Grokking of Diffusion Models: Case Study on Modular Addition
Pith reviewed 2026-05-10 05:24 UTC · model grok-4.3
The pith
Diffusion models exhibit grokking on modular addition by composing periodic operand representations or separating arithmetic computation from visual denoising across sampling timesteps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Diffusion models with flow-matching objectives exhibit grokking on modular addition. Mechanistic analysis shows that in a single-image regime the models implement the operation by composing periodic representations of the individual operands. In a diverse-image regime the models exploit their iterative sampling to divide the task into an arithmetic computation phase followed by a visual denoising phase separated by a critical timestep.
What carries the argument
The iterative sampling process under flow-matching training that partitions modular addition into distinct arithmetic and denoising phases or composes periodic representations of operands.
If this is right
- Diffusion models can bridge continuous pixel-space generation with discrete symbolic reasoning through their sampling dynamics.
- Grokking provides a controlled window into algorithmic learning inside generative models beyond transformers.
- The separation of computation and denoising phases offers a natural decomposition for tasks mixing reasoning and generation.
- Similar internal structures may appear in other arithmetic or logical operations learned by diffusion models.
Where Pith is reading between the lines
- The same phase-separation mechanism could be tested on other symbolic tasks such as modular multiplication to check if arithmetic always precedes denoising.
- Interventions at the critical timestep might allow selective editing of the computed result without altering the final image style.
- This decomposition suggests diffusion models could serve as hybrid systems for visual and logical problems by design rather than accident.
Load-bearing premise
The internal representations and phase separations uncovered by mechanistic dissection match the model's actual computation rather than arising from data encoding or visualization choices.
What would settle it
Ablating the periodic representations or shifting the identified critical timestep threshold and measuring whether accuracy on unseen modular addition cases drops sharply would falsify the decomposition.
Figures








































read the original abstract
Despite their empirical success, how diffusion models generalize remains poorly understood from a mechanistic perspective. We demonstrate that diffusion models trained with flow-matching objectives exhibit grokking--delayed generalization after overfitting--on modular addition, enabling controlled analysis of their internal computations. We study this phenomenon across two levels of data regime. In a single-image regime, mechanistic dissection reveals that the model implements modular addition by composing periodic representations of individual operands. In a diverse-image regime with high intraclass variability, we find that the model leverages its iterative sampling process to partition the task into an arithmetic computation phase followed by a visual denoising phase, separated by a critical timestep threshold. Our work provides the mechanistic decomposition of algorithmic learning in diffusion models, revealing how these models bridge continuous pixel-space generation and discrete symbolic reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that diffusion models trained with flow-matching objectives exhibit grokking on modular addition, enabling mechanistic analysis of their internal computations. In the single-image regime, the model implements the task by composing periodic representations of individual operands. In the diverse-image regime with high intraclass variability, the iterative sampling process partitions the task into an arithmetic computation phase followed by a visual denoising phase separated by a critical timestep threshold.
Significance. If the mechanistic interpretations are causally validated, the work offers a controlled decomposition of algorithmic learning inside continuous diffusion processes, showing how symbolic reasoning can emerge from pixel-space generation. The grokking lens for dissection is a useful methodological contribution that could generalize to other generative models.
major comments (2)
- [§4.1] §4.1 (single-image regime): The claim that modular addition is implemented via composition of periodic operand representations rests on observational dissection (likely Fourier analysis of activations). Without causal interventions such as targeted ablation or patching of the identified periodic components and measurement of the resulting drop in addition accuracy, it remains possible that these structures are encoding artifacts rather than functionally used computations.
