Precise Debugging Benchmark: Is Your Model Debugging or Regenerating?
Pith reviewed 2026-05-20 23:57 UTC · model grok-4.3
The pith
Frontier LLMs achieve high test-pass rates on debugging but low edit precision because they regenerate rather than minimally fix code.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Frontier models regenerate correct but over-edited solutions during debugging tasks; the PDB framework converts existing coding datasets into precision-aware benchmarks by injecting verified atomic bugs, and the resulting metrics reveal that unit-test success above 76 percent coincides with edit precision below 45 percent even under explicit minimal-edit instructions.
What carries the argument
PDB framework that synthesizes verified atomic bugs and composes them into multi-bug programs, paired with edit-level precision and bug-level recall metrics that count only the necessary changes.
If this is right
- Post-training pipelines for coding models must be redesigned to reward localized, minimal edits rather than full regeneration.
- Iterative or agentic loops do not automatically produce more precise debugging behavior.
- Benchmarks that only measure final test-pass rates will continue to overestimate debugging skill.
- Single-line and multi-line bug variants expose different precision gaps that unit tests alone miss.
Where Pith is reading between the lines
- Training objectives that penalize unnecessary token changes could directly improve the observed precision gap.
- The same synthesis method could be applied to other languages or domains to test whether the regeneration pattern is universal.
- Real bug-fix datasets from open-source repositories could serve as an external check on whether synthetic atomic bugs capture typical fault distributions.
Load-bearing premise
The atomic bugs created by the synthesis process behave like the faults that appear in actual developer workflows.
What would settle it
A direct measurement on real-world bug reports showing that models achieve edit precision above 60 percent when explicitly prompted for minimal changes.
Figures





























read the original abstract
Unlike code completion, debugging requires localizing faults and applying targeted edits. We observe that frontier LLMs often regenerate correct but over-edited solutions during debugging. To evaluate how far LLMs are from precise debugging, we introduce the Precise Debugging Benchmark (PDB) framework, which automatically converts any coding dataset into a debugging benchmark with precision-aware evaluation. PDB generates buggy programs by synthesizing verified atomic bugs and composing them into multi-bug programs. We define two novel metrics, edit-level precision and bug-level recall, which measures how many necessary edits are made and how many bugs are resolved. We release two evaluation benchmarks: PDB-Single-Hard on single-line bugs, and PDB-Multi on multi-line bugs. Experiments show that frontier models, such as GPT-5.1-Codex and DeepSeek-V3.2-Thinking, achieve unit-test pass rates above 76% but exhibit precision below 45%, even when explicitly instructed to perform minimal debugging. Finally, we show that iterative and agentic debugging strategies do not substantially improve precision or recall, highlighting the need to rethink post-training pipelines for coding models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Precise Debugging Benchmark (PDB) framework, which automatically converts coding datasets into debugging benchmarks by synthesizing verified atomic bugs and composing them into multi-bug programs. It defines edit-level precision (measuring necessary targeted edits) and bug-level recall metrics to distinguish precise debugging from over-editing or regeneration. Experiments on PDB-Single-Hard and PDB-Multi show frontier models (e.g., GPT-5.1-Codex, DeepSeek-V3.2-Thinking) achieving >76% unit-test pass rates but <45% precision, even under minimal-debugging instructions; iterative and agentic strategies yield no substantial gains.
Significance. If the synthetic bugs prove representative of real faults, the work identifies a key gap in LLM post-training for coding: models solve tests via regeneration rather than localized fixes. The release of two concrete benchmarks (PDB-Single-Hard, PDB-Multi) and the precision/recall metrics supplies a reproducible evaluation resource that the community can use to measure and improve targeted editing behavior.
major comments (3)
- [Abstract] Abstract (PDB generation paragraph): the claim that synthesized atomic bugs and their compositions serve as faithful proxies for real developer debugging workflows is load-bearing for interpreting low edit-level precision as evidence of 'regeneration' rather than debugging, yet the manuscript supplies no comparison against established real-world bug corpora (e.g., Defects4J or QuixBugs).
