The Collaboration Gap in Human-AI Work
Pith reviewed 2026-05-10 04:14 UTC · model grok-4.3
The pith
Stable collaboration with AI depends on the interaction's grounding conditions, not just model capability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
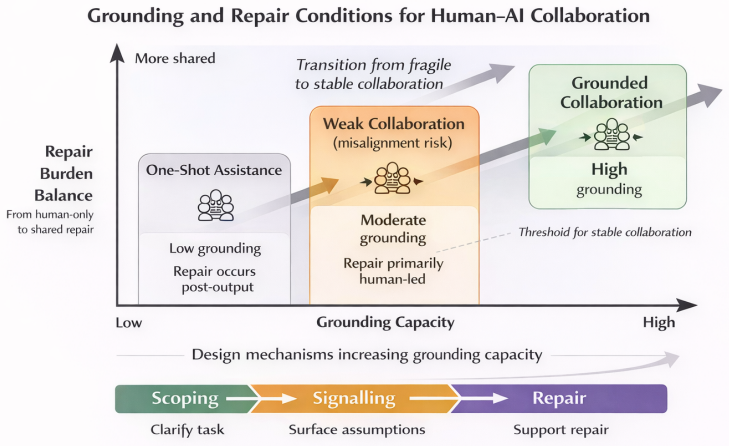
Drawing on a constructivist grounded theory analysis of 16 interviews, the authors argue that stable collaboration depends not only on model capability but on the interaction's grounding conditions. They distinguish three recurrent structures of human-AI work: one-shot assistance, weak collaboration with asymmetric repair, and grounded collaboration. Collaboration breaks down when the appearance of partnership outpaces the grounding capacity of the interaction.
What carries the argument
Grounding conditions in the interaction, which enable shared assumptions and symmetric repair of misalignments across the three identified structures of human-AI work.
If this is right
- Design efforts focused solely on increasing model capability will leave persistent repair burdens on users in weak collaboration settings.
- Interfaces that make grounding explicit, such as shared context summaries or assumption checks, could shift more interactions toward grounded collaboration.
- Evaluation of LLM tools should measure repair effort and grounding failures rather than output quality alone.
- The three structures provide a vocabulary for comparing collaboration experiences across programming, design, and analysis tasks.
Where Pith is reading between the lines
- Developers might reduce user frustration by defaulting to one-shot assistance modes unless explicit grounding features are enabled.
- The framework could extend to non-LLM AI systems where users similarly reconstruct missing context during tasks.
- Training data for future models could incorporate patterns of successful repair to improve baseline grounding.
Load-bearing premise
The conceptual distinctions identified in the 16 interviews represent recurrent and generalizable structures across different human-AI work settings.
What would settle it
Systematic observation of human-AI sessions in additional domains, such as medical analysis or legal review, showing either new collaboration structures or breakdowns driven by factors other than mismatched grounding capacity.
Figures
read the original abstract
LLMs are increasingly presented as collaborators in programming, design, writing, and analysis. Yet the practical experience of working with them often falls short of this promise. In many settings, users must diagnose misunderstandings, reconstruct missing assumptions, and repeatedly repair misaligned responses. This poster introduces a conceptual framework for understanding why such collaboration remains fragile. Drawing on a constructivist grounded theory analysis of 16 interviews with designers, developers, and applied AI practitioners working on LLM-enabled systems, and informed by literature on human-AI collaboration, we argue that stable collaboration depends not only on model capability but on the interaction's grounding conditions. We distinguish three recurrent structures of human-AI work: one-shot assistance, weak collaboration with asymmetric repair, and grounded collaboration. We propose that collaboration breaks down when the appearance of partnership outpaces the grounding capacity of the interaction and contribute a framework for discussing grounding, repair, and interaction structure in LLM-enabled work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a conceptual framework for human-AI collaboration with LLMs based on a constructivist grounded theory analysis of 16 interviews with designers, developers, and applied AI practitioners. It identifies three recurrent structures of human-AI work—one-shot assistance, weak collaboration with asymmetric repair, and grounded collaboration—and argues that stable collaboration depends on the interaction's grounding conditions, breaking down when the appearance of partnership outpaces the grounding capacity.
Significance. This framework offers a valuable perspective for the HCI community by shifting focus from model capabilities to interactional factors like grounding and repair in LLM-enabled work. If the distinctions prove generalizable, it could guide the development of more robust collaborative systems and inform future empirical studies on human-AI partnerships.
major comments (2)
- [Methods] The description of the constructivist grounded theory analysis lacks specific details on participant selection, interview protocols, the coding process, and how theoretical saturation was achieved. This information is essential to assess the robustness of the derived framework and the claim that the three structures are recurrent.
- [Findings] The manuscript does not provide evidence, such as participant counts per structure or representative quotes, demonstrating that the three structures reliably appear across the sample. Without this, the assertion of 'recurrent structures' remains under-supported for a general claim about human-AI work.
minor comments (2)
- [Abstract] The abstract could benefit from a brief mention of the key literature informing the framework to better contextualize the contribution.
- [Discussion] Consider adding implications for design or future research directions to strengthen the practical impact of the framework.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the framework's potential contribution to HCI and for highlighting areas where additional transparency and evidence are needed. We agree that the poster format constrained the level of methodological detail and empirical illustration provided. Below we address each major comment and outline the revisions we will make.
read point-by-point responses
-
Referee: [Methods] The description of the constructivist grounded theory analysis lacks specific details on participant selection, interview protocols, the coding process, and how theoretical saturation was achieved. This information is essential to assess the robustness of the derived framework and the claim that the three structures are recurrent.
