Recognition: unknown
Training Language Models for Bilateral Trade with Private Information
Pith reviewed 2026-05-10 17:10 UTC · model grok-4.3
The pith
Language models learn to discriminate prices in bilateral bargaining by anchoring high and conceding gradually over sequential offers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
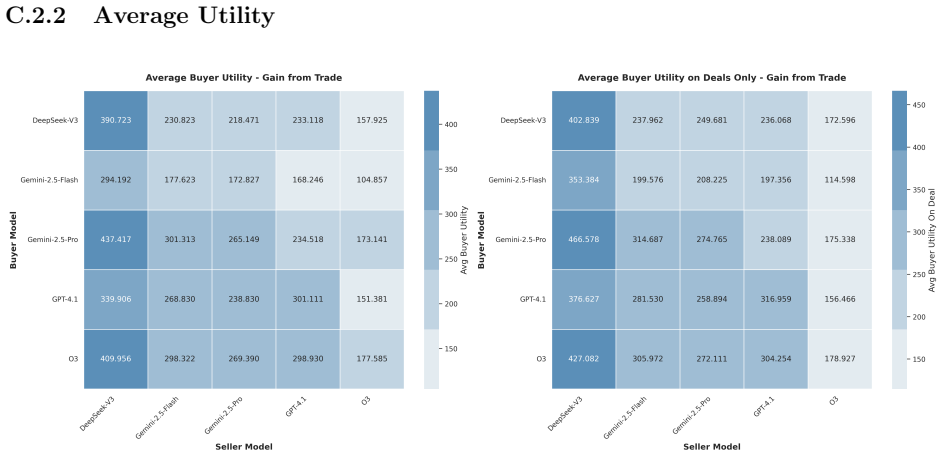
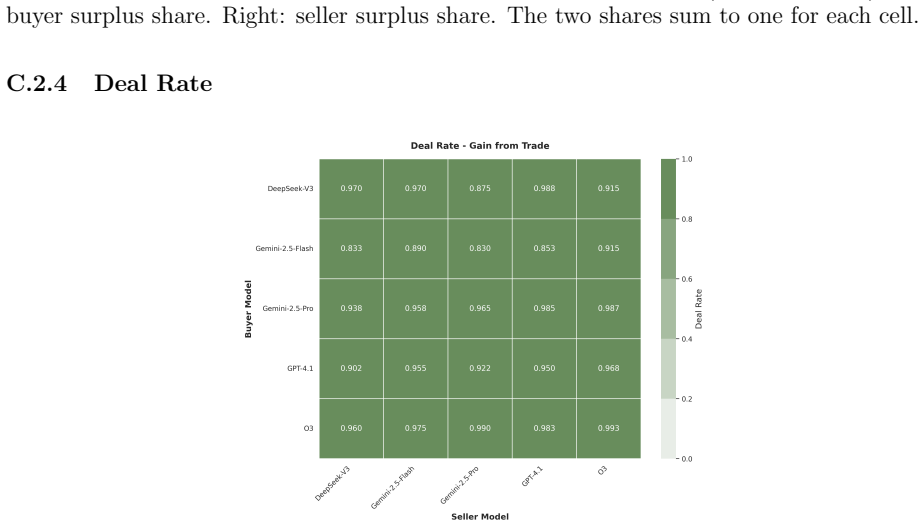
Effective LLM bargaining agents implement price discrimination through sequential offers; stronger models scale their behavior proportionally to item value and maintain performance across price tiers. Supervised fine-tuning approximately doubles surplus share but reduces deal rates, while subsequent reinforcement learning recovers deal rates at the expense of some surplus gains. The fine-tuning also compresses surplus variation across price tiers and generalizes this proportional behavior to unseen opponents.
What carries the argument
The event-driven simulator that separates binding price offers from natural-language messages, allowing automated scoring of surplus, deal completion, and strategy patterns in private-information bilateral trade.
If this is right
- Stronger models maintain high surplus capture across all value levels by scaling offers proportionally to the item.
- Quickly accommodating strategies in the buyer role prevent price discrimination and produce the lowest surplus and deal rates.
- Supervised fine-tuning produces proportional strategies that transfer to bargaining opponents not encountered in training.
- The reward structure in reinforcement learning directly trades off higher surplus extraction against higher deal completion rates.
