MoE-nD: Per-Layer Mixture-of-Experts Routing for Multi-Axis KV Cache Compression
Pith reviewed 2026-05-10 05:09 UTC · model grok-4.3
The pith
Per-layer mixture-of-experts routing lets each KV-cache layer pick its own eviction ratio and bit precision, matching uncompressed accuracy at 14x compression where uniform methods lose ground.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
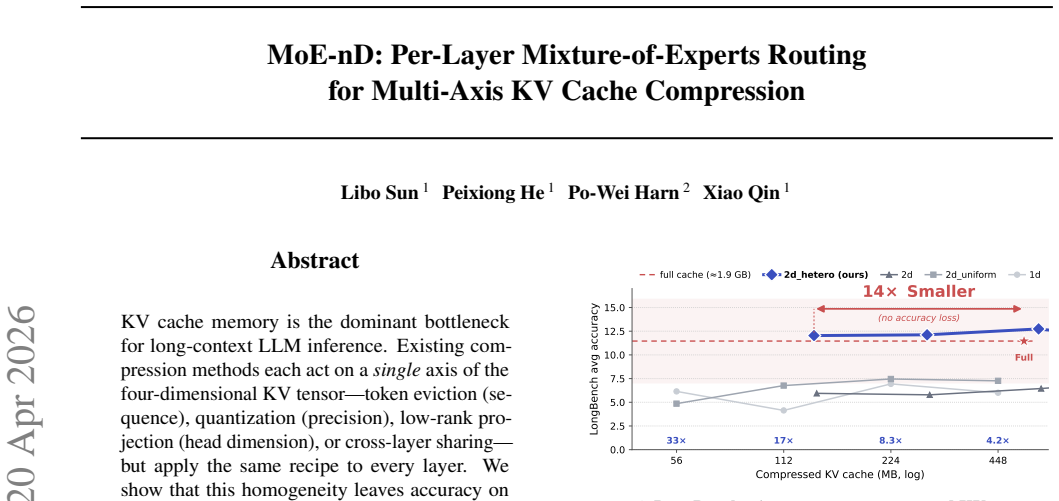
MoE-nD shows that routing each layer independently to a compression configuration (eviction ratio plus K- and V-bit widths) under a shared memory constraint can preserve the accuracy of an uncompressed KV cache at 14x compression on long-context and reasoning benchmarks, whereas any homogeneous per-layer or global policy at comparable memory incurs large quality drops.
What carries the argument
Offline-calibrated greedy solver that selects a per-layer (eviction-ratio, K-bits, V-bits) tuple minimizing predicted quality loss, then applies the heterogeneous choices jointly through a single attention patch at inference time.
If this is right
- Heterogeneous per-layer choices of eviction and quantization outperform any single global compression recipe at high compression ratios.
- The optimal balance between token eviction and bit-width reduction varies substantially across layers within the same model.
- On short inputs the solver often selects full retention, showing that per-layer eviction routing adds value mainly for long-context workloads.
- The approach works through an existing attention kernel with no change to the forward pass beyond the chosen per-layer parameters.
Where Pith is reading between the lines
- Layer-wise routing could be extended to additional compression axes such as low-rank head projections or cross-layer sharing if a joint predictor is trained.
- The null results on MATH-500 and TREC illustrate a clear regime (short sequences) where heterogeneous eviction offers little headroom.
- If the quality predictor can be updated cheaply online, the same framework might support input-dependent routing without retraining the solver.
Load-bearing premise
The quality-loss predictor, calibrated offline on the same model family, ranks compression options correctly for new inputs and that layer-wise sensitivity patterns stay stable enough to justify choosing different configurations per layer.
What would settle it
Measure whether the same routing decisions still recover full baseline accuracy when the predictor is applied to a different model family or to inputs whose length or task distribution differs markedly from the calibration set.