Authors: We accept this observation. The current poster version omitted these details due to length limits. In the revised manuscript we will add a dedicated methods subsection that specifies: (1) purposive sampling through HCI and AI practitioner networks with inclusion criteria focused on recent LLM tool use; (2) the semi-structured interview guide covering workflow, breakdowns, and repair strategies; (3) the constructivist coding process (initial line-by-line coding, focused coding, and memoing per Charmaz); and (4) the saturation criterion, which was reached after the 14th interview with the final two interviews confirming no new categories. These additions will allow readers to evaluate the analytic rigor. revision: yes
-
Referee: [Findings] The manuscript does not provide evidence, such as participant counts per structure or representative quotes, demonstrating that the three structures reliably appear across the sample. Without this, the assertion of 'recurrent structures' remains under-supported for a general claim about human-AI work.
Authors: We agree that the poster does not currently display the supporting evidence. In revision we will insert a summary table showing the distribution of the 16 participants across the three structures (with note that some participants exhibited elements of more than one) and will include one or two anonymized, representative quotes per structure drawn directly from the interview transcripts. This will make the recurrence claim empirically traceable while preserving participant confidentiality. revision: yes
Circularity Check
No circularity: qualitative framework derived from interviews and literature
full rationale
The paper presents a conceptual framework distinguishing three structures of human-AI work (one-shot assistance, weak collaboration with asymmetric repair, grounded collaboration) obtained via constructivist grounded theory from 16 interviews with designers, developers, and AI practitioners, plus literature review. No equations, quantitative derivations, parameter fitting, or predictions exist. No self-citations are load-bearing for the core distinctions, and the framework is not defined in terms of itself or renamed from prior results by the same authors. The derivation chain is self-contained against external benchmarks (interview data and cited literature) with no reduction by construction. Generalizability from the sample is a validity question, not circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The patterns identified in interviews with 16 practitioners reflect generalizable structures in human-AI collaboration.
invented entities (2)
-
Grounding capacity of the interaction
no independent evidence
-
Asymmetric repair in weak collaboration
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Bennett, Kori Inkpen, Jaime Teevan, Ruth Kikin-Gil, and Eric Horvitz
Guidelines for Human-AI Interaction. In: Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems . New York, NY, USA: Association for Computing Machinery . https://doi.org/10.1145/3290605.3300233 Bansal, Gagan, Tongshuang Wu, and Joyce Zhou
-
[2]
In: Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems
Does the Whole Exceed its Parts? The Effect of AI Explanations on Complementary Team Performance. In: Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems . New York, NY, USA: Association for Computing Machinery . https://doi.org/10.1145/3411764.3445088 Charmaz, Kathy . 2014.Constructing Grounded Theory . London, United Kingdom: SA...
-
[3]
The Collaboration Gap. arXiv preprint arXiv:2511.02687 . Eiband, Malin, Daniel Buschek, Heinrich Hussmann, and Alexander Butz
-
[4]
In: Proceedings of the 23rd International Conference on Intelligent User Interfaces, pp
Bringing Transparency Design into Practice. In: Proceedings of the 23rd International Conference on Intelligent User Interfaces, pp. 211–223. New York, NY, USA: Association for Computing Machinery . https://doi.org/10.1145/ 3172944.3172961 Fussell, Susan R. and Robert M. Krauss
-
[5]
Brockman, Nasir Memon, and Sameer Patil
Interpreting Interpretability: Understanding Data Scientists’ Use of Inter- pretability Tools for Machine Learning. In: Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems . New York, NY, USA: Association for Computing Machinery . https: //doi.org/10.1145/3313831.3376212 Kraut, Robert E., Darren Gergle, and Susan R. Fussell
-
[6]
In: Proceedings of the 2002 ACM Conference on Computer Supported Cooperative Work , pp
The Use of Visual Information in Shared Visual Spaces: Informing the Development of Virtual Co-Presence. In: Proceedings of the 2002 ACM Conference on Computer Supported Cooperative Work , pp. 31–40. New York, NY, USA: Association for Computing Machinery . Liao, Q. Vera, Daniel Gruen, and Sarah Miller
work page 2002
-
[7]
Vera Liao, Daniel Gruen, and Sarah Miller
Questioning the AI: Informing Design Practices for Explainable AI User Experiences. In: Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems. New York, NY, USA: Association for Computing Machinery . https://doi.org/ 10.1145/3313831.3376590 Poelitz, Christian, Finale Doshi-Velez, and Siân Lindley
-
[8]
arXiv preprint arXiv:2602.21337
A Benchmark to Assess Common Ground in Human–AI Collaboration. arXiv preprint arXiv:2602.21337 . Roschelle, Jeremy and Stephanie D. Teasley
-
[9]
Grounding Gaps in Language Model Generations. In: Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language T echnologies (Volume 1: Long Papers), pp. 6279–6296. Mexico City , Mexico: Association for Computational Linguistics. 6 Shneiderman, Ben
work page 2024
-
[10]
International Journal of Human–Computer Interaction 36, 1902–1911
Human-Centered Artificial Intelligence: Reliable, Safe & Trustworthy . In- ternational Journal of Human-Computer Interaction , 36 (6): 495–504. https: //doi.org/10.1080/ 10447318.2020.1741118 Traum, David
-
[11]
“To LLM, or Not to LLM?”: How Designers and Developers Navigate LLMs as Tools or Teammates. Extended Abstracts of the 2026 CHI Conference on Human Factors in Computing Systems . https: //doi.org/10.1145/3772363. 3798953 7
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.