Evaluating Adaptive Personalization of Educational Readings with Simulated Learners
Pith reviewed 2026-05-15 06:42 UTC · model grok-4.3
The pith
Adaptive personalization of readings significantly improves outcomes for simulated computer science learners but shows smaller or neutral effects in chemistry and biology.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
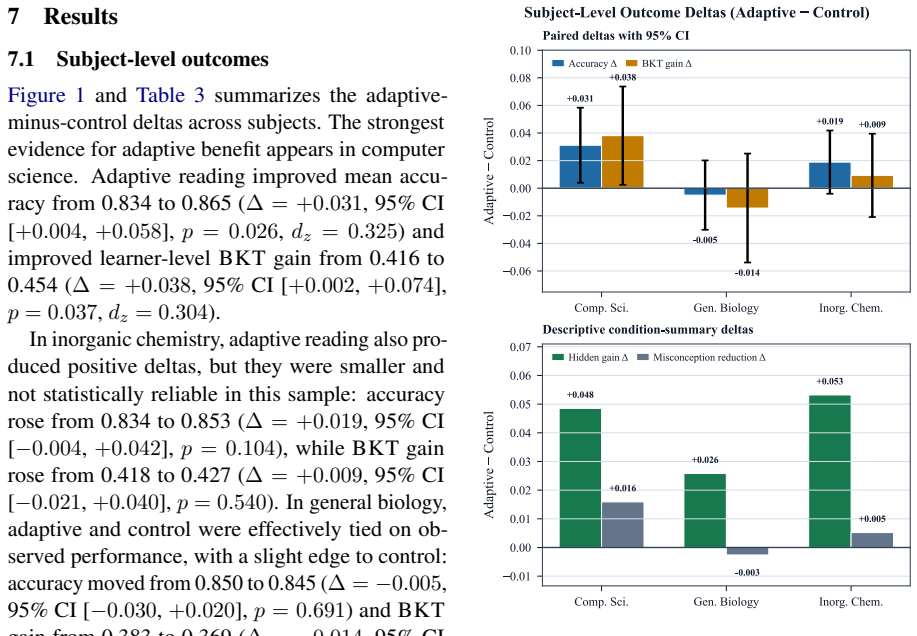
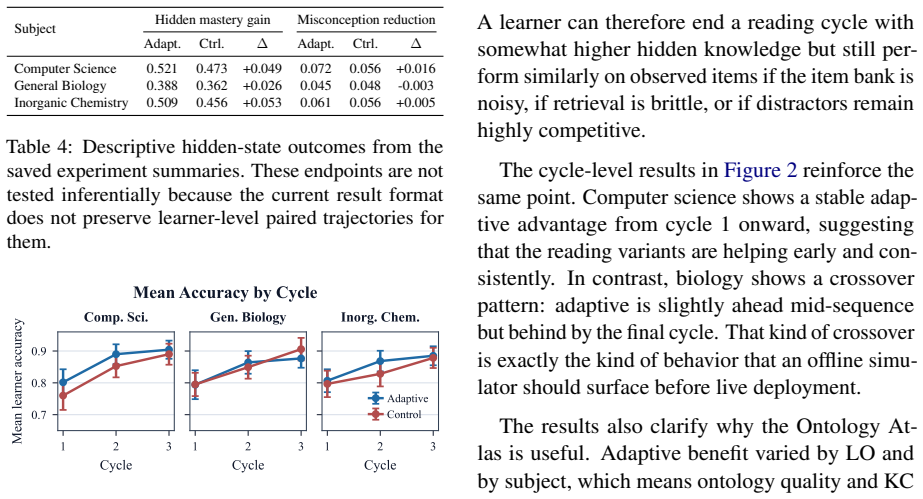
Across three sampled subject ontologies and matched cohorts of 50 simulated learners per condition, adaptive reading significantly improved outcomes in computer science, yielded smaller positive but inconclusive gains in inorganic chemistry, and was neutral to slightly negative in general biology.
What carries the argument
A Construction-Integration-inspired memory model with DIME-style reader factors, KREC-style misconception revision, New Dale-Chall readability signals, and BKT-driven adaptation that selects passages based on the learner's explicit memory state.
If this is right
- Personalization algorithms may require domain-specific tuning because the same adaptation mechanism produces different effects across computer science, chemistry, and biology.
