CI-CBM: Class-Incremental Concept Bottleneck Model for Interpretable Continual Learning
Pith reviewed 2026-05-10 12:27 UTC · model grok-4.3
The pith
CI-CBM maintains human-interpretable concepts in class-incremental learning while matching black-box performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CI-CBM leverages effective techniques, including concept regularization and pseudo-concept generation to maintain interpretable decision processes throughout incremental learning phases. Through extensive evaluation on seven datasets, it achieves comparable performance to black-box models and outperforms previous interpretable approaches in CIL, with an average 36% accuracy gain. It provides interpretable decisions on individual inputs and understandable global decision rules, and works in both pretrained and non-pretrained scenarios.
What carries the argument
The Class-Incremental Concept Bottleneck Model (CI-CBM) with concept regularization for stability and pseudo-concept generation for handling new classes.
If this is right
- Interpretable decisions remain available for individual inputs and as global rules after learning new classes.
- Accuracy stays comparable to black-box models across multiple datasets.
- Outperforms prior interpretable methods in class-incremental learning by 36% on average.
- Applies successfully whether the model backbone starts pretrained or is trained from scratch.
Where Pith is reading between the lines
- Adapting this to other continual learning scenarios like task-incremental learning could be a natural next step.
- Stable concepts might allow users to correct model behavior by modifying specific concepts without retraining.
- Verifying the approach on even larger and more diverse datasets would strengthen the generality claim.
Load-bearing premise
That concept regularization and pseudo-concept generation preserve stable, meaningful human-interpretable concepts across incremental phases without systematic errors or task-specific tuning.
What would settle it
Observing that concepts drift into non-interpretable states or that accuracy no longer matches black-box levels after several incremental phases on the evaluated datasets would challenge the claim.
Figures





read the original abstract
Catastrophic forgetting remains a fundamental challenge in continual learning, in which models often forget previous knowledge when fine-tuned on a new task. This issue is especially pronounced in class incremental learning (CIL), which is the most challenging setting in continual learning. Existing methods to address catastrophic forgetting often sacrifice either model interpretability or accuracy. To address this challenge, we introduce ClassIncremental Concept Bottleneck Model (CI-CBM), which leverage effective techniques, including concept regularization and pseudo-concept generation to maintain interpretable decision processes throughout incremental learning phases. Through extensive evaluation on seven datasets, CI-CBM achieves comparable performance to black-box models and outperforms previous interpretable approaches in CIL, with an average 36% accuracy gain. CICBM provides interpretable decisions on individual inputs and understandable global decision rules, as shown in our experiments, thereby demonstrating that human understandable concepts can be maintained during incremental learning without compromising model performance. Our approach is effective in both pretrained and non-pretrained scenarios; in the latter, the backbone is trained from scratch during the first learning phase. Code is publicly available at github.com/importAmir/CI-CBM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Class-Incremental Concept Bottleneck Model (CI-CBM) to address catastrophic forgetting in class-incremental learning (CIL) while preserving interpretability. It combines concept regularization and pseudo-concept generation with concept bottleneck models, claiming that on seven datasets the approach achieves accuracy comparable to black-box models and an average 36% gain over prior interpretable CIL methods. The paper states that CI-CBM supports both instance-level interpretable decisions and global decision rules, works in pretrained and from-scratch settings, and releases code publicly.
Significance. If the claims regarding stable, human-interpretable concepts hold, the work would meaningfully advance interpretable continual learning by showing that interpretability need not be traded off against accuracy in the challenging CIL setting. The public code release is a clear strength that supports reproducibility.
major comments (2)
- [Abstract] Abstract: the central performance claim of an 'average 36% accuracy gain' over previous interpretable approaches is presented without naming the baselines, reporting per-dataset accuracies, error bars, or statistical tests. This makes it impossible to assess whether the gain is robust or driven by particular dataset characteristics.