- [Abstract] Abstract (bug synthesis description): verification procedures for the atomic bugs (e.g., how each insertion is confirmed to be a genuine fault that requires a specific edit rather than an arbitrary change) are not described, which directly affects the soundness of the edit-level precision metric.
- [Abstract] Abstract (experimental results): the reported precision gap (<45%) lacks any mention of statistical significance testing, confidence intervals, or variance across runs, making it difficult to assess whether the difference from unit-test pass rates is robust.
minor comments (1)
- Clarify in the metric definitions whether edit-level precision counts only exact string matches to the inserted bug locations or allows semantically equivalent but differently located fixes.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below in a point-by-point fashion and indicate the changes planned for the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract (PDB generation paragraph): the claim that synthesized atomic bugs and their compositions serve as faithful proxies for real developer debugging workflows is load-bearing for interpreting low edit-level precision as evidence of 'regeneration' rather than debugging, yet the manuscript supplies no comparison against established real-world bug corpora (e.g., Defects4J or QuixBugs).
Authors: We agree that validating the representativeness of the synthetic bugs against real-world corpora strengthens the interpretation of the precision results. The synthesis approach was chosen to enable atomic, verifiable bugs that support the edit-level precision metric, which is difficult to obtain from existing corpora. In the revision we will add a dedicated limitations and validation subsection that compares bug characteristics (e.g., edit span, failure mode distribution) with Defects4J and QuixBugs using publicly available metadata, while noting that a full end-to-end evaluation on real bugs remains future work. revision: partial
-
Referee: [Abstract] Abstract (bug synthesis description): verification procedures for the atomic bugs (e.g., how each insertion is confirmed to be a genuine fault that requires a specific edit rather than an arbitrary change) are not described, which directly affects the soundness of the edit-level precision metric.
Authors: The verification procedure—inserting a candidate edit, confirming the original tests pass, the modified program fails, and the minimal edit restores passage—is described in Section 3.2 of the full manuscript. To address the abstract-level concern we will add a concise sentence in the abstract summarizing the verification step. revision: yes
-
Referee: [Abstract] Abstract (experimental results): the reported precision gap (<45%) lacks any mention of statistical significance testing, confidence intervals, or variance across runs, making it difficult to assess whether the difference from unit-test pass rates is robust.
Authors: We concur that statistical details improve interpretability. The revised manuscript will report 95% confidence intervals and standard deviation across five independent runs for both unit-test pass rate and edit precision on the main results tables and will briefly note this in the abstract. revision: yes
Circularity Check
No significant circularity in derivation or metrics
full rationale
The paper constructs PDB by synthesizing verified atomic bugs into programs and directly defines edit-level precision and bug-level recall from counts of matching edits and resolved bugs. These are definitional choices for the benchmark rather than fitted parameters or equations that reduce outputs to inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps in the abstract or described framework. Results are empirical measurements of model behavior on the self-generated benchmark, making the central claims self-contained without circular reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Synthesized atomic bugs can be verified as causing the observed failure and remain minimal.
invented entities (1)
-
edit-level precision metric
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
PDB generates buggy programs by synthesizing verified atomic bugs and composing them into multi-bug programs. We define two novel metrics, edit-level precision and bug-level recall
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We observe that frontier LLMs often regenerate correct but over-edited solutions during debugging
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A study on robustness and reliability of large language model code generation.arXiv preprint arXiv:2308.13888. Robert L Glass. 2002.Facts and fallacies of software engineering. Addison-Wesley Professional. Jiawei Guo, Ziming Li, Xueling Liu, Kaijing Ma, Tianyu Zheng, Zhouliang Yu, Ding Pan, Yizhi Li, Ruibo Liu, Yue Wang, and 1 others. 2024. Codeedi- torbe...
