. C. Rolli, S. Akhter, N. Seliya, An empirical evaluation of the zero-shot, few-shot, and traditional fine- tuning based pretrained language models for sentiment analysis in soft- ware engineering, IEEE Access (2024)
work page 2024
-
[35]
V. R. B.-G. Caldiera, H. D. Rombach, Goal question metric paradigm, Encyclopedia of software engineering 1 (528-532) (1994) 6. 36
work page 1994
-
[36]
M. M. Imran, Y. Jain, P. Chatterjee, K. Damevski, Data augmentation for improving emotion recognition in software engineering communica- tion, in: Proceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering, 2022, pp. 1–13
work page 2022
-
[37]
C. D. Manning, P. Raghavan, H. Sch¨ utze, Introduction to information retrieval, Cambridge university press, 2008
work page 2008
-
[38]
I. H. Witten, E. Frank, M. A. Hall, C. J. Pal, M. Data, Practical ma- chine learning tools and techniques, in: Data mining, Vol. 2, Elsevier Amsterdam, The Netherlands, 2005, pp. 403–413
work page 2005
-
[39]
C. Tantithamthavorn, S. McIntosh, A. E. Hassan, K. Matsumoto, The impact of automated parameter optimization on defect prediction mod- els, IEEE Transactions on Software Engineering 45 (7) (2018) 683–711
work page 2018
-
[40]
M.-T. Puth, M. Neuh¨ auser, G. D. Ruxton, Effective use of spearman’s and kendall’s correlation coefficients for association between two mea- sured traits, Animal Behaviour 102 (2015) 77–84
work page 2015
-
[41]
M. L. McHugh, Interrater reliability: the kappa statistic, Biochemia medica 22 (3) (2012) 276–282
work page 2012
- [42]
-
[43]
Empirical standards for software engineering research,
P. Ralph, N. b. Ali, S. Baltes, D. Bianculli, J. Diaz, Y. Dittrich, N. Ernst, M. Felderer, R. Feldt, A. Filieri, et al., Empirical standards for software engineering research, arXiv preprint arXiv:2010.03525 (2020). 37
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.