Figures


read the original abstract
KV cache memory is the dominant bottleneck for long-context LLM inference. Existing compression methods each act on a single axis of the four-dimensional KV tensor -- token eviction (sequence), quantization (precision), low-rank projection (head dimension), or cross-layer sharing -- but apply the same recipe to every layer. We show that this homogeneity leaves accuracy on the table: different layers respond very differently to each compression operation, and the optimal per-layer mix of eviction and quantization is far from uniform. We propose MoE-nD, a mixture-of-experts framework that routes each layer to its own (eviction-ratio, K-bits, V-bits) tuple under a global memory budget. An offline-calibrated greedy solver chooses the routing that minimizes predicted quality loss; at inference time, per-layer heterogeneous eviction and quantization are applied jointly through a single attention patch. On a 4-task subset of LongBench-v1 (16k inputs, n=50 per task, adapted reasoning-model protocol; see section Experiments), MoE-nD's hetero variant matches our uncompressed 1.9~GB baseline at 14x compression (136~MB) while every other compressed baseline we tested (1d, 2d_uniform, 2d) at comparable or smaller memory stays under 8/100. The gains hold on AIME reasoning benchmarks (+6 to +27 pts over the strongest per-layer-quantization baseline across eight configurations). Two null results -- MATH-500 and LongBench's TREC -- share a principled cause (short inputs, solver picks keep=1.0 on most layers), cleanly characterizing when per-layer eviction routing has headroom to help.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MoE-nD, a per-layer mixture-of-experts routing framework for multi-axis KV cache compression. An offline-calibrated greedy solver selects heterogeneous (eviction-ratio, K-bit, V-bit) tuples per layer to minimize predicted quality loss under a global memory budget; at inference, these are applied jointly via a single attention patch. On a 4-task LongBench-v1 subset the hetero variant matches the 1.9 GB uncompressed baseline at 14× compression (136 MB) while uniform baselines remain below 8/100, with +6 to +27 pt gains on AIME reasoning tasks; null results on MATH-500 and TREC are attributed to short inputs where the solver defaults to keep=1.0.
Significance. If the results hold, the work demonstrates that exploiting stable layer-wise differences in compression sensitivity can yield substantial accuracy-memory trade-offs beyond uniform per-layer or global recipes. The concrete 14× compression result that matches the uncompressed baseline, together with the clean characterization of when per-layer eviction helps, would be a useful contribution to efficient long-context inference.
major comments (3)
- [Experiments section] Experiments section: the headline claims (14× compression matching the 1.9 GB baseline and +6–27 pt AIME gains) are presented without error bars, standard deviations, or any indication of the number of runs or random seeds, so the statistical reliability of the reported differences cannot be assessed.
- [Method / solver description] Method / solver description: no direct measurement is given of the quality-loss predictor’s ranking accuracy or absolute error on inputs drawn from a distribution disjoint from the calibration set (especially long-context reasoning traces). Because the heterogeneous routing decisions are produced entirely by this offline predictor, the absence of such a test is load-bearing for the central claim that per-layer heterogeneity outperforms uniform baselines.
- [Experiments section] Experiments section: the paper provides neither an ablation isolating the predictor’s contribution nor full implementation details or hyper-parameter settings for the 1d, 2d_uniform, and 2d baselines, preventing independent verification of the reported superiority.
minor comments (2)
- [Experiments section] The phrase “adapted reasoning-model protocol” is used in the abstract and Experiments section without a concise definition or pointer to the exact prompt template and evaluation script.
- Notation for the per-layer tuples (eviction ratio, K-bits, V-bits) could be introduced once in a single equation or table to avoid repeated prose descriptions.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive feedback on our manuscript. We address each of the major comments point by point below, indicating the changes we will make in the revised version.
read point-by-point responses
-
Referee: [Experiments section] Experiments section: the headline claims (14× compression matching the 1.9 GB baseline and +6–27 pt AIME gains) are presented without error bars, standard deviations, or any indication of the number of runs or random seeds, so the statistical reliability of the reported differences cannot be assessed.
Authors: We appreciate this observation. The reported results were obtained from single runs with a fixed seed for each configuration, as the greedy solver is deterministic and the inference procedure does not introduce randomness. The sample size is n=50 per task as stated in the Experiments section. To enhance statistical reliability, we will revise the manuscript to explicitly state the number of runs and seeds used, and we will include error bars by conducting additional runs with varied seeds where feasible, particularly for the AIME gains. revision: partial
-
Referee: [Method / solver description] Method / solver description: no direct measurement is given of the quality-loss predictor’s ranking accuracy or absolute error on inputs drawn from a distribution disjoint from the calibration set (especially long-context reasoning traces). Because the heterogeneous routing decisions are produced entirely by this offline predictor, the absence of such a test is load-bearing for the central claim that per-layer heterogeneity outperforms uniform baselines.