-
[2]
Measuring Coding Challenge Competence With APPS
Measuring coding challenge competence with apps.arXiv preprint arXiv:2105.09938. Jinyang Huang, Xiachong Feng, Qiguang Chen, Hanjie Zhao, Zihui Cheng, Jiesong Bai, Jingxuan Zhou, Min Li, and Libo Qin. 2025. Mldebugging: Towards benchmarking code debugging across multi-library scenarios.arXiv preprint arXiv:2506.13824. Binyuan Hui, Jian Yang, Zeyu Cui, Jia...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
StarCoder: may the source be with you!
Spoc: Search-based pseudocode to code.Ad- vances in Neural Information Processing Systems, 32. Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, and 1 others. 2023. Starcoder: may the source be with you!arXiv preprint arXiv:2305.06161. Yujia Li, David Choi, Juny...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 8647–8657
Debugbench: Evaluating debugging capability of large language models. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 8647–8657. Manav Singhal, Tushar Aggarwal, Abhijeet Awasthi, Nagarajan Natarajan, and Aditya Kanade. 2024. No- funeval: Funny how code lms falter on require- ments beyond functional correctness.arX...
-
[5]
Vibe checker: Aligning code evaluation with human preference.arXiv preprint arXiv:2510.07315. Yixuan Zhu, Zhitong Zeng, Zhaoxue Liu, Yixing Feng, Yuming Sun, Zhaoyang Chen, Yiling Liu, and Haoyu Wang. 2024. Livecodebench: Holistic and contami- nation free evaluation of large language models for code. InProceedings of the 12th International Con- ference on...
-
[6]
demonstrates autonomous repair capabilities, and COAST (Yang et al., 2024b) enhances debug- ging through communicative agent-based data syn- thesis. These approaches utilize techniques ranging from zero-shot prompting to multi-turn conversa- tional agents (Chen et al., 2023; Fan and Xia, 2024; Xia and Zhang, 2023; Zhong et al., 2024; Islam et al., 2024). ...
work page 2023
-
[7]
examine automatic bug fixing performance on existing datasets. A common limitation of these benchmarks, however, is their reliance on a sim- ple, binary pass/fail metric on test cases (Zhang Model Precision Recall Unit (%) Claude-Sonnet-4.578.1±0.785.7±0.6 81.9±0.9 Gemini-2.5-Pro 77.9±0.787.5±0.683.8±0.8 Qwen3-Coder-480B 73.5±0.8 82.4±0.7 77.4±0.9 Kimi-K2...
work page 2024
-
[10]
config.read(config_file_path) 8
-
[11]
project_dir = config.get('Project', 'directory') 10
-
[13]
raise FileNotFoundError(f'Directory {project_dir} does not exist.') 13
-
[14]
archive_file = f'{archieve_dir}/{project_dir}.z ip' A (Modify) 15
-
[16]
shutil.make_archive(base_name=os.path.splitext(archive_fil e)[0], format='zip', root_dir=project_dir) 18
-
[18]
Failed to create archive {archive_fi le}
raise Exception(f"Failed to create archive {archive_fi le}") 21
-
[19]
return True Add: Line added to inject bug Delete: Line removed to inject bug Modify: Line changed to inject bug Bug Injection: gpt-5.1-codex Model Generated Solution
-
[20]
def task_func(config_file_path, archieve_dir ='/home/user/arch ive'): 5
-
[21]
if not os.path.isfile(config_file_path):
-
[22]
Config file {config_file_pat h} does not exist
raise FileNotFoundError(f"Config file {config_file_pat h} does not exist.") 8
-
[23]
config = configparser.ConfigParser()
-
[24]
config.read(config_file_path) 11
-
[25]
project_dir = config.get('Project', 'directory') 13
-
[26]
if not os.path.isdir(project_dir):
-
[27]
raise FileNotFoundError(f'Directory {project_dir} does not exist.') 16
-
[28]
archive_file = f'{archieve_dir}/{os.path.basename(proj ect_dir)}.zip' A 18
-
[29]
# Using shutil to create the zip archive
-
[30]
shutil.make_archive(base_name=os.path.splitext(archive_fil e)[0], format='zip', root_dir=project_dir) 21
-
[31]
if not os.path.isfile(archive_file):
-
[32]
Failed to create archive {archive_fi le}
raise Exception(f"Failed to create archive {archive_fi le}") 24
-
[33]
📋Task Description Draw a circle with a given radius on the polar chart 'ax' and set radial ticks
return True Fixed bug Extra editIntroduced bug Debug Model: gemini-2.5-pro Figure 11: Redundant guard checks (9.8%): The model adds unnecessary defensive checks that don’t affect correctness. 📋Task Description Draw a circle with a given radius on the polar chart 'ax' and set radial ticks. This function manipulates plot data using matplotlib. Note: If the ...
