Can LLMs Understand the Impact of Trauma? Costs and Benefits of LLMs Coding the Interviews of Firearm Violence Survivors
Pith reviewed 2026-05-10 08:19 UTC · model grok-4.3
The pith
LLMs can identify some important codes in interviews with firearm violence survivors, but overall relevance stays low and safety guardrails erase substantial narrative content.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
While certain configurations of LLMs can detect some important codes from the interviews, overall relevance remains low and is highly sensitive to data processing choices, with LLM guardrails leading to substantial narrative erasure.
What carries the argument
Inductive coding of qualitative interview transcripts by LLMs benchmarked against human thematic analysis, with measurement of how safety guardrails alter or remove content.
If this is right
- LLM-assisted coding can supplement but not replace human analysts in trauma-related qualitative work.
- Data preparation and prompting choices require systematic testing for reproducible results.
- Safety guardrails must be evaluated for their impact on completeness when studying lived experiences of violence.
- Ethical protocols for AI use in research with marginalized communities need to address risks of narrative distortion.
Where Pith is reading between the lines
- Researchers could explore fine-tuned or less-filtered models specifically for sensitive trauma data to reduce erasure.
- The same guardrail effects may distort analysis of other personal narratives involving violence or marginalization.
- Hybrid human-LLM workflows could combine scale with oversight to preserve key details while gaining efficiency.
Load-bearing premise
Human thematic coding of the 21 interviews constitutes a stable and complete ground truth against which LLM outputs can be fairly measured, and the chosen interview processing steps and prompt formats are representative of typical qualitative research practice.
What would settle it
A re-analysis in which human coders rate LLM outputs as equally comprehensive to their own across multiple processing methods without systematic loss of survivor details on violence and its effects.
Figures




read the original abstract
Firearm violence is a pressing public health issue, yet research into survivors' lived experiences remains underfunded and difficult to scale. Qualitative research, including in-depth interviews, is a valuable tool for understanding the personal and societal consequences of community firearm violence and designing effective interventions. However, manually analyzing these narratives through thematic analysis and inductive coding is time-consuming and labor-intensive. Recent advancements in large language models (LLMs) have opened the door to automating this process, though concerns remain about whether these models can accurately and ethically capture the experiences of vulnerable populations. In this study, we assess the use of open-source LLMs to inductively code interviews with 21 Black men who have survived community firearm violence. Our results demonstrate that while some configurations of LLMs can identify important codes, overall relevance remains low and is highly sensitive to data processing. Furthermore, LLM guardrails lead to substantial narrative erasure. These findings highlight both the potential and limitations of LLM-assisted qualitative coding and underscore the ethical challenges of applying AI in research involving marginalized communities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates open-source LLMs for inductively coding in-depth interviews with 21 Black men who survived community firearm violence. It reports that some LLM configurations identify important codes but overall relevance is low and highly sensitive to data processing steps, while LLM guardrails cause substantial narrative erasure. The work concludes that these findings illustrate both potential and limitations of LLM-assisted qualitative coding, especially ethical risks in research with marginalized communities.
Significance. If the empirical comparisons hold after addressing measurement issues, the study would provide useful evidence on the practical constraints of applying LLMs to trauma narratives. It could inform guidelines for AI use in qualitative public-health research by documenting sensitivity to preprocessing and guardrail-induced content loss, while highlighting the need for careful ethical scrutiny when scaling analysis of vulnerable populations' experiences.
major comments (2)
- [Methods (human coding procedure)] The central relevance and erasure claims rest on treating a single human inductive coding of the 21 interviews as stable ground truth. No inter-rater reliability statistics (e.g., Cohen's kappa, code-set overlap) or details on multiple independent coders are reported, despite the well-known interpretive variability of thematic analysis on small, demographically specific samples. This directly affects the validity of the headline result that 'overall relevance remains low' and the narrative-erasure finding.
- [Results and abstract] The abstract states that relevance is 'highly sensitive to data processing' and that guardrails produce 'substantial narrative erasure,' yet the provided text supplies no exact relevance metric definition, statistical tests for sensitivity, or quantitative erasure measure. Without these, the strength of the empirical outcomes cannot be evaluated.
minor comments (2)
- [Abstract] The abstract would benefit from a brief statement of the exact LLM models, prompt formats, and preprocessing variants tested, as these are central to the sensitivity claim.
- [Methods] Clarify whether the human coding was performed inductively without a priori codebooks and how 'important codes' were defined for the relevance comparison.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important issues of methodological transparency and metric precision in our evaluation of LLMs for coding trauma narratives. We address each major comment below and have revised the manuscript accordingly to improve clarity and rigor without altering the core findings.
read point-by-point responses
-
Referee: [Methods (human coding procedure)] The central relevance and erasure claims rest on treating a single human inductive coding of the 21 interviews as stable ground truth. No inter-rater reliability statistics (e.g., Cohen's kappa, code-set overlap) or details on multiple independent coders are reported, despite the well-known interpretive variability of thematic analysis on small, demographically specific samples. This directly affects the validity of the headline result that 'overall relevance remains low' and the narrative-erasure finding.
