Exploring LLM-based Verilog Code Generation with Data-Efficient Fine-Tuning and Testbench Automation
Pith reviewed 2026-05-10 09:23 UTC · model grok-4.3
The pith
Automating testbench creation with multi-agent models lets fine-tuned LLMs match state-of-the-art Verilog generation performance while using less training data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
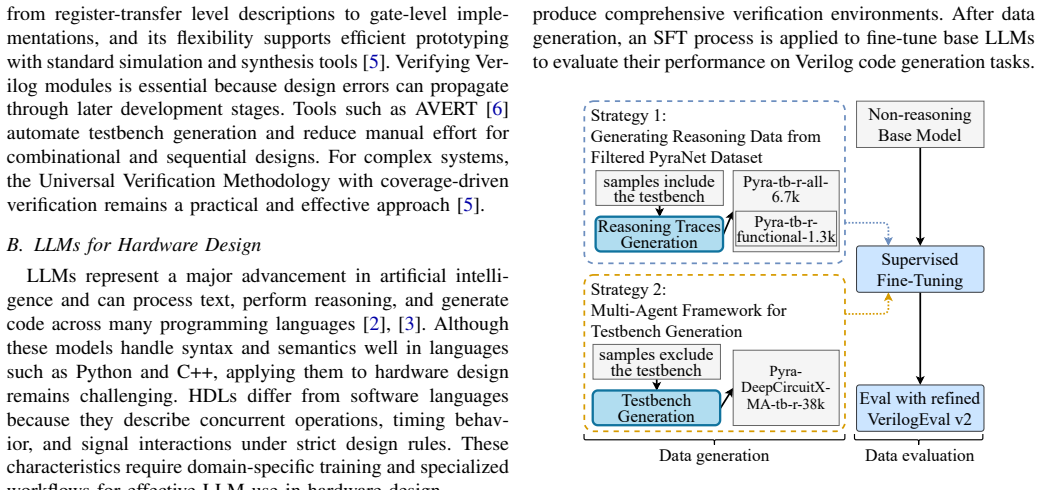
By using multi-agent models to automate testbench generation, the workflow produces effective fine-tuning data for the specification-to-Verilog task. The fine-tuned model then achieves performance comparable to state-of-the-art methods on the refined VerilogEval v2 benchmark while using less training data. The study therefore supplies a practical basis for future LLM-based HDL generation and automated verification.
What carries the argument
Multi-agent LLM workflow that generates testbenches to create data-efficient fine-tuning sets for specification-to-Verilog models.
Load-bearing premise
The multi-agent models must reliably produce high-quality, correct, and unbiased testbenches that do not introduce errors or coverage gaps into the fine-tuning data.
What would settle it
An evaluation in which the model fine-tuned on the automatically generated testbenches shows clearly lower accuracy on the VerilogEval v2 benchmark than state-of-the-art models trained on larger human-curated datasets, or manual inspection reveals systematic flaws in the generated testbenches.
Figures


read the original abstract
Recent advances in large language models have improved code generation, but their use in hardware description languages is still limited. Moreover, training data and testbenches for these models are often scarce. This paper presents a workflow that uses multi-agent models to generate testbenches for high-quality fine-tuning data. By automating testbench creation, the fine-tuned model for the specification-to-Verilog task achieves performance comparable to state-of-the-art methods on the refined VerilogEval v2 benchmark while using less training data. This study provides a basis for future work on LLM-based HDL generation and automated verification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a workflow using multi-agent LLMs to automatically generate testbenches, creating data for fine-tuning models on specification-to-Verilog generation. It claims this data-efficient approach yields performance comparable to state-of-the-art methods on the refined VerilogEval v2 benchmark while using less training data.
Significance. If the central claims hold with proper validation, the work would be significant for enabling more accessible LLM-based HDL design by mitigating data scarcity through automated testbench creation, with potential impact on hardware verification automation.
major comments (2)
- [Abstract] Abstract: The headline claim of 'achieves performance comparable to state-of-the-art methods on the refined VerilogEval v2 benchmark while using less training data' is presented without any quantitative metrics, tables, ablation results, or error analysis, which is load-bearing for assessing whether the data-efficient fine-tuning actually succeeds.
- [Workflow / Testbench Generation] Testbench automation section (implied in workflow description): The multi-agent testbench generation is asserted to produce 'high-quality' fine-tuning data, but no validation metrics (e.g., functional pass rates vs. golden references, stimulus coverage percentages, or bias analysis) are reported; this directly affects whether the downstream performance comparison can be trusted.
minor comments (1)
- [Abstract] The phrase 'refined VerilogEval v2' is used without a citation or definition of what refinements were applied, reducing clarity for readers unfamiliar with the benchmark.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights opportunities to better substantiate our claims. We address each major comment below and will incorporate revisions to strengthen the manuscript's clarity and evidential support.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim of 'achieves performance comparable to state-of-the-art methods on the refined VerilogEval v2 benchmark while using less training data' is presented without any quantitative metrics, tables, ablation results, or error analysis, which is load-bearing for assessing whether the data-efficient fine-tuning actually succeeds.
Authors: We agree that the abstract would be strengthened by including quantitative metrics to support the headline claim. In the revised manuscript, we will update the abstract to report specific results from our experiments, including the pass rates (e.g., pass@1 and pass@5) achieved by the fine-tuned model on VerilogEval v2 relative to state-of-the-art baselines, as well as the exact reduction in training data volume. We will also reference the relevant tables and ablation studies from the results section to provide immediate context for readers. revision: yes
-
Referee: [Workflow / Testbench Generation] Testbench automation section (implied in workflow description): The multi-agent testbench generation is asserted to produce 'high-quality' fine-tuning data, but no validation metrics (e.g., functional pass rates vs. golden references, stimulus coverage percentages, or bias analysis) are reported; this directly affects whether the downstream performance comparison can be trusted.