-
[37]
if not isinstance(ax, plt.PolarAxes):
-
[41]
ax.set_rlabel_position(radius * 45)
-
[42]
return ax Add: Line added to inject bug Delete: Line removed to inject bug Modify: Line changed to inject bug Bug Injection: claude-sonnet-4.5 Model Generated Solution
-
[44]
def task_func(ax, radius): 4
-
[45]
raise ValueError('Radius must be non-negative')
-
[46]
if ax.name != 'polar':
-
[47]
raise TypeError('ax must be a polar plot') 9
-
[48]
theta = np.linspace(0, 2 * np.pi, 1000)
-
[49]
ax.plot(theta, radius * np.ones_like(theta))
-
[50]
ax.set_rlabel_position(45) — ax.draw()
-
[51]
return ax Fixed bug Extra editIntroduced bug Debug Model: Kimi-K2-Thinking Figure 12: Additional modifications (66.8%): The model makes additional modifications to correct code blocks beyond what is required to fix the bug. 📋Task Description Organize files in a directory based on the first text that is not enclosed in square brackets. Move the files to su...
-
[56]
with open(os.path.join(directory, filename), 'r') as f ile:
-
[58]
match = re.search('(.*?)\[.*?\]', content)
-
[59]
subdirectory = match.group(1).strip() 15
-
[61]
os.makedirs(os.path.join(directory, subdir ectory)) 18
-
[62]
{filename.split('.')[0]}_{dat etime.now().strftime(DATE_FORMAT)}.{filename.split('.')[1]}
new_filename = f"{filename.split('.')[0]}_{dat etime.now().strftime(DATE_FORMAT)}.{filename.split('.')[1]}"
-
[63]
shutil.move(os.path.join(directory, filename), os.path.join(directory, subdirectory, new_filename)) 21
-
[66]
moved_files[subdirectory].append(new_filename) 25
-
[67]
return directory.resolve(), moved_files A (Modify) Add: Line added to inject bug Delete: Line removed to inject bug Modify: Line changed to inject bug Bug Injection: claude-sonnet-4.5 Model Generated Solution
-
[68]
from datetime import datetime
-
[69]
def task_func(directory): 6
-
[70]
DATE_FORMAT = '%Y%m%d%H%M%S'
-
[71]
for filename in os.listdir(directory):
-
[72]
filepath = os.path.join(directory, filename)
-
[73]
if os.path.isfile(filepath):
-
[74]
with open(filepath, 'r') as file:
-
[75]