Where Pith is reading between the lines
- Similar training pipelines could be applied to train LLM agents for other private-information settings such as auctions or contract negotiations.
- Reward functions that explicitly penalize both low surplus and failed deals might allow models to retain more of the surplus gains from fine-tuning.
- The observed link between temporal patience and higher surplus suggests testing whether adding explicit time costs in the simulator would sharpen the learned strategies further.
- If the proportional scaling behavior generalizes, the same models might serve as starting points for multi-party or repeated-trade environments.
Load-bearing premise
The simulator's separation of binding offers from chat messages accurately reflects the core strategic dynamics of real bilateral bargaining under private information.
What would settle it
Running the trained Qwen models against human bargainers or in a protocol without the simulator's clean separation of offers and messages and finding that surplus shares do not double or that generalization to new opponents disappears would falsify the training claims.
Figures


























read the original abstract
Bilateral bargaining under incomplete information provides a controlled testbed for evaluating large language model (LLM) agent capabilities. Bilateral trade demands individual rationality, strategic surplus maximization, and cooperation to realize gains from trade. We develop a structured bargaining environment where LLMs negotiate via tool calls within an event-driven simulator, separating binding offers from natural-language messages to enable automated evaluation. The environment serves two purposes: as a benchmark for frontier models and as a training environment for open-weight models via reinforcement learning. In benchmark experiments, a round-robin tournament among five frontier models (15,000 negotiations) reveals that effective strategies implement price discrimination through sequential offers. Aggressive anchoring, calibrated concession, and temporal patience correlate with the highest surplus share and deal rate. Accommodating strategies that concede quickly disable price discrimination in the buyer role, yielding the lowest surplus capture and deal completion. Stronger models scale their behavior proportionally to item value, maintaining performance across price tiers; weaker models perform well only when wide zones of possible agreement offset suboptimal strategies. In training experiments, we fine-tune Qwen3 (8B, 14B) via supervised fine-tuning (SFT) followed by Group Relative Policy Optimization (GRPO) against a fixed frontier opponent. These stages optimize competing objectives: SFT approximately doubles surplus share but reduces deal rates, while RL recovers deal rates but erodes surplus gains, reflecting the reward structure. SFT also compresses surplus variation across price tiers, which generalizes to unseen opponents, suggesting that behavioral cloning instills proportional strategies rather than memorized price points.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces an event-driven simulator for bilateral bargaining under private information in which LLMs negotiate via tool calls, separating binding offers from natural-language messages. Through a round-robin tournament of five frontier models across 15,000 negotiations, it reports that effective strategies implement price discrimination via sequential offers, with aggressive anchoring, calibrated concession, and temporal patience correlating to highest surplus share and deal rates. Training experiments fine-tune Qwen3 (8B, 14B) via SFT followed by GRPO against a fixed opponent, finding that SFT approximately doubles surplus share but reduces deal rates while RL recovers deal rates at the cost of surplus gains; SFT also compresses surplus variation across price tiers and generalizes to unseen opponents.
Significance. If the simulator accurately captures the strategic incentives of private-information bilateral trade, the work supplies a reproducible benchmark for LLM agent capabilities in incomplete-information settings and a concrete training pipeline that exposes trade-offs between surplus maximization and deal completion. The empirical distinction between SFT and RL effects, together with the generalization results, is a useful contribution to understanding how behavioral cloning versus reinforcement learning shapes strategic behavior in LLMs. The automated evaluation framework enabled by tool calls and separated message/offer channels is a technical strength that supports scalable experimentation.
major comments (3)
- [Benchmark Experiments] Benchmark Experiments: The claim that aggressive anchoring, calibrated concession, and temporal patience 'correlate with the highest surplus share and deal rate' is presented without quantitative measures (e.g., correlation coefficients, regression coefficients, or controls for item value and model strength). This is load-bearing for the strategy-identification result that underpins the benchmark findings.
- [Training Experiments] Training Experiments: The statement that 'SFT approximately doubles surplus share' is given without the pre- and post-SFT values, standard errors, number of independent training runs, or statistical tests. The same paragraph reports RL effects on deal rates and surplus; absent variance estimates or run counts, the magnitude and reliability of the reported trade-off cannot be assessed.