- Ontology-based labeling of textbook chunks enables scalable generation of aligned reading-assessment pairs for evaluation.
- Simulated cohorts allow repeated testing of adaptation rules before any real-student deployment.
- Score-based option selection from the learner's explicit memory state provides a transparent way to generate assessment answers without external knowledge.
Where Pith is reading between the lines
- The framework could be extended to compare alternative adaptation policies such as difficulty sequencing or example selection within the same simulated environment.
- Neutral results in biology suggest that domain-specific structures in learner models may need additional components to capture reading processes in that field.
- If the simulation proves predictive, it could serve as a low-cost filter for selecting which personalization features to test in live classrooms.
Load-bearing premise
The memory and adaptation processes in the simulated learners accurately reflect how real students process and retain information from textbook passages.
What would settle it
Running the identical adaptive versus non-adaptive conditions with actual students and obtaining outcome patterns that differ substantially from the simulated results in any of the three subjects.
Figures
read the original abstract
We present a framework for evaluating adaptive personalization of educational reading materials with theory-grounded simulated learners. The system builds a learning-objective and knowledge-component ontology from open textbooks, curates it in a browser-based Ontology Atlas, labels textbook chunks with ontology entities, and generates aligned reading-assessment pairs. Simulated readers learn from passages through a Construction-Integration-inspired memory model with DIME-style reader factors, KREC-style misconception revision, and an open New Dale-Chall readability signal. Answers are produced by score-based option selection over the learner's explicit memory state, while BKT drives adaptation. Across three sampled subject ontologies and matched cohorts of 50 simulated learners per condition, adaptive reading significantly improved outcomes in computer science, yielded smaller positive but inconclusive gains in inorganic chemistry, and was neutral to slightly negative in general biology.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a framework for evaluating adaptive personalization of educational reading materials using theory-grounded simulated learners. Ontologies are built from open textbooks via an Ontology Atlas, chunks are labeled, and aligned reading-assessment pairs are generated. Learners process passages via a Construction-Integration-inspired memory model incorporating DIME-style reader factors, KREC-style misconception revision, New Dale-Chall readability, and BKT-driven adaptation; answers are produced by score-based option selection over explicit memory states. Across three subject ontologies and matched cohorts of 50 simulated learners per condition, the paper reports that adaptive reading significantly improved outcomes in computer science, produced smaller positive but inconclusive gains in inorganic chemistry, and was neutral to slightly negative in general biology.
Significance. If the simulated learner model is shown to be a reasonable proxy for human reading and retention, the framework offers a scalable, reproducible method for testing adaptive educational interventions without immediate reliance on human subjects, which could accelerate iteration in personalized learning research. The use of open textbooks, explicit ontology construction, and a composite memory model grounded in established theories (CI, DIME, KREC, BKT) strengthens the approach's transparency and potential for extension.
major comments (3)
- [Methods (simulation and adaptation subsections)] The headline comparative results (significant CS gains, inconclusive chemistry gains, neutral biology) rest entirely on forward simulations whose parameters in the memory model, misconception revision, and BKT component are free and uncalibrated against human data. No section reports correlation of simulated vs. observed pre/post-test deltas, retention curves, or misconception revision rates, so the subject-specific pattern cannot be interpreted as evidence about adaptive reading rather than an artifact of the simulator's update rules.
- [Results (abstract and main results section)] The abstract asserts that adaptive reading 'significantly improved outcomes' in computer science, yet no statistical details (p-values, effect sizes, confidence intervals, or variance across the 50-learner cohorts) are supplied or described. With n=50 per condition, these quantities are required to substantiate the claim and to assess whether the chemistry and biology patterns are inconclusive due to low power or genuinely null effects.
- [Methods (learner model and scoring)] The option-selection heuristic and memory-update rules are presented as capturing real reader behavior, but the manuscript contains no sensitivity analysis or ablation showing how the reported subject differences change when key parameters (e.g., DIME factor weights or KREC revision thresholds) are varied within plausible ranges. This leaves the central claim vulnerable to the specific modeling choices.
minor comments (2)
- [Methods] The New Dale-Chall readability signal is mentioned but its exact integration into the memory model (e.g., as a scaling factor on activation or as a separate decay term) is not specified with an equation or pseudocode.