content = file.read()
-
[76]
match = re.search(r'^(.*?)\[(.*?)\](.*)$', con tent, re.DOTALL)
-
[77]
match = re.search(r'\[(.*?)\](.*)$', conte nt, re.DOTALL)
-
[78]
before_brackets = content[:match.start ()]
-
[79]
first_non_bracket_text = before_bracke ts.split()[-1] if before_brackets.split() else ""
-
[80]
subdirectory = first_non_bracket_text
-
[81]
before_first_bracket = match.group(1)
-
[82]
parts = before_first_bracket.strip().split ()
-
[83]
subdirectory = parts[-1] if parts else "" 27
-
[84]
if not subdirectory:
-
[85]
if not os.path.exists(os.path.join(directory, subdirectory)):
-
[86]
os.makedirs(os.path.join(directory, subdir ectory)) 33
-
[87]
name_part, ext_part = os.path.splitext(filenam e)
-
[88]
{name_part}_{datetime.now().s trftime(DATE_FORMAT)}{ext_part}
new_filename = f"{name_part}_{datetime.now().s trftime(DATE_FORMAT)}{ext_part}"
-
[89]
shutil.move(filepath, os.path.join(directory, subdirectory, new_filename)) 37
-
[90]
if subdirectory not in moved_files:
-
[91]
moved_files[subdirectory] = []
-
[92]
moved_files[subdirectory].append(new_filename) 41
-
[93]
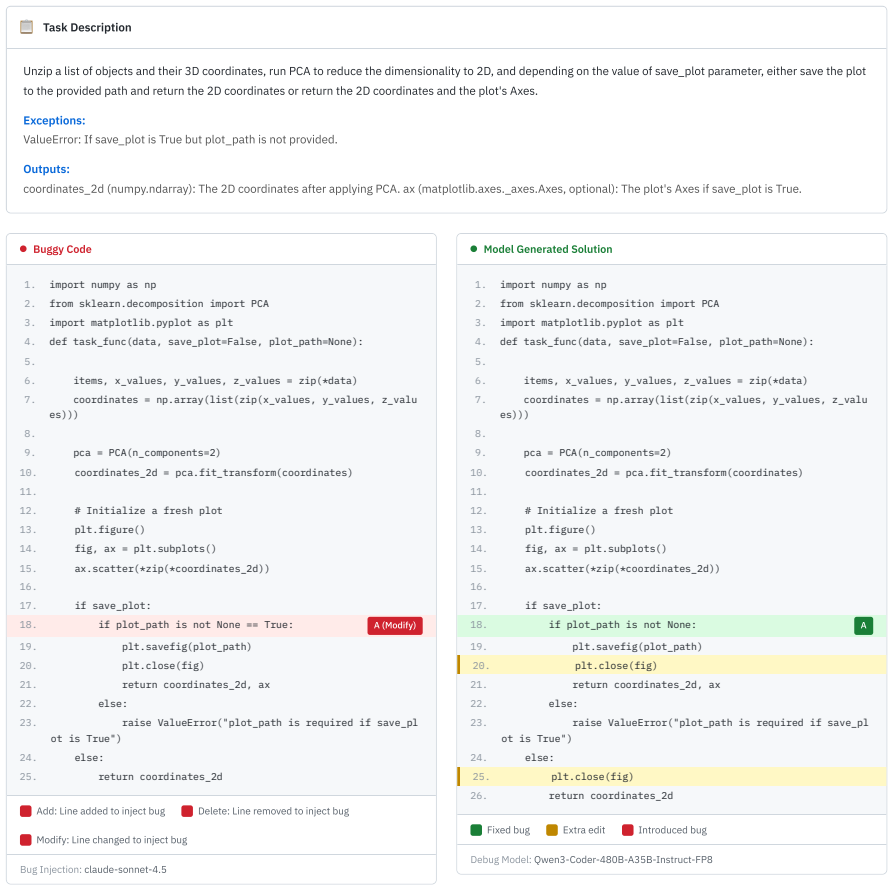
return os.path.abspath(directory), moved_files A Fixed bug Extra editIntroduced bug Debug Model: Qwen3-Coder-480B-A35B-Instruct-FP8 Figure 13: Complete rewrite (7.8%): The model completely regenerates the solution rather than making minimal targeted fixes. 📋Task Description Unzip a list of objects and their 3D coordinates, run PCA to reduce the dimensiona...
-
[104]
if plot_path is not None == True: A (Modify)
-
[108]
return coordinates_2d Add: Line added to inject bug Delete: Line removed to inject bug Modify: Line changed to inject bug Bug Injection: claude-sonnet-4.5 Model Generated Solution
-
[109]
from sklearn.decomposition import PCA
-
[111]
def task_func(data, save_plot=False, plot_path=None): 5
-
[112]
items, x_values, y_values, z_values = zip(*data)
-
[113]
coordinates = np.array(list(zip(x_values, y_values, z_valu es))) 8
-
[114]
pca = PCA(n_components=2)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.