- [Environment] Simulator / Environment description: The central modeling choice of separating binding offers from natural-language messages is introduced without validation against human bargaining data, equilibrium predictions (e.g., Myerson-Satterthwaite), or an ablation that integrates messages and offers. Because all reported correlations and training effects rest on this separation, a concrete test comparing outcomes in the separated versus integrated setting is needed to rule out simulator artifacts.
minor comments (2)
- [Abstract] The abstract states '15,000 negotiations' but does not indicate the distribution across model pairs, price tiers, or buyer/seller roles; adding this breakdown would improve interpretability of the tournament results.
- [Methods] Define surplus share and deal rate formally (with equations) in the methods section before reporting numerical outcomes.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below, providing the strongest honest responses possible. We commit to revisions that add quantitative support and statistical detail where feasible, while noting limitations on full external validation.
read point-by-point responses
-
Referee: [Benchmark Experiments] The claim that aggressive anchoring, calibrated concession, and temporal patience 'correlate with the highest surplus share and deal rate' is presented without quantitative measures (e.g., correlation coefficients, regression coefficients, or controls for item value and model strength). This is load-bearing for the strategy-identification result that underpins the benchmark findings.
Authors: We agree that explicit quantitative measures would strengthen the presentation. In the revision we will compute and report Pearson and Spearman correlations between the behavioral metrics (anchoring magnitude, concession speed, response latency) and both surplus share and deal rate. We will also add OLS regressions with controls for item value and model identity to isolate the partial correlations. revision: yes
-
Referee: [Training Experiments] The statement that 'SFT approximately doubles surplus share' is given without the pre- and post-SFT values, standard errors, number of independent training runs, or statistical tests. The same paragraph reports RL effects on deal rates and surplus; absent variance estimates or run counts, the magnitude and reliability of the reported trade-off cannot be assessed.
Authors: We accept that the training results require fuller statistical reporting. The revised manuscript will state the exact pre-SFT and post-SFT mean surplus shares, standard errors across at least three independent training seeds, and paired t-test or Wilcoxon results for the SFT and subsequent GRPO stages. revision: yes
-
Referee: [Environment] Simulator / Environment description: The central modeling choice of separating binding offers from natural-language messages is introduced without validation against human bargaining data, equilibrium predictions (e.g., Myerson-Satterthwaite), or an ablation that integrates messages and offers. Because all reported correlations and training effects rest on this separation, a concrete test comparing outcomes in the separated versus integrated setting is needed to rule out simulator artifacts.
Authors: We recognize the importance of validating the core design choice. A full human-subject replication is beyond the scope of the current study, but we will add an ablation that runs the identical tournament and training pipeline in an integrated channel where natural-language text and offers share a single message stream. We will also include a brief discussion of how the separation is consistent with the distinction between binding commitments and cheap talk in the Myerson-Satterthwaite framework. revision: partial
Circularity Check
No significant circularity: all claims are empirical simulation outcomes
full rationale
The paper reports benchmark tournaments and training runs (SFT + GRPO) inside an event-driven simulator. No mathematical derivation chain, first-principles prediction, or fitted parameter is presented as a result; every reported correlation (anchoring, concession, surplus share, deal rate, tier generalization) is an observed statistic from 15,000+ negotiations against fixed opponents. The environment definition and reward structure are explicit inputs, not outputs derived from the same equations. No self-citation load-bearing step, ansatz smuggling, or renaming of known results occurs. The central claims therefore remain independent of any internal reduction.
Axiom & Free-Parameter Ledger
invented entities (1)
-
event-driven simulator separating binding offers from natural-language messages
no independent evidence
Reference graph
Works this paper leans on
-
[1]
doi: 10.1037/0022-3514.81.4.657. Gemini Team. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025. Etan A Green and E Barry Plunkett. The science of the deal: Optimal bargaining on ebay using deep reinforcement learning. InProceedings of the 2...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1037/0022-3514.81.4.657 2025
-
[2]
doi: 10.1287/moor.6.1.58. Roger B. Myerson and Mark A. Satterthwaite. Efficient mechanisms for bilateral trading. Journal of Economic Theory, 29(2):265–281, 1983. doi: 10.1016/0022-0531(83)90048-0. John F. Nash. The bargaining problem.Econometrica, 18(2):155–162, 1950. doi: 10.2307/ 1907266. Jihwan Oh, Murad Aghazada, Se-Young Yun, and Taehyeon Kim. Llm a...