- [§4.2] §4.2 (diverse-image regime): The reported separation of arithmetic computation before a critical timestep from subsequent visual denoising is identified via timestep sweeps or trajectory analysis. The manuscript must specify the quantitative criterion used to locate the threshold (e.g., accuracy curves or activation divergence) and include an intervention test (e.g., forcing early denoising or blocking arithmetic features at that timestep) to rule out visualization or encoding artifacts.
minor comments (2)
- The methods section should explicitly state the flow-matching loss formulation, network architecture details, and exact hyper-parameters used for both regimes to support reproducibility.
- Figure captions for grokking curves and activation visualizations would benefit from explicit scale bars and legends indicating what each color or marker represents.
Simulated Author's Rebuttal
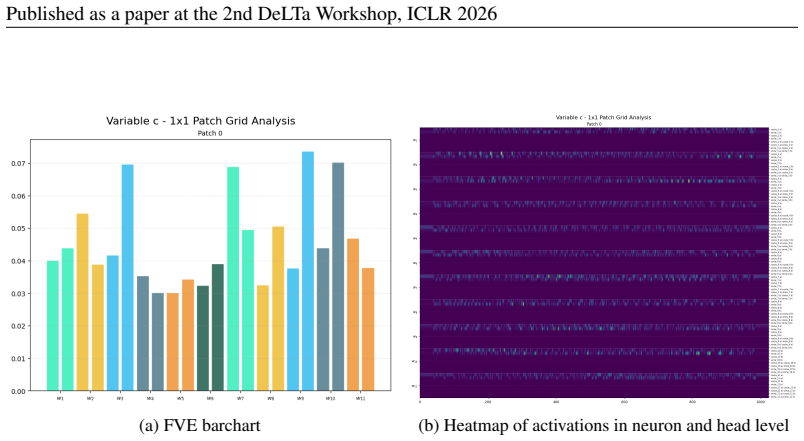
We thank the referee for the constructive feedback on our manuscript. The comments correctly identify opportunities to strengthen the causal evidence for our mechanistic claims. We address each major point below and commit to the indicated revisions.
read point-by-point responses
-
Referee: [§4.1] §4.1 (single-image regime): The claim that modular addition is implemented via composition of periodic operand representations rests on observational dissection (likely Fourier analysis of activations). Without causal interventions such as targeted ablation or patching of the identified periodic components and measurement of the resulting drop in addition accuracy, it remains possible that these structures are encoding artifacts rather than functionally used computations.
Authors: We agree that the analysis in §4.1 is observational and would benefit from causal validation. Our dissection relies on Fourier analysis of activations together with their correlation to task performance across training. In the revised version we will add targeted ablation experiments that zero or perturb the identified periodic components and quantify the resulting drop in modular addition accuracy. This will directly test whether the structures are functionally used rather than artifacts. revision: yes
-
Referee: [§4.2] §4.2 (diverse-image regime): The reported separation of arithmetic computation before a critical timestep from subsequent visual denoising is identified via timestep sweeps or trajectory analysis. The manuscript must specify the quantitative criterion used to locate the threshold (e.g., accuracy curves or activation divergence) and include an intervention test (e.g., forcing early denoising or blocking arithmetic features at that timestep) to rule out visualization or encoding artifacts.