- [Results] Figure captions and table legends should explicitly state the number of simulation runs, random seeds, and whether error bars represent standard error or standard deviation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our simulation framework. We address each major comment below and commit to revisions that strengthen the manuscript without overstating its scope as a purely simulation-based evaluation tool.
read point-by-point responses
-
Referee: [Methods (simulation and adaptation subsections)] The headline comparative results (significant CS gains, inconclusive chemistry gains, neutral biology) rest entirely on forward simulations whose parameters in the memory model, misconception revision, and BKT component are free and uncalibrated against human data. No section reports correlation of simulated vs. observed pre/post-test deltas, retention curves, or misconception revision rates, so the subject-specific pattern cannot be interpreted as evidence about adaptive reading rather than an artifact of the simulator's update rules.
Authors: We agree that the model parameters are not calibrated against human data and that no such correlations are reported, as the paper's contribution is a reproducible simulation framework grounded in established theories rather than a direct claim of human equivalence. The domain differences emerge from the interaction of ontology structures with fixed, literature-derived parameters. We will add an explicit limitations section discussing the absence of human validation and outlining plans for future empirical calibration studies. revision: partial
-
Referee: [Results (abstract and main results section)] The abstract asserts that adaptive reading 'significantly improved outcomes' in computer science, yet no statistical details (p-values, effect sizes, confidence intervals, or variance across the 50-learner cohorts) are supplied or described. With n=50 per condition, these quantities are required to substantiate the claim and to assess whether the chemistry and biology patterns are inconclusive due to low power or genuinely null effects.
Authors: We will revise the abstract and results section to include the missing statistical details, specifically p-values from appropriate tests, effect sizes such as Cohen's d, confidence intervals, and variance measures across the 50-learner cohorts. This will substantiate the CS claim and clarify the power and interpretation of the chemistry and biology results. revision: yes
-
Referee: [Methods (learner model and scoring)] The option-selection heuristic and memory-update rules are presented as capturing real reader behavior, but the manuscript contains no sensitivity analysis or ablation showing how the reported subject differences change when key parameters (e.g., DIME factor weights or KREC revision thresholds) are varied within plausible ranges. This leaves the central claim vulnerable to the specific modeling choices.
Authors: We will add a sensitivity analysis to the revised methods and results, systematically varying key parameters including DIME factor weights and KREC revision thresholds within plausible literature-based ranges. This will demonstrate the robustness of the reported subject-specific patterns to modeling assumptions. revision: yes
Circularity Check
No circularity: forward simulation produces outcomes without fitting or self-referential reduction
full rationale
The paper evaluates adaptive reading by running forward simulations of 50 learners per condition using a Construction-Integration memory model augmented with DIME reader factors, KREC misconception revision, New Dale-Chall readability, and BKT adaptation. The reported subject-specific outcomes (CS gains, chemistry trends, biology neutrality) are direct outputs of these update rules and option-selection heuristics applied to ontology-labeled passages. No equations or sections show parameters fitted to the final deltas, no self-citation chain justifies the core model as a uniqueness theorem, and no renaming or ansatz smuggling reduces the results to inputs by construction. The derivation chain remains independent of the target metrics.
Axiom & Free-Parameter Ledger
free parameters (1)
- parameters in memory model, misconception revision, and BKT
axioms (1)
- domain assumption Construction-Integration memory model with DIME reader factors and KREC misconception revision accurately represents human reading comprehension and learning
Reference graph
Works this paper leans on
-
[1]
Xiaoli Huang, Wei Xu, and Ruijia Liu
Developing, analyzing, and using distractors for multiple-choice tests in education: A compre- hensive review.Review of Educational Research, 87(6):1082–1116. Xiaoli Huang, Wei Xu, and Ruijia Liu. 2025. Effects of intelligent tutoring systems on educational outcomes: Evidence from a comprehensive analysis.Interna- tional Journal of Distance Education Tech...
work page 2025
-
[2]
Zhihao Yuan, Yunze Xiao, Ming Li, Weihao Xuan, Richard Tong, Mona T
Applications of simulated students: An explo- ration.Journal of Artificial Intelligence in Education, 5(2):135–175. Zhihao Yuan, Yunze Xiao, Ming Li, Weihao Xuan, Richard Tong, Mona T. Diab, and Tom Mitchell
- [3]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.