CSLE: A Reinforcement Learning Platform for Autonomous Security Management
Pith reviewed 2026-05-10 10:17 UTC · model grok-4.3
The pith
CSLE combines emulation of real networks with simulation to train reinforcement learning agents that deliver near-optimal security management under conditions close to live operations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
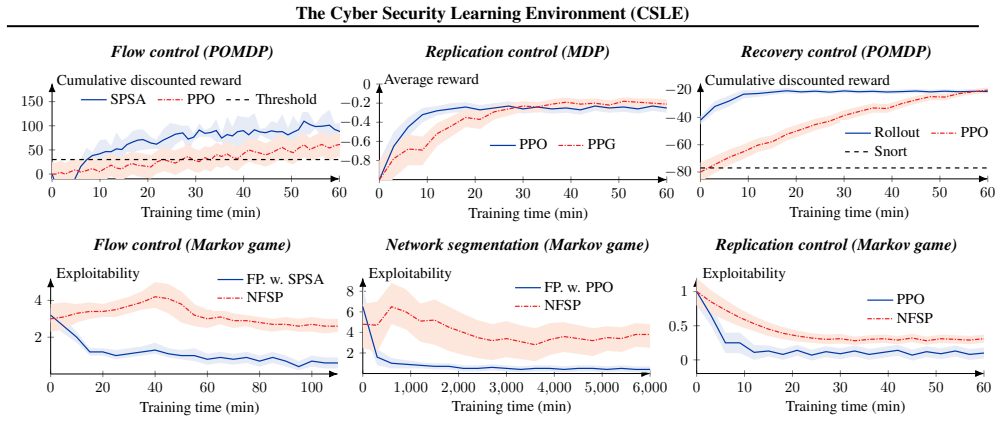
CSLE consists of an emulation system that replicates key components of the target networked system in a virtualized environment to gather measurements, identify a system model such as a Markov decision process, and a simulation system where security strategies are learned efficiently through simulations of the model. Learned strategies are then evaluated and refined in the emulation system. Through four use cases in flow control, replication control, segmentation control, and recovery control, CSLE enables near-optimal security management in an environment that approximates an operational system.
What carries the argument
The dual emulation-simulation architecture that identifies a system model from virtualized measurements and then learns and refines reinforcement learning strategies iteratively between simulation and emulation.
If this is right
- Security policies for networked systems can be developed and validated without direct risk to live production environments.
- Reinforcement learning becomes practical for adaptive controls such as traffic flow, data replication, network segmentation, and system recovery.
- The gap between theoretical reinforcement learning performance and real-world security outcomes can be narrowed through iterative refinement in emulation.
- Multiple distinct security control tasks can be addressed within the same platform using the same core workflow.
Where Pith is reading between the lines
- The platform could reduce the cost and time needed to test new security policies by limiting live-system exposure to only the final validation stage.
- Accurate emulation of network dynamics appears central to successful transfer of reinforcement learning policies in security settings.
- Similar dual-system designs might apply to other reinforcement learning domains where direct interaction with the real environment is costly or risky.
Load-bearing premise
The emulation system accurately replicates the behavior and dynamics of the target operational system so that strategies learned in simulation transfer without large performance loss.
What would settle it
Deploy the strategies learned through CSLE on a live operational networked system and measure whether their security performance matches the near-optimal results obtained inside the emulation environment or drops substantially.
Figures
















read the original abstract
Reinforcement learning is a promising approach to autonomous and adaptive security management in networked systems. However, current reinforcement learning solutions for security management are mostly limited to simulation environments and it is unclear how they generalize to operational systems. In this paper, we address this limitation by presenting CSLE: a reinforcement learning platform for autonomous security management that enables experimentation under realistic conditions. Conceptually, CSLE encompasses two systems. First, it includes an emulation system that replicates key components of the target system in a virtualized environment. We use this system to gather measurements and logs, based on which we identify a system model, such as a Markov decision process. Second, it includes a simulation system where security strategies are efficiently learned through simulations of the system model. The learned strategies are then evaluated and refined in the emulation system to close the gap between theoretical and operational performance. We demonstrate CSLE through four use cases: flow control, replication control, segmentation control, and recovery control. Through these use cases, we show that CSLE enables near-optimal security management in an environment that approximates an operational system.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents CSLE, a reinforcement learning platform for autonomous security management consisting of an emulation system that replicates key components of a target networked system to collect measurements and identify a model such as an MDP, paired with a simulation system for efficient strategy learning; learned strategies are then evaluated and refined in the emulation environment. The platform is illustrated through four use cases (flow control, replication control, segmentation control, and recovery control), with the central claim that CSLE enables near-optimal security management in an environment that approximates an operational system.
Significance. If the emulation accurately replicates operational dynamics and policies transfer with minimal performance loss, the platform could meaningfully advance practical RL applications in security by providing a structured way to move beyond pure simulation. The dual emulation-simulation design and concrete use cases offer a reusable experimental framework that addresses a recognized sim-to-real gap in the field.
major comments (2)
- [Abstract] Abstract: the claim that the use cases demonstrate 'near-optimal security management' is unsupported by any quantitative results, performance metrics, error bars, or baseline comparisons, rendering it impossible to verify whether the central claim holds.