Authors: We will revise §4.2 to state explicitly the quantitative criterion used to identify the critical timestep (the point at which arithmetic accuracy plateaus while image-quality metrics begin to improve, measured via separate probes). We will also add intervention experiments that either block arithmetic features or force early denoising at the identified threshold and report the resulting performance changes. These additions will rule out visualization artifacts. revision: yes
Circularity Check
Empirical mechanistic study of grokking in diffusion models contains no circular derivations
full rationale
The paper reports training diffusion models with flow-matching on modular addition, observes grokking behavior, and performs post-hoc mechanistic dissection of representations and timestep phases. No first-principles derivation, fitted parameter renamed as prediction, or self-citation chain is present; all claims rest on reproducible empirical observations of training dynamics and internal activations rather than any quantity defined in terms of itself. The work is self-contained against external benchmarks of model behavior.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Flow-matching objectives produce diffusion models capable of the described internal computations on modular addition
Reference graph
Works this paper leans on
-
[1]
Tony Bonnaire, Rapha¨el Urfin, Giulio Biroli, and Marc M´ezard. Why diffusion models don’t mem- orize: The role of implicit dynamical regularization in training.arXiv preprint arXiv:2505.17638,
-
[2]
On the edge of memorization in diffusion models.arXiv preprint arXiv:2508.17689, 2025
Sam Buchanan, Druv Pai, Yi Ma, and Valentin De Bortoli. On the edge of memorization in diffusion models.arXiv preprint arXiv:2508.17689,
-
[3]
doi:10.23915/distill.00024 , note =
doi: 10.23915/distill.00024. https://distill.pub/2020/circuits. Tarin Clanuwat, Mikel Bober-Irizar, Asanobu Kitamoto, Alex Lamb, Kazuaki Yamamoto, and David Ha. Deep learning for classical japanese literature.CoRR, abs/1812.01718,
-
[4]
Deep Learning for Classical Japanese Literature
URLhttp: //arxiv.org/abs/1812.01718. Gregory Cohen, Saeed Afshar, Jonathan Tapson, and Andr ´e van Schaik. Emnist: an extension of mnist to handwritten letters.arXiv preprint arXiv:1702.05373,
-
[5]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. Sparse autoen- coders find highly interpretable features in language models.arXiv preprint arXiv:2309.08600,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
arXiv preprint arXiv:2303.06173 , year=
Xander Davies, Lauro Langosco, and David Krueger. Unifying grokking and double descent.arXiv preprint arXiv:2303.06173,
-
[7]
URLhttps://arxiv.org/abs/ 2405.19201. Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kap...
-
[8]
https://transformer-circuits.pub/2021/framework/index.html. 9 Published as a paper at the 2nd DeLTa Workshop, ICLR 2026 Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recog- nition,
work page 2021
-
[9]
Deep Residual Learning for Image Recognition
URLhttps://arxiv.org/abs/1512.03385. Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (gelus),
work page internal anchor Pith review arXiv
-
[10]
Gaussian Error Linear Units (GELUs)
URLhttps:// arxiv.org/abs/1606.08415. Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851,
-
[11]
Generalization in diffusion models arises from geometry-adaptive harmonic representations
Zahra Kadkhodaie, Florentin Guth, Eero P Simoncelli, and St ´ephane Mallat. Generalization in diffusion models arises from geometry-adaptive harmonic representations.arXiv preprint arXiv:2310.02557,
-
[12]
Diffusion models already have a semantic latent space.arXiv preprint arXiv:2210.10960,
URLhttps://arxiv.org/abs/2210.10960. Tianhong Li and Kaiming He. Back to basics: Let denoising generative models denoise.arXiv preprint arXiv:2511.13720,
-
[13]
Back to Basics: Let Denoising Generative Models Denoise
URL https://arxiv.org/abs/2511.13720. Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747,
work page internal anchor Pith review arXiv
-
[14]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022a. Ziming Liu, Eric J Michaud, and Max Tegmark. Omnigrok: Grokking beyond algorithmic data. arXiv preprint arXiv:2210.01117, 2022b. Rui Lu, Runzhe Wang, Kaifeng Lyu, Xitai Jiang, Gao Huang, and...
work page internal anchor Pith review arXiv
-
[15]
Progress measures for grokking via mechanistic interpretability
Neel Nanda, Lawrence Chan, Tom Lieberum, Jess Smith, and Jacob Steinhardt. Progress measures for grokking via mechanistic interpretability.arXiv preprint arXiv:2301.05217,
work page internal anchor Pith review arXiv
-
[16]
URLhttps: //arxiv.org/abs/2310.09336. Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Scott Johnston, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack ...