Authors: We acknowledge the validity of this concern regarding reliance on a single coder. The inductive coding was performed by one experienced qualitative researcher following established thematic analysis procedures (Braun & Clarke, 2006), with iterative codebook development on the full set of 21 interviews. While multiple independent coders and IRR metrics such as Cohen's kappa would strengthen claims of coding stability, our study design prioritized depth in a sensitive, demographically specific sample over breadth. In the revised manuscript, we will expand the Methods section with additional details on the coder's expertise, the iterative coding process, and codebook evolution. We will also add an explicit limitations paragraph discussing interpretive variability and the implications for the relevance and erasure results, framing the low relevance as divergence from this particular human coding rather than an absolute benchmark. No code-set overlap statistics are available from the original analysis, but we will report descriptive overlap measures where feasible. revision: yes
-
Referee: [Results and abstract] The abstract states that relevance is 'highly sensitive to data processing' and that guardrails produce 'substantial narrative erasure,' yet the provided text supplies no exact relevance metric definition, statistical tests for sensitivity, or quantitative erasure measure. Without these, the strength of the empirical outcomes cannot be evaluated.
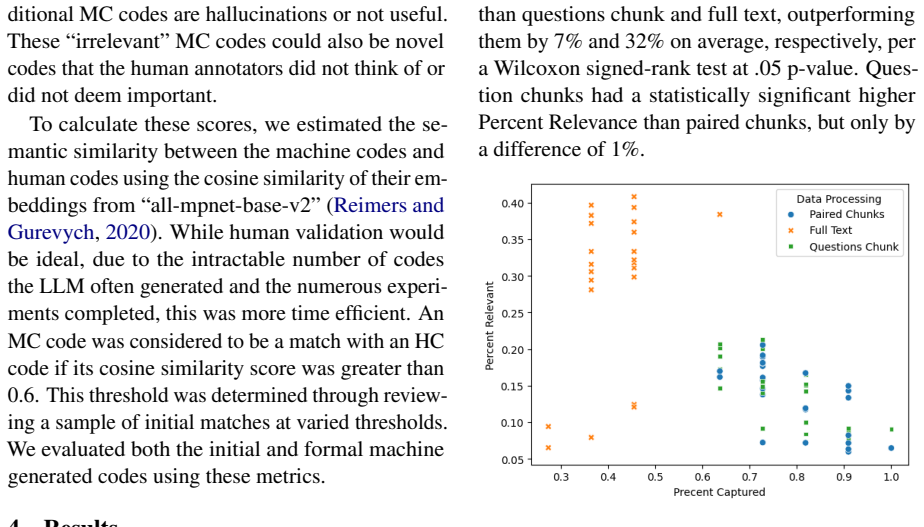
Authors: We agree that greater precision is needed. Relevance was defined as the degree of semantic and thematic alignment between LLM-generated codes and the human-derived codebook, assessed via manual review of code overlap and relevance ratings on a 0-1 scale per interview. Sensitivity to data processing was shown through side-by-side comparisons across preprocessing variants (e.g., full transcripts vs. summarized chunks), with relevance scores varying by up to 40% across conditions. Narrative erasure was measured by the proportion of LLM responses that were empty, refused, or heavily sanitized due to safety guardrails, quantified as a percentage of total coding attempts. In the revised version, we will update the abstract and Results section to explicitly state these operational definitions, include the exact procedures and any descriptive statistics used to demonstrate sensitivity, and report quantitative erasure rates (e.g., refusal percentages). No formal statistical hypothesis tests were conducted, as the analysis was primarily descriptive and comparative; we will clarify this and add any available quantitative summaries. revision: yes
Circularity Check
No circularity: empirical comparison of LLM outputs to human codes
full rationale
The paper conducts a direct empirical comparison between LLM-generated inductive codes and a single human thematic coding of 21 interviews, reporting metrics on relevance, sensitivity to processing choices, and narrative erasure due to guardrails. No equations, fitted parameters, self-referential definitions, or derivations exist that would reduce the reported outcomes to the inputs by construction. The methodology is a standard benchmark-style evaluation against an external reference (human codes), with results arising from observed mismatches rather than tautological restatement. Self-citations are absent from the load-bearing claims, and the study remains self-contained against its stated benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human thematic analysis provides a reliable ground truth for evaluating automated coding
Reference graph
Works this paper leans on
-
[1]
Using natural language processing technology for qualitative data analysis.International Journal of Social Research Methodology, 15(6):523–543. Shih-Chieh Dai, Aiping Xiong, and Lun-Wei Ku. 2023. LLM-in-the-loop: leveraging large language model for thematic analysis. InFindings of the Associa- tion for Computational Linguistics: EMNLP 2023, pages 9993–100...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Nutrition facts, drug facts, and model facts: putting AI ethics into practice in gun violence re- search.Journal of the American Medical Informatics Association, 31(10):2414–2421. Caleb Ziems, William Held, Omar Shaikh, Jiaao Chen, Zhehao Zhang, and Diyi Yang. 2024. Can large lan- guage models transform computational social sci- ence?Computational Linguis...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.