-
[3]
Proximal Policy Optimization Algorithms
doi: 10.2307/1912531. John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. DeepSeekMath: Pushing the limits of mathemat...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.2307/1912531 2017
-
[4]
Pop the next event batch from the queue (events sharing the same timestamp and agent)
-
[5]
Advance the simulation clock to the event timestamp
-
[6]
Seller proposed$1,500
Convert events to a natural-language observation (e.g., “Seller proposed$1,500”; “Buyer rejected your offer and proposed$1,200”)
-
[7]
Route the observation to the counterpart agent
-
[8]
The counterpart generates a Thought: block (internal reasoning, hidden from the opponent) followed by aCode:block (tool calls). 48
-
[9]
The simulator parses and executes the tool calls, creating new events
-
[10]
Used Laptop
Check termination conditions; if not met, return to step 1. A.4 Example Negotiation Transcripts GFT example.Item: “Used Laptop” (historical high$1,500, historical low$800). Buyer reservation price b = $1,200; seller reservation price s = $900. ZOPA = [900 , 1200]; total surplus = $300. Round Agent Action 1 Sellermake offer(1400) 2 Buyersend message(‘‘Your...
-
[11]
Demonstration generation.DeepSeek-R1 self-play negotiations are generated within the simulator using the same system prompt template, tool definitions, and item catalog used in the benchmark (Section 4.1)
-
[12]
<think>...</think> reasoning blocks are removed from input prompts (but retained in target completions), as described in Section 5.2
Reasoning-trace cleaning. <think>...</think> reasoning blocks are removed from input prompts (but retained in target completions), as described in Section 5.2
-
[13]
Turn-level decomposition.Each multi-turn trajectory is decomposed into autoregressive training samples of increasing context length (Section 5.2)
-
[14]
Loss is computed only on output tokens
Format conversion.Samples are converted to input–output pairs, where the input concatenates the system prompt and conversation history and the output is the target agent response. Loss is computed only on output tokens. SFT hyperparameters.Table 12 lists the SFT training hyperparameters for both model sizes. Training uses the TRL SFTTrainer with DeepSpeed...
2020
-
[15]
Generate a synthetic quit negotiation response (with Thought/Code blocks matching the expected format)
-
[16]
Attach synthetic logprobs using the PAD token (token ID 151643, <|endoftext|> in Qwen models) with a nominal logprob of−0.1
-
[17]
Execute the synthetic response through the environment, terminating the negotiation with no deal
-
[18]
The choice of the PAD token is critical
Assign rewardR= 0. The choice of the PAD token is critical. An early implementation used token ID 1 (the double-quote character " in Qwen’s vocabulary), which created real gradient updates: with a negative advantage from the failed negotiation, GRPO would systematically decrease the probability of generating double quotes after long contexts. The PAD toke...
-
[19]
The training process computes gradients over accumulated batches
-
[20]
After 8 gradient steps, it initiates weight synchronization
-
[21]
The vLLM server atomically swaps model weights
-
[22]
B.6 Training Dynamics The training process naturally progresses through three phases:
Subsequent rollouts use the updated policy immediately. B.6 Training Dynamics The training process naturally progresses through three phases:
-
[23]
Rewards are dominated by Rparsing and Rexecution (Equation (8) and Table 8), as successful negotiations are rare
Tool mastery (steps 1–20).The agent learns to generate well-formed tool calls and execute valid code. Rewards are dominated by Rparsing and Rexecution (Equation (8) and Table 8), as successful negotiations are rare
-
[24]
IR violation rates drop from >30% to<5%
Constraint awareness (steps 20–40).The agent begins respecting IR constraints, learning to reject offers that yield negative utility. IR violation rates drop from >30% to<5%
-
[25]
C Frontier Benchmark: Supplementary Results This appendix provides supplementary figures and tables for the frontier model benchmark (Section 4)
Strategic optimization (steps 40–58).With basic competence established, the agent develops negotiation strategies: anchoring with aggressive opening offers, progressive concessions, and strategic outside-option exercise. C Frontier Benchmark: Supplementary Results This appendix provides supplementary figures and tables for the frontier model benchmark (Se...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.