Authors: We agree that validating the predictor on disjoint distributions is crucial. While the calibration set encompasses a variety of tasks from LongBench and reasoning benchmarks, we did not provide explicit ranking accuracy or error metrics on held-out long-context reasoning traces. In the revision, we will add a dedicated evaluation of the quality-loss predictor, including its ranking performance and absolute error on inputs from distributions disjoint from the calibration set, to substantiate the effectiveness of the per-layer routing. revision: yes
-
Referee: [Experiments section] Experiments section: the paper provides neither an ablation isolating the predictor’s contribution nor full implementation details or hyper-parameter settings for the 1d, 2d_uniform, and 2d baselines, preventing independent verification of the reported superiority.
Authors: We acknowledge the need for greater reproducibility. We will include a new ablation study that isolates the contribution of the quality-loss predictor by comparing against variants with uniform or random routing decisions. Additionally, we will provide complete implementation details, including all hyper-parameter settings, for the 1d, 2d_uniform, and 2d baselines in the revised Experiments section to enable independent verification. revision: yes
Circularity Check
No significant circularity; central claim rests on independent benchmark evaluation after offline calibration.
full rationale
The paper derives its routing decisions from an offline-calibrated greedy solver that minimizes a quality-loss predictor's output under a memory budget. This selection is then applied at inference and measured on external benchmarks (LongBench-v1 subset, AIME, MATH-500, TREC). No equation or step equates the reported accuracy gains to the calibration data by construction, nor does any load-bearing premise reduce to a self-citation or renamed ansatz. Layer-wise sensitivity differences are presented as measured observations rather than tautological definitions. The method remains self-contained against held-out evaluation distributions.
Axiom & Free-Parameter Ledger
free parameters (1)
- per-layer eviction ratios and bit widths
axioms (1)
- domain assumption Layer-wise differences in compression sensitivity are stable and predictable from offline calibration data.
invented entities (1)
-
MoE-nD per-layer routing framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
GQA: Training generalized multi-query transformer models from multi-head check- points
Ainslie, J., Lee-Thorp, J., de Jong, M., Zemlyanskiy, Y ., Lebr´on, F., and Sanghai, S. GQA: Training generalized multi-query transformer models from multi-head check- points. InConference on Empirical Methods in Natural Language Processing, 2023
work page 2023
-
[2]
LongBench: A bilingual, multitask benchmark for long context understanding
Bai, Y ., Lv, X., Zhang, J., et al. LongBench: A bilingual, multitask benchmark for long context understanding. In Annual Meeting of the Association for Computational Linguistics, 2024
work page 2024
-
[3]
Kelly, J. R. Reducing transformer key-value cache size with cross-layer attention, 2024
work page 2024
-
[4]
PyramidKV: Dynamic KV cache compression based on pyramidal information funneling, 2024
Xiong, W., Dong, Y ., Hu, J., and Xiao, W. PyramidKV: Dynamic KV cache compression based on pyramidal information funneling, 2024
work page 2024
-
[5]
R-KV: Redundancy-aware KV cache compression for reasoning models
Cai, Z., Xiao, W., Sun, H., et al. R-KV: Redundancy-aware KV cache compression for reasoning models. InAd- vances in Neural Information Processing Systems, 2025
work page 2025
-
[6]
Y ., Ermon, S., Rudra, A., and R´e, C
Dao, T., Fu, D. Y ., Ermon, S., Rudra, A., and R´e, C. FlashAt- tention: Fast and memory-efficient exact attention with 7 MoE-nD: Per-Layer Routing for Multi-Axis KV Compression IO-awareness. InAdvances in Neural Information Pro- cessing Systems, 2022. DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capa- bility in llms via reinforcement learning, 2025