- [Experiments] Experiments (as referenced in the abstract): no quantitative metrics for concept quality, stability, or interpretability across incremental phases (e.g., concept alignment scores, phase-to-phase consistency of global rules, or human ratings) are described, nor are ablations on regularization strength or pseudo-concept generation. Because the distinguishing contribution is the preservation of meaningful concepts rather than accuracy alone, this omission is load-bearing for the interpretability claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps clarify the presentation of our results and strengthen the evaluation of interpretability. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claim of an 'average 36% accuracy gain' over previous interpretable approaches is presented without naming the baselines, reporting per-dataset accuracies, error bars, or statistical tests. This makes it impossible to assess whether the gain is robust or driven by particular dataset characteristics.
Authors: We agree that the abstract would benefit from additional context on the performance claim. The detailed results—including the specific prior interpretable CIL baselines, per-dataset accuracies, error bars from multiple runs, and statistical comparisons—are fully reported in the Experiments section with tables and figures. In the revised manuscript we will update the abstract to name the primary baselines and explicitly note that the 36% average gain is computed from per-dataset results with error bars. revision: yes
-
Referee: [Experiments] Experiments (as referenced in the abstract): no quantitative metrics for concept quality, stability, or interpretability across incremental phases (e.g., concept alignment scores, phase-to-phase consistency of global rules, or human ratings) are described, nor are ablations on regularization strength or pseudo-concept generation. Because the distinguishing contribution is the preservation of meaningful concepts rather than accuracy alone, this omission is load-bearing for the interpretability claim.
Authors: We acknowledge that quantitative metrics would provide stronger, more direct support for the claim of preserved concept quality. Our current experiments demonstrate interpretability via explicit instance-level concept attributions and global decision rules that remain consistent across phases, with accuracy comparable to black-box models serving as supporting evidence of concept stability. We did not originally include concept alignment scores, phase-to-phase consistency metrics, human ratings, or component ablations. We will add ablations on regularization strength and pseudo-concept generation, plus quantitative measures of concept consistency (e.g., overlap of active concepts across phases), to the revised manuscript. revision: yes
Circularity Check
No circularity: empirical method with independent algorithmic components and external validation
full rationale
The paper presents CI-CBM as a new algorithmic approach combining concept regularization and pseudo-concept generation for class-incremental learning. Its central claims rest on empirical results across seven datasets, including accuracy comparisons to black-box and prior interpretable baselines. No equations are provided that define a quantity in terms of itself or rename a fitted parameter as a prediction. No self-citations are invoked to justify uniqueness theorems or load-bearing assumptions. The derivation chain consists of stated techniques plus experimental measurements that can be independently reproduced or falsified, satisfying the criteria for a self-contained, non-circular contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Length filter: Remove concepts longer than 30 characters
-
[2]
Class similarity filter: Remove concepts with cosine similarityą0.85to any class name, using Sentence-Transformer and CLIP text embeddings
-
[3]
This filtered set is then used to update the concept set
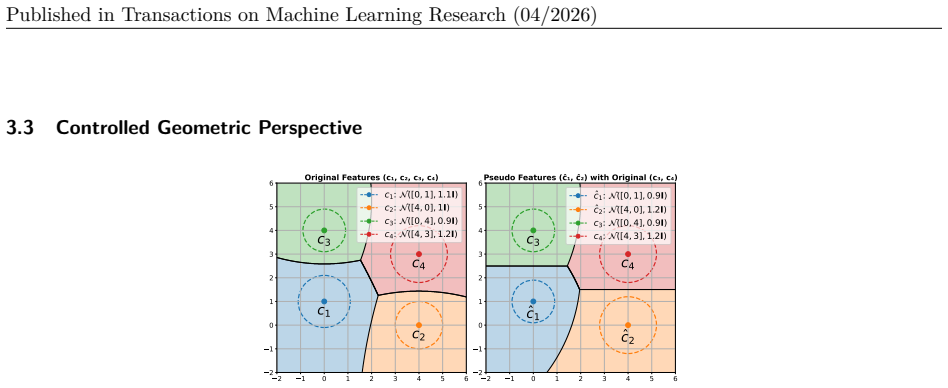
Redundancy filter: Remove near-duplicate concepts with cosine similarityą0.9to any earlier concept in the set. This filtered set is then used to update the concept set. All steps are automated and applied incrementally for each new phase. The full pipeline is implemented in the released codebase. A12 Impact of Distillation Regularizer Weight on Accuracy. ...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.