-
[17]
Core Francisco Park, Maya Okawa, Andrew Lee, Hidenori Tanaka, and Ekdeep Singh Lubana
https://transformer-circuits.pub/2022/in-context-learning-and-induction-heads/index.html. Core Francisco Park, Maya Okawa, Andrew Lee, Hidenori Tanaka, and Ekdeep Singh Lubana. Emergence of hidden capabilities: Exploring learning dynamics in concept space,
work page 2022
-
[18]
URL https://arxiv.org/abs/2406.19370. Yong-Hyun Park, Mingi Kwon, Jaewoong Choi, Junghyo Jo, and Youngjung Uh. Understanding the latent space of diffusion models through the lens of riemannian geometry,
-
[19]
10 Published as a paper at the 2nd DeLTa Workshop, ICLR 2026 William Peebles and Saining Xie
URLhttps: //arxiv.org/abs/2307.12868. 10 Published as a paper at the 2nd DeLTa Workshop, ICLR 2026 William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pp. 4195–4205,
-
[20]
Bao Pham, Gabriel Raya, Matteo Negri, Mohammed J Zaki, Luca Ambrogioni, and Dmitry Krotov. Memorization to generalization: Emergence of diffusion models from associative memory.arXiv preprint arXiv:2505.21777,
-
[21]
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
Alethea Power, Yuri Burda, Harri Edwards, Igor Babuschkin, and Vedant Misra. Grokking: Gen- eralization beyond overfitting on small algorithmic datasets.arXiv preprint arXiv:2201.02177,
work page internal anchor Pith review arXiv
-
[22]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text- conditional image generation with clip latents.arXiv preprint arXiv:2204.06125, 1(2):3,
work page internal anchor Pith review arXiv
-
[23]
GLU Variants Improve Transformer
URLhttps://arxiv.org/abs/ 2002.05202. Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. InInternational conference on machine learn- ing, pp. 2256–2265. pmlr,
work page internal anchor Pith review arXiv 2002
-
[24]
Selective underfitting in diffusion models, 2025
Kiwhan Song, Jaeyeon Kim, Sitan Chen, Yilun Du, Sham Kakade, and Vincent Sitzmann. Selective underfitting in diffusion models.arXiv preprint arXiv:2510.01378,
-
[25]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456,
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[26]
URLhttps://arxiv.org/abs/2410.22366. Zhihua Tian, Sirun Nan, Ming Xu, Shengfang Zhai, Wenjie Qu, Jian Liu, Ruoxi Jia, and Jiaheng Zhang. Sparse autoencoder as a zero-shot classifier for concept erasing in text-to-image diffusion models,
-
[27]
Vikrant Varma, Rohin Shah, Zachary Kenton, J ´anos Kram ´ar, and Ramana Kumar
URLhttps://arxiv.org/abs/2503.09446. Vikrant Varma, Rohin Shah, Zachary Kenton, J ´anos Kram ´ar, and Ramana Kumar. Explaining grokking through circuit efficiency.arXiv preprint arXiv:2309.02390,
-
[28]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 small
11 Published as a paper at the 2nd DeLTa Workshop, ICLR 2026 Kevin Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. Inter- pretability in the wild: a circuit for indirect object identification in gpt-2 small.arXiv preprint arXiv:2211.00593,
work page internal anchor Pith review arXiv 2026
-
[30]
Video models are zero-shot learners and reasoners
Thadd¨aus Wiedemer, Yuxuan Li, Paul Vicol, Shixiang Shane Gu, Nick Matarese, Kevin Swersky, Been Kim, Priyank Jaini, and Robert Geirhos. Video models are zero-shot learners and reasoners. arXiv preprint arXiv:2509.20328,
work page internal anchor Pith review arXiv
-
[31]
URLhttps://arxiv.org/abs/2307. 05596. Bing Wu, Chang Zou, Changlin Li, Duojun Huang, Fang Yang, Hao Tan, Jack Peng, Jianbing Wu, Jiangfeng Xiong, Jie Jiang, et al. Hunyuanvideo 1.5 technical report.arXiv preprint arXiv:2511.18870,
work page internal anchor Pith review arXiv
-
[32]
arXiv preprint arXiv:2303.13336 , year=
Chenshuang Zhang, Chaoning Zhang, Sheng Zheng, Mengchun Zhang, Maryam Qamar, Sung-Ho Bae, and In So Kweon. A survey on audio diffusion models: Text to speech synthesis and en- hancement in generative ai.arXiv preprint arXiv:2303.13336,
-
[33]
gddim: Generalized denoising diffusion implicit models
Qinsheng Zhang, Molei Tao, and Yongxin Chen. gddim: Generalized denoising diffusion implicit models.arXiv preprint arXiv:2206.05564,
-
[34]
12 Published as a paper at the 2nd DeLTa Workshop, ICLR 2026 A IMPLEMENTATIONDETAILS We train our model using the Rectified Flow (RF) framework (Liu et al., 2022a) to predict the velocity vectorv θ(xt, t). Following thex 0-parameterization adopted in this work, the model directly predicts the clean imagex 0, which is related to the velocity byv θ(xt, t) =...