Authors: The referee correctly notes that direct validation metrics for the generated testbenches are not explicitly reported, which limits assessment of data quality. While the downstream performance gains on VerilogEval v2 provide indirect evidence of utility, we will add a dedicated subsection in the revised workflow description. This will include quantitative validation such as the functional pass rate of generated testbenches against golden references, stimulus coverage percentages, and a brief bias analysis of the produced data. These additions will be supported by new tables or figures as appropriate. revision: yes
Circularity Check
No significant circularity; claims rest on external benchmark comparison
full rationale
The paper describes a workflow that generates testbenches via multi-agent LLMs, uses them to create fine-tuning data, trains a model for spec-to-Verilog, and reports performance on the public VerilogEval v2 benchmark against external SOTA methods. No step reduces by construction to its own inputs: the benchmark results are measured outcomes on held-out external data rather than fitted parameters renamed as predictions, and no load-bearing premise relies on self-citation chains or self-defined uniqueness theorems. The derivation chain (data generation → fine-tuning → external eval) is independent of the reported numbers and does not exhibit self-definitional, fitted-input, or ansatz-smuggling patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Automated test case generation for digital system designs: A mapping study on vhdl, verilog, and systemverilog description languages,
A. A. Vivekananda and E. Enoiu, “Automated test case generation for digital system designs: A mapping study on vhdl, verilog, and systemverilog description languages,”Designs, vol. 4, no. 3, 2020
2020
-
[2]
Language models are few-shot learners,
T. B. Brown, B. Mann, N. Ryderet al., “Language models are few-shot learners,” inProceedings of the 34th International Conference on Neural Information Processing Systems (NIPS). Red Hook, NY , USA: Curran Associates Inc., 2020
2020
-
[3]
GPT-4 technical report,
OpenAI, J. Achiam, S. Adler, S. Agarwalet al., “GPT-4 technical report,” 2024
2024
-
[4]
DeepSeek-R1 incentivizes reasoning in llms through reinforcement learning,
D. Guo, D. Yang, H. Zhanget al., “DeepSeek-R1 incentivizes reasoning in llms through reinforcement learning,”Nature, vol. 645, no. 8081, pp. 633–638, 9 2025
2025
-
[5]
A universal-verification- methodology-based testbench for the coverage-driven functional veri- fication of an instruction cache controller,
C. Liu, X. Xu, Z. Chen, and B. Wang, “A universal-verification- methodology-based testbench for the coverage-driven functional veri- fication of an instruction cache controller,”Electronics, no. 18, 2023
2023
-
[6]
A VERT: An automatic verilog testbench generation tool for grammatical evolution,
J. McEllin, R. Conway, and C. Ryan, “A VERT: An automatic verilog testbench generation tool for grammatical evolution,” in2022 33rd Irish Signals and Systems Conference (ISSC), 2022, pp. 1–8
2022
-
[7]
Insights from verification: Training a verilog generation llm with reinforcement learning with testbench feedback,
N. Wang, B. Yao, J. Zhou, Y . Hu, X. Wang, N. Guan, and Z. Jiang, “Insights from verification: Training a verilog generation llm with reinforcement learning with testbench feedback,” 2025
2025
-
[8]
VeriReason: Reinforce- ment learning with testbench feedback for reasoning-enhanced verilog generation,
Y . Wang, G. Sun, W. Ye, G. Qu, and A. Li, “VeriReason: Reinforce- ment learning with testbench feedback for reasoning-enhanced verilog generation,” 2025
2025
-
[9]
QiMeng-CodeV-R1: Reasoning-enhanced verilog generation,
Y . Zhu, D. Huang, H. Lyu, X. Zhang, C. Li, W. Shi, Y . Wu, J. Mu, J. Wang, Y . Zhao, P. Jin, S. Cheng, S. Liang, X. Zhang, R. Zhang, Z. Du, Q. Guo, X. Hu, and Y . Chen, “QiMeng-CodeV-R1: Reasoning-enhanced verilog generation,” inProceedings of the 39th Annual Conference on Neural Information Processing Systems (NeurIPS), 2025
2025
-
[10]
DAPO: An open-source llm reinforce- ment learning system at scale,
Q. Yu, Z. Zhang, R. Zhuet al., “DAPO: An open-source llm reinforce- ment learning system at scale,” 2025
2025
-
[11]
PyraNet: A multi-layered hierarchical dataset for verilog,
B. Nadimi, G. O. Boutaib, and H. Zheng, “PyraNet: A multi-layered hierarchical dataset for verilog,” in2025 62nd ACM/IEEE Design Automation Conference (DAC). IEEE, Jun. 2025, pp. 1–7
2025
-
[12]
DeepCircuitX: A comprehensive repository-level dataset for rtl code understanding, generation, and ppa analysis,
Z. Li, C. Xu, Z. Shi, Z. Peng, Y . Liu, Y . Zhou, L. Zhou, C. Ma, J. Zhong, X. Wang, J. Zhao, Z. Chu, X. Yang, and Q. Xu, “DeepCircuitX: A comprehensive repository-level dataset for rtl code understanding, generation, and ppa analysis,” in2025 IEEE International Conference on LLM-Aided Design (ICLAD), 2025, pp. 204–211
2025
-
[13]
Qwen2.5-Coder technical report,
B. Hui, J. Yang, Z. Cuiet al., “Qwen2.5-Coder technical report,” 2024
2024
-
[14]
Revisiting VerilogEval: A year of improvements in large-language models for hardware code generation,
N. Pinckney, C. Batten, M. Liu, H. Ren, and B. Khailany, “Revisiting VerilogEval: A year of improvements in large-language models for hardware code generation,” 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.