work page 2022
-
[7]
QAQ: Quality adaptive quantization for LLM KV cache, 2024
Dong, S., Cheng, W., Qin, J., and Wang, W. QAQ: Quality adaptive quantization for LLM KV cache, 2024
work page 2024
-
[8]
Feng, Y ., Lv, J., Cao, Y ., Xie, X., and Zhou, S. K. Ada- KV: Optimizing KV cache eviction by adaptive budget allocation for efficient LLM inference. InAdvances in Neural Information Processing Systems, 2025
work page 2025
-
[9]
Measuring mathematical problem solving with the MATH dataset
Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., and Steinhardt, J. Measuring mathematical problem solving with the MATH dataset. InNeurIPS Track on Datasets and Benchmarks, 2021
work page 2021
-
[10]
Hooper, C., Kim, S., Mohammadzadeh, H., Mahoney, M. W., Shao, Y . S., Keutzer, K., and Gholami, A. KVQuant: Towards 10 million context length LLM infer- ence with KV cache quantization. InAdvances in Neural Information Processing Systems, 2024
work page 2024
-
[11]
Li, X., Xing, Z., Li, Y ., Qu, L., Zhen, H.-L., Liu, W., Yao, Y ., Pan, S. J., and Yuan, M. KVTuner: Sensitivity-aware layer-wise mixed-precision KV cache quantization for efficient and nearly lossless LLM inference. InInterna- tional Conference on Machine Learning, 2025
work page 2025
-
[12]
SnapKV: LLM knows what you are looking for before generation
Li, Y ., Huang, Y ., Yang, B., Venkitesh, B., Locatelli, A., Ye, H., Cai, T., Lewis, P., and Chen, D. SnapKV: LLM knows what you are looking for before generation. InAdvances in Neural Information Processing Systems, 2024
work page 2024
-
[13]
Liu, Z., Desai, A., Liao, F., Wang, W., Xie, V ., Xu, Z., Kyril- lidis, A., and Shrivastava, A. Scissorhands: Exploiting the persistence of importance hypothesis for LLM KV cache compression at test time. InAdvances in Neural Information Processing Systems, volume 36, 2023
work page 2023
-
[14]
KIVI: A tuning-free asym- metric 2-bit quantization for KV cache
Liu, Z., Yuan, J., Jin, H., Zhong, S., Xu, Z., Braverman, V ., Chen, B., and Hu, X. KIVI: A tuning-free asym- metric 2-bit quantization for KV cache. InInternational Conference on Machine Learning, 2024
work page 2024
-
[15]
Triattention: Effi- cient long reasoning with trigonometric KV compression, 2026
Mao, W., Lin, X., Huang, W., et al. Triattention: Effi- cient long reasoning with trigonometric KV compression, 2026
work page 2026
-
[16]
MiniKV: Pushing the limits of LLM inference via 2-bit layer-discriminative KV cache, 2024
Sharma, A., Ding, H., Li, J., Dani, N., and Zhang, M. MiniKV: Pushing the limits of LLM inference via 2-bit layer-discriminative KV cache, 2024
work page 2024
-
[17]
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer
Shazeer, N., Mirhoseini, A., Maziarz, K., Davis, A., Le, Q., Hinton, G., and Dean, J. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. InInternational Conference on Learning Representations, 2017
work page 2017
-
[18]
RoFormer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Su, J., Ahmed, M., Lu, Y ., Pan, S., Bo, W., and Liu, Y . RoFormer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
work page 2024
-
[19]
Xia, F., Chi, E., Le, Q. V ., and Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. InAdvances in Neural Information Processing Systems, volume 35, pp. 24824–24837, 2022
work page 2022
-
[20]
Effi- cient streaming language models with attention sinks
Xiao, G., Tian, Y ., Chen, B., Han, S., and Lewis, M. Effi- cient streaming language models with attention sinks. In International Conference on Learning Representations, 2024
work page 2024
- [21]
-
[22]
Solve the equation x2 −5x+ 6 = 0 . Think step by step and show all work
Song, Z., Tian, Y ., R´e, C., Barrett, C., et al. H2O: Heavy- hitter oracle for efficient generative inference of large language models. InAdvances in Neural Information Processing Systems, volume 36, 2023. 8 MoE-nD: Per-Layer Routing for Multi-Axis KV Compression A. Absolute Scores and Instruction-Tuned Models Our 11.5 LongBench average for the uncompres...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.