work page 2026
-
[35]
to provide spatial context for the patchified tokens. Feedforward NetworkThe FFN comprises 512 hidden neurons with GeLU activation (Hendrycks & Gimpel, 2023), maintaining a1×expansion ratio to balance capacity and simplic- ity. While we explored more complex variants such as SwiGLU (Shazeer,
work page 2023
-
[36]
Table 2: Model and dataset hyperparameters
for improved reconstruction, we found that the standard GeLU activation offered superior clarity for mechanistic interpretability, specifically in tracking the entropy transitions of pre-activation states. Table 2: Model and dataset hyperparameters. Parameter Value Dataset Modulus (P) 23 Images per symbol (N) 1, 4, 256 Training ratio (R) 0.9 Image resolut...
work page 2048
-
[37]
through dominant 2D Fourier compo- nents across selective frequencies (w1, w3, w7, w9) along with non-significant frequencies. W′L u⊤ k FFNpreact(a, b)andv⊤ k FFNpreact(a, b)FVE cos(w1(a+b)) 138910 cos(w 1a) cos(w1b)−139849 sin(w1a) sin(w1b)0.95 sin(w1(a+b)) 137133 cos(w 1a) sin(w1b) + 136206 sin(w1a) cos(w1b)0.94 cos(w2(a+b)) 939 cos(w 2a) cos(w2b)−426 s...
work page 2026
-
[38]
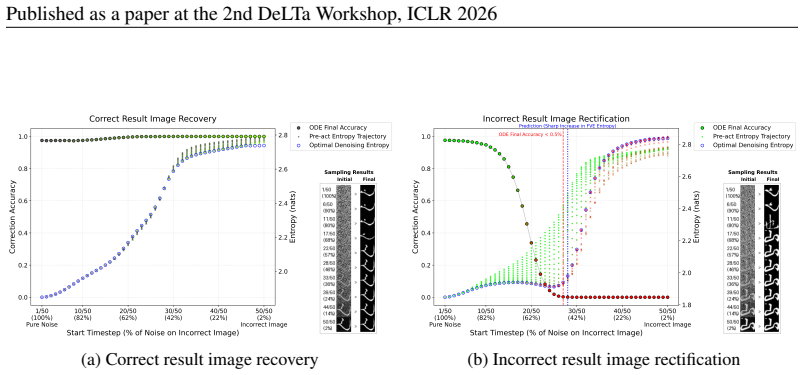
Figure 29:P= 27 Figure 30:P= 31 Figure 31:P= 35 26 Published as a paper at the 2nd DeLTa Workshop, ICLR 2026 Figures 32–34 demonstrate the mode shift during ODE sampling with variousPvalues. As in the baselineP= 23case, we observe similar trajectories for both the recovery of correct answers and the rectification of initially incorrect images. (a) Correct...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.