- [Use cases] Use cases section: no side-by-side empirical benchmarking is reported comparing any metric (e.g., latency distributions, attack success rates, or resource usage) between the emulated environment and an actual production or testbed instance of the same network; this validation is load-bearing for the assertion that strategies learned in simulation transfer to approximate operational performance.
minor comments (2)
- [Architecture] The description of how the MDP is identified from emulation logs could be expanded with a concrete example or pseudocode to improve reproducibility.
- [Use cases] Clarify the specific RL algorithms and reward functions employed in each use case, as these details are essential for assessing the 'near-optimal' characterization.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below, indicating where revisions will be made to improve clarity and accuracy.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the use cases demonstrate 'near-optimal security management' is unsupported by any quantitative results, performance metrics, error bars, or baseline comparisons, rendering it impossible to verify whether the central claim holds.
Authors: We agree that the abstract's use of 'near-optimal' is not supported by summarized quantitative evidence and should be revised. The use cases section reports concrete performance metrics (e.g., attack mitigation rates and resource consumption) for policies transferred from simulation to emulation, along with comparisons against static baselines, but these details are not referenced in the abstract and no error bars or formal optimality analysis appear. We will revise the abstract to state that the use cases demonstrate effective security management strategies learned and validated in the emulation environment, removing the unsubstantiated 'near-optimal' phrasing. This change will be made in the next version. revision: yes
-
Referee: [Use cases] Use cases section: no side-by-side empirical benchmarking is reported comparing any metric (e.g., latency distributions, attack success rates, or resource usage) between the emulated environment and an actual production or testbed instance of the same network; this validation is load-bearing for the assertion that strategies learned in simulation transfer to approximate operational performance.
Authors: We acknowledge that the manuscript does not include direct side-by-side benchmarking against a live production or external testbed instance. The emulation system is constructed from measurements collected on real networked systems to replicate key components and dynamics, and the use cases demonstrate that simulation-learned strategies transfer to this emulated setting with limited performance loss. However, we recognize that this does not constitute full validation on an operational network. We will add an explicit limitations paragraph in the discussion section noting the reliance on emulation as a proxy and outlining future work on testbed validation. This addresses the concern without altering the core platform description. revision: partial
Circularity Check
No circularity detected in platform description or use-case demonstrations
full rationale
The paper presents CSLE as an experimental platform with an emulation system for data collection and MDP identification, followed by simulation-based RL training and refinement in emulation. No mathematical derivations, equations, or first-principles predictions are claimed that reduce to inputs by construction. The use cases (flow control, replication control, etc.) are internal demonstrations of the platform's operation rather than fitted predictions or self-referential results. The approximation to operational systems is stated as a design goal without self-citation load-bearing or ansatz smuggling. The derivation chain is therefore self-contained as a tool description, with no steps matching the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Emulation of key system components produces logs and measurements representative of the target operational environment.
- domain assumption A Markov decision process extracted from emulation logs is an adequate model for learning security strategies that transfer back to the emulation.
Reference graph
Works this paper leans on
-
[1]
Digital Twin Summit. Anderson, H. S., Kharkar, A., Filar, B., Evans, D., and Roth, P. Learning to evade static PE machine learning malware models via reinforcement learning, 2018. URL https://arxiv.org/abs/1801.08917. Andrew, A., Spillard, S., Collyer, J., and Dhir, N. De- veloping optimal causal cyber-defence agents via cyber security simulation. InProce...
-
[2]
Activity analysis of production and allocation. Carrasco, J. A. F., Pagola, I. A., Urrutia, R. O., and Ro- man, R. CYBERSHIELD: A competitive simulation environment for training AI in cybersecurity. In2024 11th International Conference on Internet of Things: Sys- tems, Management and Security (IOTSMS), pp. 11–18,
-
[3]
doi: 10.1109/IOTSMS62296.2024.10710208. Chen, Y ., Shetty, M., Somashekar, G., Ma, M., Simmhan, Y ., Mace, J., Bansal, C., Wang, R., and Rajmohan, S. AIOpsLab: a holistic framework to evaluate AI agents for enabling autonomous clouds. https://mlsys.org/ virtual/2025/poster/3285, 2025. MLSys 2025 Poster. Clemm, A. and Cisco Systems, I.Network Management Fu...
-
[4]
Proximal Policy Optimization Algorithms
USENIX Association. Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algo- rithms. 2017. URL http://arxiv.org/abs/ 1707.06347. Schwartz, J., Kurniawati, H., and El-Mahassni, E. POMDP + information-decay: Incorporating defender’s behaviour in autonomous penetration testing.Pro- ceedings of the International C...
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[5]
CSLE: A Reinforcement Learning Platform for Au- tonomous Security Management
URL https://ojs.aaai.org/index. php/ICAPS/article/view/6666. Song, W., Li, X., Afroz, S., Garg, D., Kuznetsov, D., and Yin, H. MAB-Malware: A reinforcement learning frame- work for blackbox generation of adversarial malware. InProceedings of the 2022 ACM on Asia Conference on Computer and Communications Security, ASIA CCS ’22, pp. 990–1003, New York, NY ,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.